La prueba de chi-cuadrado (C2) mide la alineación entre dos conjuntos de frecuencia
medidas. Estos deben ser recuentos categóricos y no porcentajes o
Medidas de proporciones (para estos, use otra
prueba de correlación).
Tenga en cuenta que los números de frecuencia deben ser significativos y ser al menos por encima de 5
(aunque una cifra inferior ocasional puede ser posible, siempre que no sean un
parte de un patrón de figuras bajas).
Un uso común es evaluar si sigue un conjunto de medidas medido/observado
un patrón esperado.
La frecuencia esperada puede determinarse a partir de conocimiento previo (como un
Resultados del examen del año anterior) o mediante el cálculo de un promedio de la dada
datos.
La hipótesis nula, H0 es que los dos conjuntos de medidas no son
significativamente diferente.
La prueba de chi-cuadrado se puede usar de manera inversa para la bondad del ajuste. Si
Se comparan los dos conjuntos de medidas, luego tal como puede mostrar que se alinean, usted
También puede determinar si no se alinean.
La hipótesis nula aquí es que los dos conjuntos de medidas son similares.
La principal diferencia en las evaluaciones de bondad de ajuste frente a la independencia está en el
Uso de la mesa cuadrada Chi. Por bondad de
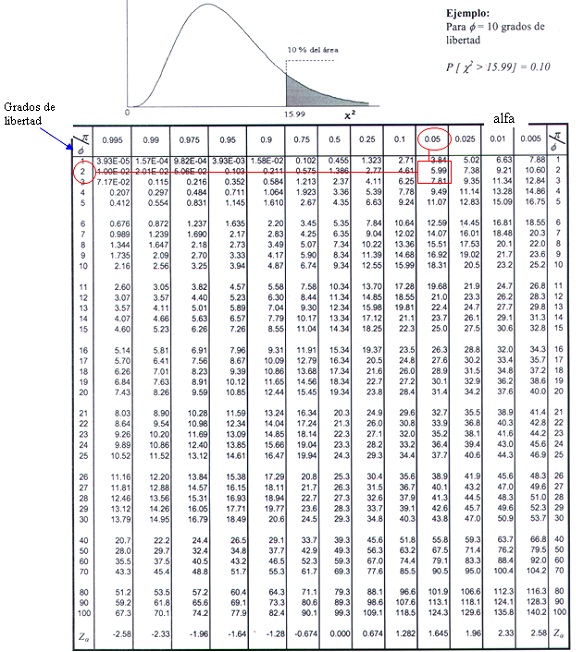
Ajuste, la atención es de 0.05, 0.01 o 0.001 cifras. Para la independencia, está en
0.95 o 0.99 cifras (es por eso que la tabla tiene dos extremos).
Chi-cuadrado, c2 = suma (
(observado – esperado) 2 / esperado)
… ¿Dónde está la frecuencia observada y Fe?
es la frecuencia esperada.
¿Cómo se calcula el grado de libertad?
Antes de adelantarnos, es importante abordar los grados de libertad. En estadísticas, los grados de libertad son el número de valores en el cálculo final que son libres de variar. En otras palabras, es la cantidad de formas o dimensiones que un valor independiente puede moverse sin violar las limitaciones.
Para calcular los grados de libertad, reste el número de relaciones del número de observaciones. Para determinar los grados de libertad para una media de muestra o promedio, debe restar uno (1) del número de observaciones, n.
Eche un vistazo a la imagen a continuación para ver los grados de la fórmula de la libertad.
Ahora que he explicado grados de libertad, veamos grados efectivos de libertad y la ecuación de aproximación Welch Satterthwaite.
Al realizar el análisis de incertidumbre, evalúa y combina múltiples componentes de incertidumbre caracterizados por diversas distribuciones de probabilidad. Por lo general, este complejo proceso hace que los grados de libertad sean inapropiados o indefinidos. Por lo tanto, debe calcular los grados de libertad efectivos o equivalentes, para fines de inferencia, para aproximar los grados de libertad reales.
Esto se logra utilizando la ecuación Welch Satterthwaite. Esencialmente, agrupa los grados de libertad para darle un promedio aproximado.
Eche un vistazo a la imagen a continuación para ver los grados efectivos de la fórmula de libertad.
Usando la ecuación dada anteriormente y la tabla que se muestra a continuación, puede ver cómo aplicar fácilmente la ecuación a sus cálculos de incertidumbre. Eche un vistazo a las cajas resaltadas. Cada caja se identifica por color y símbolo. Conecte los valores a la ecuación y calcule los grados efectivos de libertad.
¿Cómo se calculan los grados de libertad Excel?
Tomemos un ejemplo para comprender el cálculo de los grados de libertad de una mejor manera.
Tomemos el ejemplo de una muestra (conjunto de datos) con 8 valores con la condición de que la media del conjunto de datos debe ser 20. Entonces el grado de libertad de la muestra puede derivarse como,
- Grados de libertad = 8 – 1
- Grados de libertad = 7
Explicación: Si los siguientes valores para el conjunto de datos se seleccionan al azar, 8, 25, 35, 17, 15, 22, 9, entonces el último valor del conjunto de datos no puede ser nada más que = 20 * 8 – (8 + 25 + 35 + 17 + 15 + 22 + 9) = 29
- Grados de libertad = 8 – 1
- Grados de libertad = 7
Tomemos el ejemplo de una prueba de chi-cuadrado simple (tabla bidireccional) con una tabla 2 × 2 con una suma respectiva para cada fila y columna. Calcule su grado de libertad.
En lo anterior, se puede ver que solo hay un valor en negro que es independiente y debe estimarse. Una vez que se estima ese valor, los tres valores restantes se pueden derivar fácilmente en función de las restricciones. Por lo tanto,
- Grados de libertad = 8 – 1
- Grados de libertad = 7
Tomemos el ejemplo de una prueba de chi-cuadrado (tabla bidireccional) con 5 filas y 4 columnas con la suma respectiva para cada fila y columna. Calcule el grado de libertad para la tabla de prueba de chi-cuadrado.
¿Cómo se calcula los grados de libertad de la distribución t Student?
Como hemos visto, cuando se formula una hipótesis en el promedio de una población, los grados de libertad son GDL = N-1.
En el caso de varianza, la fórmula de este parámetro se basa en el desperdicio de las observaciones individuales del promedio. Y, por definición, la suma de todos los desechos es igual a 0. Por lo tanto, si conoce los desechos N-1 del promedio, el último puede obtenerse como una diferencia entre el valor alcanzado por el resumen de los desechos y cero. Esta es la razón por la cual, en el cálculo de la varianza de la muestra, se divide por N-1 y no por n.
Realizar una prueba t para muestras aparecidas es equivalente en la práctica para llevar a cabo una sola prueba t de muestra. Porque lo que se hace en las muestras aparecidas es crear una nueva diferencia variable de las dos columnas con los datos que han aparecido. Y luego el promedio de muestra de esta nueva variable se compara con un valor de referencia de 0.
Por lo tanto, esta situación cae en el caso del cálculo de los grados de libertad relacionados con la estimación de un promedio. Por lo tanto, tanto en la prueba t de prueba t y TS TS TS para muestras aparecieron, los grados de libertad serán iguales a GDL = N-1.
Por ejemplo, si desea comparar el promedio de una variable (por ejemplo, frecuencia respiratoria) detectada antes y después de un cierto tratamiento (por ejemplo, una sesión de entrenamiento) en una muestra de 28 individuos, los grados de libertad serán iguales a GDL = 28 – 28 – 1 = 27.
En el caso de la comparación entre los promedios de dos muestras independientes, si la varianza de los dos grupos es homogénea, los grados de libertades que se utilizan para la distribución t del estudiante están dadas por el número total de observaciones (N1 + N2 ) menos I Parámetros utilizados para obtener la estimación de la desviación estándar.
¿Cuántos grados de libertad se espera que tenga la distribución chi?
- La hipótesis nula (H0 :) es que no hay asociación entre el grupo de riesgo de transmisión del VIH y la divulgación, es decir, la frecuencia de divulgación no difiere entre los grupos de riesgo de transmisión del VIH.
- La hipótesis alternativa (ha :) es que existe una asociación entre el grupo de riesgo de transmisión del VIH y la frecuencia de divulgación, es decir, que la frecuencia de divulgación difiere entre los grupos de riesgo de transmisión del VIH.
Tenga en cuenta que la frecuencia de divulgación general fue 77/127 = 60.6%, por lo que la hipótesis nula predeciría que la frecuencia de divulgación sería del 60,6% para los tres modos de transmisión. Este no era el caso; La frecuencia de divulgación varió del 52% al 67%. ¿Qué tan diferentes son estas frecuencias de lo que hubiéramos esperado bajo la hipótesis nula (H0 :)? ¿Podría la variabilidad haber resultado del error de muestreo?
La prueba de chi-cuadrado ayuda a responder esta pregunta calculando una estadística de prueba (x2) en función de las diferencias entre las frecuencias observadas en cada célula en comparación con las frecuencias esperadas bajo la hipótesis nula. La ecuación de chi-cuadrado es:
Donde «O» es el recuento observado para cada categoría de exposición-resultado, «E» es el recuento esperado para cada categoría de exposición-resultado basada en la hipótesis nula y los grados de libertad (DF) = (R-1) x ( C-1), es decir, el número de filas (categorías de exposición) menos una vez el número de columnas (categorías de resultados) menos una en la tabla de contingencia.
¿Cuántos grados de libertad chi cuadrado?
La distribución de chi-cuadrado se usa comúnmente para medir qué tan bien una distribución observada se adapta a una teórica. Esta medición se cuantifica utilizando grados de libertad. En el contexto de los intervalos de confianza, podemos medir la diferencia entre una desviación estándar de población y una desviación estándar de muestra utilizando la distribución de chi-cuadrado.
En pocas palabras, la distribución de chi-cuadrado modela la distribución de la suma de cuadrados de varias variables aleatorias normales estándar independientes.
Por lo tanto, puede llegar a la forma más simple de la distribución de chi-cuadrado de una variable aleatoria normal estándar X simplemente cuadrando X.
Q_1 = x^2
Como puede ver, la curva disminuye rápidamente a casi cero a medida que aumenta Q. Los valores Q de nuestra distribución aquí son básicamente al azar cuadrado que se basa en una distribución normal estándar. Dado que la distribución normal estándar tiene una media de cero, la mayoría de los sorteos estarán cerca de cero. Si cuadra un número <1, se vuelve aún más pequeño. Los dibujos de valores más grandes son cada vez más improbables. Cuadrando el valor también tiene el efecto de que todos los valores serán positivos.
Podemos construir una distribución de chi-cuadrado con un número arbitrario de k variables aleatorias.
Q_k = x_1^2 +x_2^2 +... +x_k^2
El número de variables aleatorias independientes que van a la distribución de chi-cuadrado se conoce como grados de libertad (DF). No hay una definición clara de grados de libertad. Pero como su nombre lo indica, puede pensar que es el número de variables que pueden variar. Cuantas más variables agregue, más variabilidad introducirá y, por lo tanto, más grados de libertad tiene.
¿Que nos permite calcular la distribución de chi cuadrada?
Chi Square tal vez sesgado a la derecha o con una cola larga hacia los grandes valores de la distribución. La forma general de la distribución dependerá del número de grados de libertad en un problema dado. Los grados de libertad son 1 menos que el tamaño de la muestra.
- La media de la distribución es igual al número de grados de libertad: μ = ϑ.
- La varianza es igual a dos veces el número de grados de libertad: σ2 = 2*ϑ.
- Cuando los grados de libertad son mayores o iguales a 2, el valor máximo para y ocurre cuando χ2 = ϑ-2.
- A medida que aumentan los grados de libertad, la curva Chi Square se acerca a una distribución normal.
- A medida que aumentan los grados de libertad, la simetría del gráfico también aumenta.
- Finalmente, puede estar sesgado a la derecha, y dado que la variable aleatoria en la que se basa se cuadra, no tiene valores negativos. A medida que aumenta los grados de libertad, la función de densidad de probabilidad comienza a parecer de forma simétrica.
La fórmula para el
La función de densidad de probabilidad de la distribución de chi cuadrado es
Donde ϑ el
El parámetro de forma y γ es la función gamma.
Por lo general, el objetivo del equipo Six Sigma es encontrar el nivel de variación de la producción, no solo la media de la población. Lo más importante, al equipo le gustaría saber cuánta variación exhibe el proceso de producción sobre el objetivo para ver qué ajustes se necesitan para alcanzar un proceso sin defectos.
¿Qué es el Chi cuadrado y cómo se interpreta?
La prueba de independencia de chi-cuadrado determina si existe una relación estadísticamente significativa entre las variables categóricas. Es una prueba de hipótesis que responde a la pregunta: ¿los valores de una variable categórica dependen del valor de otras variables categóricas? Esta prueba también se conoce como la prueba de asociación de chi-cuadrado.
Como sin duda adivinaste, soy un gran admirador de las estadísticas. También soy un gran fanático de Star Trek. En consecuencia, ¡no es sorprendente que esté escribiendo una publicación de blog sobre ambos! En la serie de televisión Star Trek, el Capitán Kirk y la tripulación usan uniformes de diferentes colores para identificar el área de trabajo del miembro de la tripulación. Aquellos que usan camisas rojas tienen la desafortunada reputación de morir con más frecuencia que aquellos que usan camisas doradas o azules.
En esta publicación, le mostraré cómo funciona la prueba de independencia de Chi-Square. Luego, le mostraré cómo realizar el análisis e interpretar los resultados trabajando a través del ejemplo. ¡Usaré esta prueba para determinar si usar la temida camisa roja en Star Trek es el beso de la muerte!
- Hipótesis nula: no hay relaciones entre las variables categóricas. Si conoce el valor de una variable, no lo ayuda a predecir el valor de otra variable.
- Hipótesis alternativa: hay relaciones entre las variables categóricas. Conocer el valor de una variable lo ayuda a predecir el valor de otra variable.
La prueba de asociación de chi-cuadrado funciona comparando la distribución que observa con la distribución que espera si no hay relación entre las variables categóricas. En el contexto de chi-cuadrado, la palabra «esperada» es equivalente a lo que esperaría si la hipótesis nula es cierta. Si su distribución observada es suficientemente diferente a la distribución esperada (sin relación), puede rechazar la hipótesis nula e inferir que las variables están relacionadas.
¿Qué es la prueba de chi cuadrado y cuando se utiliza?
En las aplicaciones estándar de esta prueba, las observaciones se clasifican en clases mutuamente excluyentes. Si la hipótesis nula de que no hay diferencias entre las clases en la población es cierto, la estadística de prueba calculada a partir de las observaciones sigue una distribución χ2Frequency. El propósito de la prueba es evaluar qué tan probable es que las frecuencias observadas asuman que la hipótesis nula es cierta.
Las estadísticas de prueba que siguen una distribución de χ2 se producen cuando las observaciones son independientes. También hay pruebas de χ2 para probar la hipótesis nula de la independencia de un par de variables aleatorias basadas en observaciones de los pares.
Las pruebas de chi cuadrado a menudo se refieren a pruebas para las cuales la distribución de la estadística de prueba se acerca a la distribución χ2 asintóticamente, lo que significa que la distribución de muestreo (si la hipótesis nula es cierta) de la estadística de prueba se aproxima a una distribución de chi cuadrado cada vez más cerca Los tamaños de muestra aumentan.
A finales del siglo XIX, Pearson notó la existencia de asimetría significativa dentro de algunas observaciones biológicas. Para modelar las observaciones, independientemente de ser normal o sesgada, Pearson, en una serie de artículos publicados de 1893 a 1916, [2] [3] [4] [5] ideó la distribución de Pearson, una familia de distribuciones de probabilidad continua, que incluye la distribución normal y muchas distribuciones sesgadas, y propuso un método de análisis estadístico que consiste en usar la distribución de Pearson para modelar la observación y realizar una prueba de bondad de ajuste para determinar qué tan bien se ajusta el modelo realmente a las observaciones.
Artículos Relacionados:

