Un plan de recopilación de datos es solo eso: un plan de cómo la información que su programa espera recopilar fluya desde su fuente hasta las ideas procesables que espera obtener de ella. El proceso de desarrollo de este plan revelará cosas sobre de dónde provienen sus datos, quién tiene acceso a él y cómo se recopila y almacena, todo lo cual es una información clave que informará el diseño e implementación de cualquier sistema nuevo usted. elegir.
Gillian Javetski, COO y cofundador de Tecsalud, una compañía ICT4D en Bogotá y Cambridge, explica: “Cuando tienes que mapear tu proyecto desde el cuadrado uno, te abre los ojos a los huecos que no vio antes y esa tecnología May May no poder arreglar. De repente, la conversación puede cambiar de «¿Qué queremos que haga esta tecnología» para «esperar, en realidad, es el problema en nuestro flujo de trabajo?»
Una vez que haya aclarado los objetivos de su proyecto, haya tomado un stock de sus requisitos de datos y haya determinado el método de recopilación de datos que espera emplear, es hora de armar todas las piezas.
Los programas de recopilación de datos pueden ser una interacción compleja de fuentes de datos y técnicas de recopilación
Existen dos métodos principales para organizar un plan de recopilación de datos que típicamente usamos. Uno es más visual y mapea el flujo de información específica para ese programa. El otro es más analítico, aplicando un conjunto estándar de criterios al proceso para que pueda completar una manera que tenga sentido para su programa. Cada uno tiene sus fortalezas y debilidades, pero comparten el objetivo de documentar su plan de recopilación de datos de una manera que se pueda compartir, analizar y mejorar.
¿Cómo se pueden organizar los datos?
La buena organización de archivos y carpetas lo ayudará a localizar, identificar y recuperar sus datos de manera rápida y precisa, lo que facilita la administración de sus datos. Para hacer esto, necesitas:
- Use carpetas para resolver sus archivos en una serie de grupos significativos y útiles
- Use convenciones de nombres para dar a sus archivos y carpetas nombres significativos de acuerdo con un patrón consistente
Debe establecer un esquema de organización de archivos al comienzo de cada proyecto para evitar tener que resolver sus archivos retrospectivamente:
- Use carpetas para resolver sus archivos en una serie de grupos significativos y útiles
- Use convenciones de nombres para dar a sus archivos y carpetas nombres significativos de acuerdo con un patrón consistente
Documente su esquema de organización de archivos en un archivo ‘Readme’, preferiblemente en texto sin formato, y guárdelo en la carpeta de nivel superior para su proyecto donde usted (o cualquier persona en su grupo) pueda acceder a él fácilmente.
¿Cómo ordenar los datos agrupados?
Una hoja de cálculo de Microsoft Excel puede contener una gran cantidad de información. A veces puede encontrar que necesita reordenar o ordenar esa información, crear grupos o filtrar información para poder usarla de manera más efectiva.
La clasificación de listas es una tarea de hoja de cálculo común que le permite reordenar fácilmente sus datos. El tipo de clasificación más común es el orden alfabético, que puede hacer en orden ascendente o descendente.
- Seleccione una celda en la columna que desea ordenar (en este ejemplo, elegimos una celda en la columna A).
- Haga clic en el comando Sort y Filtro en el grupo de edición en la pestaña Inicio.
- Seleccione el orden A a Z. Ahora la información en la columna de categoría se organiza en orden alfabético.
Puede ordenar en orden alfabético inversa eligiendo la ordenación Z a A en la lista.
- Seleccione una celda en la columna que desea ordenar (en este ejemplo, elegimos una celda en la columna A).
- Haga clic en el comando Sort y Filtro en el grupo de edición en la pestaña Inicio.
- Seleccione el orden A a Z. Ahora la información en la columna de categoría se organiza en orden alfabético.
Puede ordenar en orden numérico inverso eligiendo de más grande a más pequeño en la lista.
- Seleccione una celda en la columna que desea ordenar (en este ejemplo, elegimos una celda en la columna A).
- Haga clic en el comando Sort y Filtro en el grupo de edición en la pestaña Inicio.
- Seleccione el orden A a Z. Ahora la información en la columna de categoría se organiza en orden alfabético.
¿Cómo se ordenan los datos agrupados?
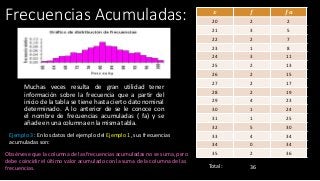
Para presentar una cantidad tan grande de datos lo condensamos en grupos como 10-20, 20-30,… 60-70 (ya que nuestros datos son de 19 a 69).
Los grupos 10-20, 20-30, 30-40, 40-50, 50-60 se denominan clases o intervalos de clase.
En la clase 10-20, el número 10 (menos número) se llama límite de clase inferior y 20 el (mayor número) se llama límite de clase alta.
En cualquier intervalo de clase, la diferencia entre el límite superior y el límite inferior se denomina tamaño de clase o ancho de clase.
Por ejemplo, en 10-20, 10 es el límite de clase inferior y 20 es el límite de clase alta.
Los datos anteriores se pueden representar en forma tabular de la siguiente manera:
Al agregar los límites de clase superior e inferior y dividir la suma por 2, obtenemos una marca de clase de la clase.
Por lo tanto, la marca de clase de 10-20 es (10 + 20)/2 = 15.5
Los datos que presentan en esta forma se simplifican y se condensan y nos permiten observar algunas características importantes de un vistazo.
Esto se llama tabla de distribución de frecuencia agrupada.
Aquí podemos observar fácilmente que el peso de 12 estudiantes es de 31 a 35 kg.
También observamos que en la tabla anterior las clases no se superponen.
No hay ninguna regla difícil y rápida sobre esto, excepto que las clases no deben superponerse.
Hemos hecho más clases de tamaño más corto, o menos clases de mayor tamaño.
Por ejemplo, los intervalos podrían haber sido 21-23, 24-26, y así sucesivamente.
Ahora, si dos nuevos estudiantes admitieron en la clase de pesas 25.5 kg y 30.5 kg, por lo que aquí no está claro en qué intervalo de clase los incluiremos.
¿Cómo ordenar los datos en estadistica?
Las estadísticas de pedido son un concepto muy útil en ciencias estadísticas. Tienen una amplia gama de aplicaciones que incluyen subastas de modelado, carreras de automóviles y pólizas de seguro, optimizando los procesos de producción, estimando los parámetros de las distribuciones, et al. A través de este artículo, comprenderemos la idea de las estadísticas de pedidos. Primero entenderemos su significado y procederemos gradualmente a su distribución, eventualmente cubriendo conceptos más avanzados.
Supongamos que tenemos un conjunto de variables aleatorias x1, x2,…, xn, que son independientes e idénticamente distribuidas (i.i.d). Por independencia, queremos decir que el valor tomado por una variable aleatoria no está influenciado por los valores tomados por otras variables aleatorias. Mediante una distribución idéntica, queremos decir que la función de densidad de probabilidad (PDF) (o de manera equivalente, la función de distribución acumulativa, CDF) para las variables aleatorias es la misma. La estadística de orden KTH para este conjunto de variables aleatorias se define como el valor más pequeño de la muestra.
Para comprender mejor este concepto, tomaremos 5 variables aleatorias x1, x2, x3, x4, x5. Observaremos una realización/resultado aleatorio de la distribución de cada una de estas variables aleatorias. Supongamos que obtenemos los siguientes valores:
La estadística de orden KTH para este experimento es el valor más pequeño del conjunto {4, 2, 7, 11, 5}. Entonces, la estadística de primer orden es 2 (valor más pequeño), la estadística de segundo orden es 4 (siguiente más pequeño), y así sucesivamente. La estadística de quinto orden es el quinto valor más pequeño (el valor más grande), que es 11. Repetimos este proceso muchas veces, es decir, extraemos muestras de la distribución de cada una de estas variables aleatorias i.i.d, y encontramos el valor más pequeño para cada conjunto de observaciones. La distribución de probabilidad de estos valores proporciona la distribución de las estadísticas de orden KTH.
En general, si organizamos variables aleatorias x1, x2,…, xn en orden ascendente, entonces la estadística de orden de KTH se muestra como:
La notación general de la estadística de orden KTH es x (k). La nota X (k) es diferente de XK. XK es la variable aleatoria KTH de nuestro conjunto, mientras que X (k) es la estadística de orden KTH de nuestro conjunto. X (k) toma el valor de XK si XK es la variable aleatoria KTH cuando las realizaciones se organizan en orden ascendente.
¿Cómo se organizan y presentan los datos estadísticos?
Índices de posición
Los índices de posición como el promedio, la mediana y la moda definen algunos valores numéricos alrededor de los cuales se centran las observaciones X1,…, xn de una estadística variable fija X.
Las muestras de los n datos x1,…, xn (respuestas de datos agrupados en K clases de valor central M1,…, MK) El siguiente tamaño se define como la muestra.
La mediana M de los n Datos X1,…, xn ordenado de manera creciente corresponde al siguiente valor:
La moda m de los n datos x1,…, xnè el valor o clase al que corresponde la frecuencia absoluta máxima.
El promedio involucra todas las observaciones, por lo tanto, está influenciada por valores extremos (Min y Max).
Por el contrario, la mediana depende solo de uno o dos valores en el centro de la distribución y, por lo tanto, no sufre valores extremos. La moda, generalmente utilizada para datos no numéricos, puede no existir o no ser única.
Ejemplo 4.4: Calcule la promedio, mediana y la moda del siguiente conjunto de datos:
El promedio de los datos N = 12 es 5, la mediana sigue siendo 5, donde el total tiene dos modas: 3 y 7.
Además de la mediana que se divide en la mitad de un conjunto de datos ordenados, se pueden definir otros índices de posición: las cuantales que dividen el conjunto ordenado de datos en un número asignado de partes iguales. Estos índices de posición se utilizan sobre todo en presencia de un conjunto muy grande de datos.
- Se ordenan los n datos x1,…, xn de una manera en crecimiento.
- Se calcula el producto K = NP, donde P representa la fracción de datos menores o igual a la cuántica a calcular. Por ejemplo, para calcular Q1 tendrá que colocar p = 0.25.
Artículos Relacionados:

