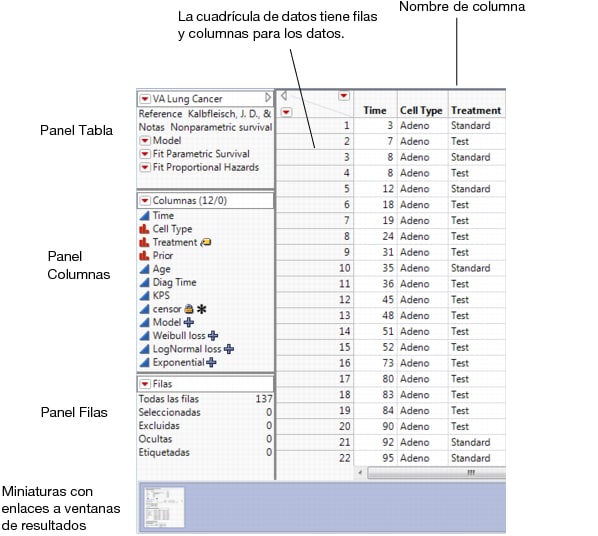
Tabulación significa la presentación sistemática de la información contenida en los datos, en filas y columnas de acuerdo con algunas características o características sobresalientes. Las filas son arreglos horizontales y las columnas son arreglos verticales.
Una tabla estadística es la lista lógica de datos cuantitativos relacionados en columnas verticales y filas horizontales de números con suficientes palabras explicativas y calificadas, frases y declaraciones en forma de títulos, encabezados y notas para aclarar el significado completo de los datos y sus datos y sus origen.
Ahora enumeramos algunas de las características que cualquier buena tabla debe tener:
- La tabla debe ser corta, al grano y fácil de entender. No debe haber margen para las ambigüedades en la mesa.
- La tabla debe dibujarse de tal manera que sea fácil hacer comparaciones y analizar los datos. La relación entre los dos o más factores debería ser fácil visible. Algunos puntos/valores especiales se pueden enfatizar utilizando letras en negrita/cursiva.
- La tabla debe tener un título claro y varios subtítulos y subtítulos. El lector debe poder comprender la información presentada de un vistazo. También se debe proporcionar la fuente de los datos en la tabla, de modo que el lector pueda verificar y hacer referencia a los datos.
- La tabla debe tener un tamaño apropiado y mirar visualmente atractivos. El lector debe poder leer los datos fácilmente sin hacer ningún esfuerzo especial.
- La tabla no debe contener ningún error. Al transcribir los datos a la tabla, se debe tener cuidado de que no hay errores inadvertidos. Esto es muy importante porque la conclusión estadística se realiza sobre la base de los datos presentados en la tabla. Por lo tanto, los datos en la tabla deben ser precisos y libres de errores.
- Los datos en la tabla deben presentarse sistemáticamente. Por ejemplo, los datos de la serie temporal se pueden presentar cronológicamente. Si no hay precedencia entre los diferentes factores en la tabla, los datos simplemente pueden presentarse en orden alfabético.
- Si la tabla está resumiendo un conjunto de datos más grande, entonces debe contener las medidas estadísticas comunes como media, mediana, modo, varianza, asimetría, curtosis, etc.
- Ejemplo de una buena tabla en estadísticas
¿Cuáles son las características de las tablas de datos?
Los datos se almacenan en tablas en una base de datos. Se puede almacenar en una sola tabla (llamada base de datos plana, como se muestra en la Figura 2.1) o en múltiples tablas conectadas (llamada base de datos relacional, como se muestra en la Figura 2.2).
Campo: un solo bit de información sobre una persona o un elemento, por ejemplo, edad
Registro: un grupo de campos relacionados sobre un artículo o persona que se captura en la mesa
Clave principal: un campo que contiene un identificador único para cada registro en la base de datos (único significa que solo hay uno de su tipo)
Cada tabla consta de campos y registros. Los campos son las categorías para las que desea grabar datos. Por ejemplo, la tabla de música que se muestra arriba, contiene campos como el título, el artista, la duración y el álbum. Los registros se refieren a los datos reales que se capturan, con cada registro que contiene los datos de un solo elemento. Por ejemplo, en la tabla de canciones, cada disco representa una sola canción, con toda la información (como el artista y la duración) relacionada con esa canción.
Cada tabla puede tener un campo obligatorio, llamado clave primaria, que contiene un identificador único para cada registro en la base de datos. Esto le permite referirse a un registro específico en una tabla de tal manera que solo podría referirse a una entrada. Si bien es posible hacer que un campo existente de una tabla sea un campo clave, los creadores de bases de datos generalmente crean un nuevo campo específicamente para este propósito. Esto les permite asegurarse de que no haya duplicados.
A veces hay anomalías con bases de datos, aprenderá cómo deshacerse de estas anomalías.
¿Cuáles son los elementos de una tabla en una base de datos?
Las tablas son conjuntos de elementos de datos (valores) en bases de datos relacionales y bases de datos de archivos planos. Están compuestos de columnas verticales (identificables por nombre) y filas horizontales, siendo la celda la unidad donde las columnas se cruzan.
Un entorno de base de datos debe estar compuesto por cuatro elementos críticos: (1) administración de datos, (2) planificación y modelado de datos, (3) tecnología y administración de bases de datos, y (4) usuarios. La Figura 7-18 muestra el entorno en el que se encuentra esto.
Un entorno de base de datos consta de cuatro elementos principales. Los usuarios, el sistema de administración de bases de datos, el administrador de la base de datos y las estructuras de base de datos físicas se incluyen en la base de datos.
- Es el esquema de la base de datos.
- Hay objetos de esquema en el mundo.
- Índices.
- Mesas.
- Hay campos y columnas en el documento.
- Los registros y las filas de datos.
- Llaves.
- Las relaciones son importantes.
La estructura de datos de una organización es el elemento fundamental de su procesamiento de datos. Un elemento de datos es cualquier unidad de datos definida para el procesamiento, como un número de cuenta, un nombre, una dirección o una ciudad. Además del tamaño (en caracteres), tipo (alfanumérico, solo numérico, verdadero/falso, fecha) y fecha, los elementos de datos también se definen.
¿Qué características debe tener una tabla de frecuencias?
Las tablas de frecuencia pueden ser útiles para describir el número de ocurrencias de un tipo particular de dato dentro de un conjunto de datos. Las tablas de frecuencia, también llamadas distribuciones de frecuencia, son una de las herramientas más básicas para mostrar estadísticas descriptivas. Las tablas de frecuencia se utilizan ampliamente como una referencia AT-A-Glance en la distribución de datos; Son fáciles de interpretar y pueden mostrar grandes conjuntos de datos de manera bastante concisa. Las tablas de frecuencia pueden ayudar a identificar tendencias obvias dentro de un conjunto de datos y pueden usarse para comparar datos entre conjuntos de datos del mismo tipo. Sin embargo, las tablas de frecuencia no son apropiadas para cada aplicación. Pueden oscurecer valores extremos (más de x o menos que Y), y no se prestan a los análisis de la sesgo y la curtosis de los datos.
Las tablas de frecuencia pueden revelar rápidamente valores atípicos e incluso tendencias significativas dentro de un conjunto de datos con no mucho más que una inspección superficial. Por ejemplo, un maestro podría mostrar las calificaciones de los estudiantes para un medio plazo en una tabla de frecuencia para ver rápidamente cómo está su clase en general. El número en la columna de frecuencia representaría el número de estudiantes que reciben esa calificación; Para una clase de 25 estudiantes, la distribución de frecuencia de las calificaciones de cartas recibidas podría verse algo así: Frecuencia de grado A………….. 7 B……….. ..13 C………….. 3 D………….. 2
Las tablas de frecuencia pueden ayudar a los investigadores a examinar la abundancia relativa de cada datos objetivo en particular dentro de su muestra. La abundancia relativa representa cuánto del conjunto de datos se compone de los datos objetivo. La abundancia relativa a menudo se representa como un histograma de frecuencia, pero se puede mostrar fácilmente en una tabla de frecuencia. Considere la misma distribución de frecuencia de los grados de mitad de período. La abundancia relativa es simplemente el porcentaje de los estudiantes que obtuvieron una calificación en particular y puede ser útil para conceptualizar datos sin pensarlo demasiado. Por ejemplo, con la columna adicional que muestra el porcentaje de ocurrencia de cada grado, puede ver fácilmente que más de la mitad de la clase obtuvo una B, sin tener que analizar los datos con mucho detalle.
Una desventaja es que es difícil comprender conjuntos de datos complejos que se muestran en una tabla de frecuencia. Los conjuntos de datos grandes se pueden dividir en clases de intervalos para una fácil visualización utilizando una tabla de frecuencia. Por ejemplo, si le preguntó a las siguientes 100 personas que ves cuál era su edad, es probable que obtengas una amplia gama de respuestas que abarcan entre tres y noventa y tres. En lugar de incluir filas para cada edad en su tabla de frecuencia, puede clasificar los datos en intervalos, como 0 – 10 años, 11-20 años, 21-30 años, etc. Esto también puede referirse como una distribución de frecuencia agrupada.
¿Qué características tiene la tabla de frecuencias de datos agrupados?
La tabla de frecuencia agrupada es un método estadístico para organizar y simplificar un gran conjunto de datos en «grupos» más pequeños. Cuando un datos consta de cientos de valores, es preferible agruparlos en una parte más pequeña para que sea más comprensible. Cuando se crea la tabla de frecuencia agrupada, los científicos y estadísticos pueden observar tendencias interesantes en los datos.
El objetivo principal de la tabla de frecuencia agrupada es averiguar con qué frecuencia ocurrió cada valor dentro de cada grupo de los datos completos. La distribución de frecuencia de grupo es esencialmente una tabla con dos columnas. La primera columna titulada «Grupos» representa toda la «agrupación» posible de los datos y la segunda columna titulada «frecuencia» representa cómo se produce cada valor en cada grupo.
Recopile los datos escribiéndolo en una hoja de papel. Por ejemplo, digamos que tenemos datos que consisten en seguir 12 valores: 16, 17, 18, 19, 10, 11, 13, 14, 17, 11, 12 y 15.
Reorganice los datos para que comience con el número más pequeño y termine con el número más alto. En este ejemplo, estos datos se reorganizarán de la siguiente manera: 10,11,11,12,13,14,15,16,17,17,18 y 19.
Encuentre el valor más alto y más bajo y deduca el valor más bajo del valor más alto. En este ejemplo, deduciremos el valor más bajo de «10» del valor más alto de «19». El resultado es 19-10 = 9.
Determinar el número de grupos. La mayoría de los datos tienen entre cinco y 10 grupos. Es su decisión elegir el número de grupos para sus datos. En este ejemplo, dado que solo tenemos 12 valores, elegiremos un total de cinco grupos.
¿Qué es una frecuencia y sus características?
Cualquier característica pronunciada (a saber, picos o picos) con diferentes fortalezas (es decir, la amplitud relativa de cada característica en comparación con el fondo) en un espectro de frecuencia se conoce como frecuencia característica.
La frecuencia característica también podría referirse a la frecuencia resonante de un sistema, ya que está expuesto a un espectro de frecuencias de entrada. Por ejemplo, considere un sistema de masa de resorte amortiguado.
Si uno midiera la amplitud de la oscilación de la masa versus la frecuencia de alguna fuerza impulsora, obtendría un espectro que tendría un pico en el espectro cuya forma y ubicación máxima dependerían de la cantidad de amortiguación. Ese pico sería la frecuencia característica.
Otro ejemplo sería medir la impedencia de entrada de aire de un instrumento de viento musical en función de la frecuencia de pulso (o el espectro de Fourier de entrada de ruido blanco en el instrumento). El resultado será un espectro con picos de frecuencias resonantes. Esas serían las frecuencias características del instrumento.
El término frecuencia característica o longitud de onda característica es una representación del lenguaje de un espectro particular
Si el espectro tiene una característica que lo «identifica» en un conglomerado de tantos o puede usarse como una herramienta /marcador comparativo en el grupo, la frecuencia característica llamada del espectro del material de Say A.
Como ejemplo, escuché este término cuando miraba el espectro de rayos X de ciertos materiales objetivo como cobre, molibdeno… etc.
Artículos Relacionados:

