El muestreo es el proceso estadístico de seleccionar un subconjunto (llamado «muestra») de una población de interés a los efectos de hacer observaciones e inferencias estadísticas sobre esa población. La investigación en ciencias sociales generalmente se trata de inferir patrones de comportamientos dentro de poblaciones específicas. No podemos estudiar poblaciones enteras debido a restricciones de viabilidad y costos, y por lo tanto, debemos seleccionar una muestra representativa de la población de interés para la observación y el análisis. Es extremadamente importante elegir una muestra que sea verdaderamente representativa de la población para que las inferencias derivadas de la muestra puedan generalizarse a la población de interés. El muestreo inadecuado y sesgado es la razón principal de las inferencias a menudo divergentes y erróneas reportadas en las encuestas de opinión y las encuestas de salida realizadas por diferentes grupos de votación como CNN/Gallup Poll, ABC y CBS, antes de todas las elecciones presidenciales de los Estados Unidos.
El proceso de muestreo comprende varias etapas. La primera etapa es definir la población objetivo. Una población puede definirse como todas las personas o elementos (unidad de análisis) con las características que uno desea estudiar. La unidad de análisis puede ser una persona, grupo, organización, país, objeto o cualquier otra entidad sobre la que desee dibujar inferencias científicas. A veces la población es obvia. Por ejemplo, si un fabricante desea determinar si los productos terminados fabricados en una línea de producción cumplen con ciertos requisitos de calidad o deben ser descartados y reelaborados, entonces la población consiste en todo el conjunto de productos terminados fabricados en esa instalación de producción. En otras ocasiones, la población objetivo puede ser un poco más difícil de entender. Si desea identificar los principales impulsores del aprendizaje académico entre los estudiantes de secundaria, ¿cuál es su población objetivo: estudiantes de secundaria, sus maestros, directores de escuelas o padres? La respuesta correcta en este caso es estudiantes de secundaria, porque está interesado en su desempeño, no en el desempeño de sus maestros, padres o escuelas. Del mismo modo, si desea analizar el comportamiento de las ruedas de la ruleta para identificar las ruedas sesgadas, su población de interés no son observaciones diferentes de una sola rueda de ruleta, sino diferentes ruedas de ruleta (es decir, su comportamiento sobre un conjunto infinito de ruedas).
El segundo paso en el proceso de muestreo es elegir un marco de muestreo. Esta es una sección accesible de la población objetivo (generalmente una lista con información de contacto) desde donde se puede extraer una muestra. Si su población objetivo es empleados profesionales en el trabajo, debido a que no puede acceder a todos los empleados profesionales de todo el mundo, un marco de muestreo más realista serán listas de empleados de una o dos compañías locales que estén dispuestas a participar en su estudio. Si su población objetivo es organizaciones, entonces la lista de empresas Fortune 500 o la lista de empresas de Standard & Poor’s (S&P) registradas en la Bolsa de Nueva York puede ser marcos de muestreo aceptables.
Tenga en cuenta que los marcos de muestreo pueden no ser completamente representativos de la población en general, y de ser así, las inferencias derivadas de dicha muestra pueden no ser generalizables para la población. Por ejemplo, si su población objetivo es empleados de organización en general (por ejemplo, desea estudiar la autoestima de los empleados en esta población) y su marco de muestreo es empleados de las empresas automotrices en el medio oeste estadounidense, los hallazgos de tales grupos pueden no ser generalizables a la fuerza laboral estadounidense en general, y mucho menos en el lugar de trabajo global. Esto se debe a que la industria automotriz estadounidense ha estado bajo severas presiones competitivas durante los últimos 50 años y ha visto numerosos episodios de reorganización y reducción de personal, posiblemente resultando en una baja moral y autoestima de los empleados. Además, la mayoría de la fuerza laboral estadounidense se emplea en industrias de servicios o en pequeñas empresas, y no en la industria automotriz. Por lo tanto, una muestra de empleados de la industria automotriz estadounidense no es particularmente representativa de la fuerza laboral estadounidense. Del mismo modo, la lista Fortune 500 incluye las 500 empresas estadounidenses más grandes, que no es representativa de todas las empresas estadounidenses en general, la mayoría de las cuales son empresas medianas y pequeñas en lugar de grandes empresas, y por lo tanto es un marco de muestreo sesgado. Por el contrario, la lista de S&P le permitirá seleccionar empresas grandes, medianas y/o pequeñas, dependiendo de si usa las listas S&P de gran capitalización, mediana capitalización o pequeña capitalización, pero incluye empresas que cotizan en bolsa (y no empresas privadas) y, por lo tanto, todavía sesgadas. También tenga en cuenta que la población de la que se extrae una muestra puede no ser necesariamente la misma que la población sobre la que realmente queremos información. Por ejemplo, si un investigador quiere la tasa de éxito de un nuevo programa de «dejar de fumar», entonces la población objetivo es el universo de fumadores que tuvieron acceso a este programa, que puede ser una población desconocida. Por lo tanto, el investigador puede probar a los pacientes que llegan a un centro médico local para el tratamiento para dejar de fumar, algunos de los cuales pueden no haber tenido exposición a este programa particular de «dejar de fumar», en cuyo caso, el marco de muestreo no corresponde a la población de interés .
El último paso en el muestreo es elegir una muestra del marco de muestreo utilizando una técnica de muestreo bien definida. Las técnicas de muestreo se pueden agrupar en dos categorías amplias: muestreo de probabilidad (aleatorio) y muestreo no probabilidad. El muestreo de probabilidad es ideal si la generalización de los resultados es importante para su estudio, pero puede haber circunstancias únicas en las que también se puede justificar el muestreo no probabilidad. Estas técnicas se discuten en las siguientes dos secciones.
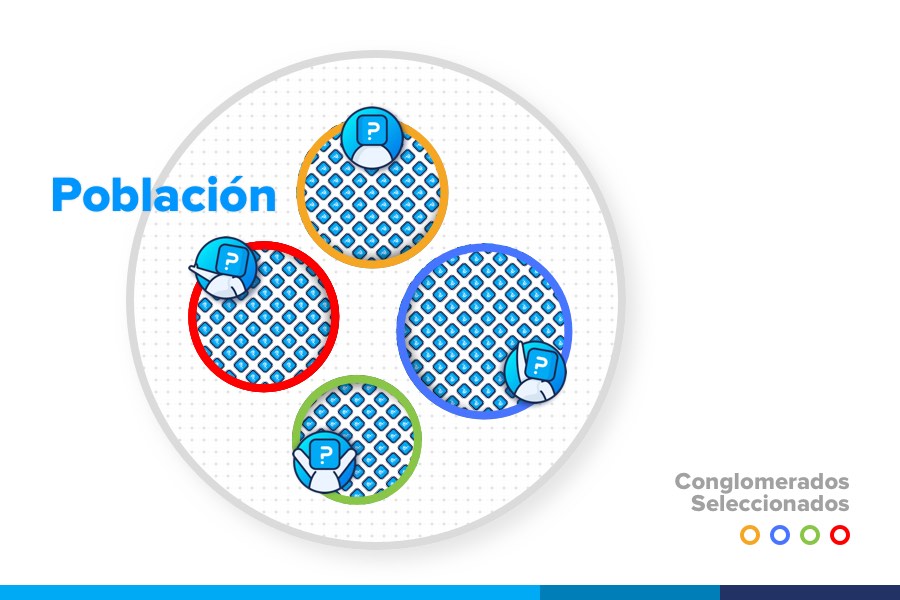
¿Cómo se realiza el muestreo por conglomerados?
La inferencia estadística se basa en un muestreo aleatorio. Hay varios tipos de muestra.
- Muestra aleatoria (muestra aleatoria): cada individuo de la población madre tiene la misma probabilidad de aparecer en la muestra. Es el modelo/ideal de la muestra.
- Muestra aleatoria estratificada (muestra aleatoria): en este tipo de muestra, cada elemento solo puede pertenecer a un estrato. En cada estrato, cada individuo tiene la misma probabilidad de aparecer en la muestra. Por ejemplo, cuando está interesado en estudiar las opiniones de los ciudadanos de Ginebra, Friborg y Zurich, debemos asegurarnos de que haya ciudadanos de cada cantón en la muestra.
- Muestra por conglomerados (muestreo de comblomerado): a veces el objetivo del análisis es, por ejemplo, la familia. La unidad de la muestra tendrá varios individuos. Para cada característica analizada tendremos varias observaciones, mientras que con una muestra aleatoria o laminada solo tendremos una observación.
El tamaño de la muestra depende de: la precisión de los resultados que desea obtener y
Restricciones en términos de tiempo y costas
- Muestra aleatoria (muestra aleatoria): cada individuo de la población madre tiene la misma probabilidad de aparecer en la muestra. Es el modelo/ideal de la muestra.
- Muestra aleatoria estratificada (muestra aleatoria): en este tipo de muestra, cada elemento solo puede pertenecer a un estrato. En cada estrato, cada individuo tiene la misma probabilidad de aparecer en la muestra. Por ejemplo, cuando está interesado en estudiar las opiniones de los ciudadanos de Ginebra, Friborg y Zurich, debemos asegurarnos de que haya ciudadanos de cada cantón en la muestra.
- Muestra por conglomerados (muestreo de comblomerado): a veces el objetivo del análisis es, por ejemplo, la familia. La unidad de la muestra tendrá varios individuos. Para cada característica analizada tendremos varias observaciones, mientras que con una muestra aleatoria o laminada solo tendremos una observación.
Usted es responsable de una investigación de opinión para estimar la proporción de ciudadanos que son favorables para la membresía de CommunAut & Eacute. La población de ciudadanos es de 100 leches. ¿Cuál sería el tamaño de la muestra relevante para el estudio?
- Muestra aleatoria (muestra aleatoria): cada individuo de la población madre tiene la misma probabilidad de aparecer en la muestra. Es el modelo/ideal de la muestra.
- Muestra aleatoria estratificada (muestra aleatoria): en este tipo de muestra, cada elemento solo puede pertenecer a un estrato. En cada estrato, cada individuo tiene la misma probabilidad de aparecer en la muestra. Por ejemplo, cuando está interesado en estudiar las opiniones de los ciudadanos de Ginebra, Friborg y Zurich, debemos asegurarnos de que haya ciudadanos de cada cantón en la muestra.
- Muestra por conglomerados (muestreo de comblomerado): a veces el objetivo del análisis es, por ejemplo, la familia. La unidad de la muestra tendrá varios individuos. Para cada característica analizada tendremos varias observaciones, mientras que con una muestra aleatoria o laminada solo tendremos una observación.
Artículos Relacionados:

