La variabilidad de los datos también conocida como dispersión o dispersión, se refiere a cómo es la propagación de un conjunto de datos. La variabilidad brinda a los usuarios una forma de describir cuánto varían los conjuntos de datos y permite a los usuarios usar estadísticas para comparar sus datos con otros conjuntos de datos.
Las cuatro formas principales de describir la variabilidad en un conjunto de datos son:
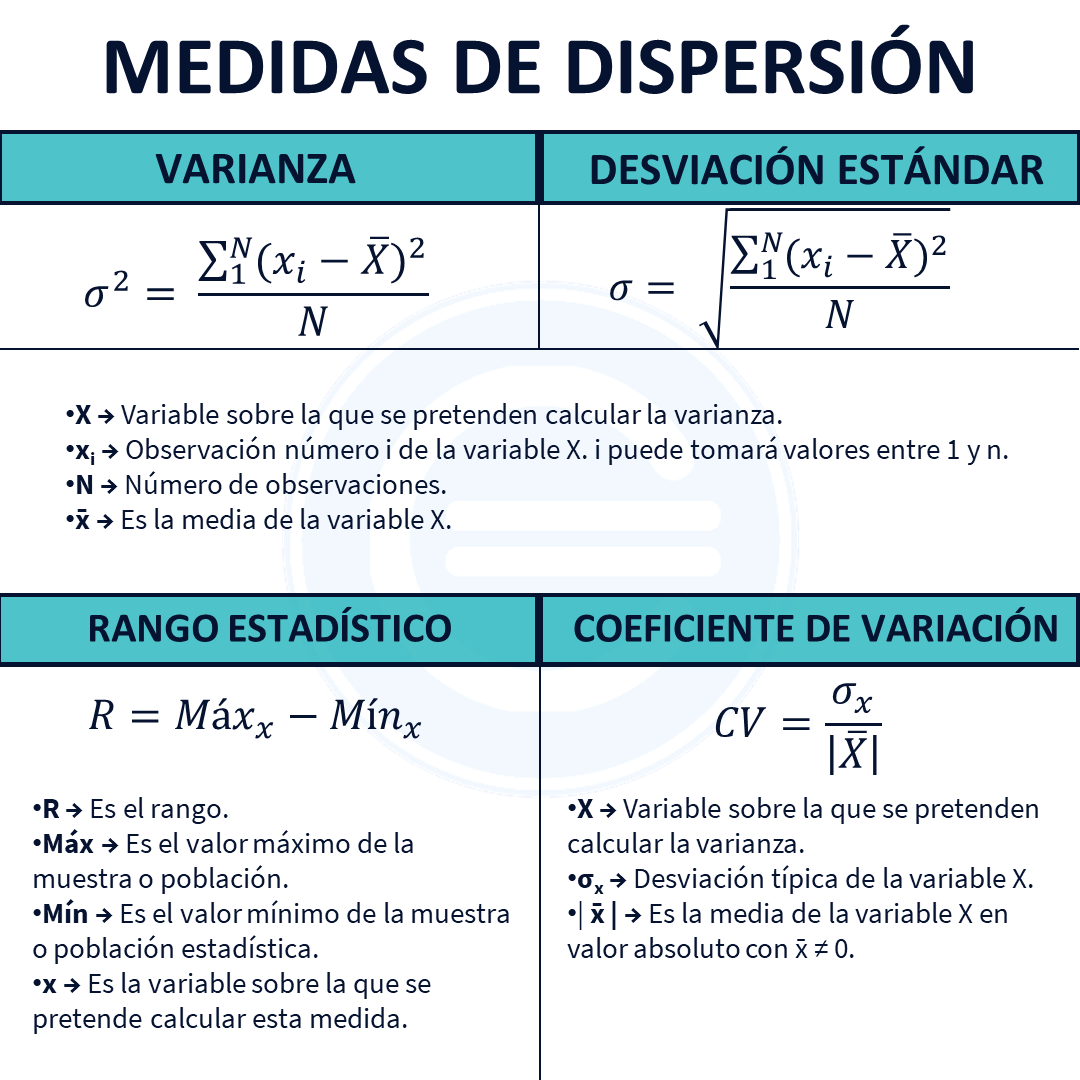
- Rango: el rango es la cantidad entre el artículo más pequeño y más grande del conjunto.
- Rango intercuartil: el rango intercuartil es un número que indica cómo se extienden los puntajes y les dice a los usuarios cuál es el rango en el medio de un conjunto de puntajes.
- Varianza: la varianza de un conjunto de datos brinda a los usuarios una idea aproximada de cómo se extienden los datos
- Desviación estándar: la desviación estándar le dice a un usuario cuán estrechamente se agrupan sus datos en torno a la media
En el contexto de Big Data, la variabilidad se refiere al número de inconsistencias en los datos. La variabilidad también puede referirse a la velocidad inconsistente a la que Big Data se carga en su base de datos. Por último, Big Data en sí mismo puede clasificarse como una variable, debido a la multitud de dimensiones de datos que resultan de los múltiples tipos y fuentes de datos dispares disponibles.
En los datos definidos, ayudamos a que el complejo mundo de los datos sea más accesible al explicar algunos de los aspectos más complejos del campo.
¿Qué es la variabilidad en estadística?
Los estadísticos utilizan medidas sumarias para describir la cantidad de variabilidad
o extenderse en un conjunto de datos. Las medidas de variabilidad más comunes
son el rango, el rango intercuartil (IQR), la varianza y
Desviación Estándar.
Nota: Su navegador no admite el video HTML5. Si ve esta página web en un navegador diferente
(por ejemplo, una versión reciente de Edge, Chrome, Firefox u Opera), puede ver un tratamiento de video de esta lección.
El rango es la diferencia entre el más grande
y valores más pequeños en un
conjunto de valores.
Por ejemplo, considere los siguientes números: 1, 3, 4, 5, 5, 6, 7, 11.
Para este conjunto de números, el rango sería 11 – 1 o 10.
El rango intercuartil (IQR) es una medida de variabilidad,
basado en dividir un conjunto de datos en
cuartiles.
Los cuartiles dividen un conjunto de datos ordenados por rango en cuatro partes iguales. Los valores que
dividir cada parte se llaman los primeros, segundo y tercer cuartiles;
y son denotados por Q1, Q2 y Q3, respectivamente.
- Q1 es el valor «medio» en la primera mitad del rango ordenado
conjunto de datos.
Q2 es la mediana de todo el conjunto de datos: el valor medio. En este ejemplo, tenemos un número par de
Puntos de datos, por lo que la mediana es igual al promedio de los dos valores medios. Así, Q2 =
(4 + 5)/2 o Q2 = 4.5. Q1 es el valor medio en la primera mitad del conjunto de datos. Dado que hay un
un número de puntos de datos en la primera mitad del conjunto de datos, el valor medio
es el promedio de los dos valores medios; eso es,
Q1 = (2 + 3)/2 o Q1 = 2.5. Q3 es el valor medio en la segunda mitad
del conjunto de datos. Nuevamente, dado que la segunda mitad del conjunto de datos tiene un par de
número de observaciones, el valor medio es el promedio de los dos
valores medios; es decir, Q3 = (6 + 7)/2 o Q3 = 6.5. El intercuartil
El rango es Q3 menos Q1, por lo que IQR = 6.5 – 2.5 = 4.
¿Qué es variabilidad en estadística ejemplos?
La variabilidad, por definición, es la medida en que los puntos de datos de una distribución estadística o un conjunto de datos difieren, varían, del valor promedio, así como la medida en que estos puntos de datos difieren de algunos de los otros. En términos financieros, esto se aplica con mayor frecuencia a la variabilidad de los rendimientos de inversión. Comprender la variabilidad de los rendimientos de la inversión es tan importante para los inversores profesionales como comprender el valor de los rendimientos mismos. Los inversores asimilan una gran variabilidad de los rendimientos a un mayor riesgo de riesgo durante la inversión.
- La variabilidad se refiere a la divergencia de los datos en comparación con su valor promedio y se usa comúnmente en los sectores estadísticos y financieros.
- La variabilidad de las finanzas se aplica con mayor frecuencia a la variabilidad de los rendimientos, donde los inversores prefieren inversiones que tienen un mayor rendimiento con menos variabilidad.
- La variabilidad se utiliza para normalizar los rendimientos obtenidos en una inversión y proporciona un punto de comparación para un análisis adicional.
Los inversores profesionales perciben el riesgo de una clase de activos como directamente proporcional a la variabilidad de sus rendimientos. En consecuencia, los inversores requieren un mejor rendimiento de los activos con una mayor variabilidad de los rendimientos, como acciones o materias primas, de lo que podrían esperar de los activos con una menor variabilidad de los rendimientos, como los cupones de tesoros.
Esta diferencia en anticipación también se conoce como la prima de riesgo. La prima de riesgo se refiere a la cantidad requerida para motivar a los inversores a colocar su dinero en activos de mayor riesgo. Si un activo muestra una mayor variabilidad de los rendimientos pero no muestra una tasa de rendimiento más alta, los inversores tampoco serán invertir en este activo.
Las estadísticas de variabilidad se refieren a la diferencia presentada por los puntos de datos en un conjunto de datos, en relación entre sí o en relación con el promedio. Esto puede expresarse por la playa, la varianza o la desviación estándar de un conjunto de datos. El campo de las finanzas utiliza estos conceptos porque se aplican específicamente a los precios y los rendimientos que implican los cambios de precios.
La playa se refiere a la diferencia entre el valor más grande y el más pequeño atribuido a la variable examinada. En el análisis estadístico, la playa está representada por un solo número. En los datos financieros, este rango a menudo se refiere al valor de precio más alto y más bajo para un día determinado u otro período. La desviación estándar es representativa de la brecha entre los puntos de precio durante este período, y la varianza es el cuadrado de la desviación estándar basada en la lista de puntos de datos de este mismo período.
¿Qué significa la variabilidad?
Diagrama esquemático del mecanismo físico responsable de la coherencia de la variabilidad de la precipitación en el primer ministro y el noreste y el norte de China Crédito: Science China Press
Noticias de salud, consistencia espacial de la variabilidad de la precipitación de verano entre la meseta mongol y el norte de China – Health News
Cuando estudias los latidos del corazón cuidadosamente en reposo, observas que el corazón no supera como un metrónomo y que el tiempo entre las contracciones varía. La investigación médica estaba interesada en la pregunta de la década de 1960 y pudo concluir rápidamente que esta variabilidad tenía una relación cercana con la actividad de la SNA, lo que refleja la interacción compleja entre las influencias parasimpáticas y simpáticas.
El tiempo, entre los latidos del corazón, descubre la clave de la fatiga – Tiempo
Tribuna. La crisis debida a la Covid-19 ha resultado en una desaceleración en la actividad económica y una caída sin precedentes en la demanda de electricidad. En este contexto, si el aumento en la participación de las energías solares y eólicas en la producción de electricidad era algo bueno, sin embargo, ha debilitado el sistema eléctrico, según la estrategia de Francia. De hecho, si bien el aumento en la variabilidad de la producción, debido a la intermitente de estas energías, requiere un aumento en las fuentes pilotables flexibles, la caída de la demanda conduce, por el contrario, para detenerse de una manera significativa de plantas de energía convencionales flexibles, aquellas Eso rápidamente devuelve al equilibrio la red eléctrica.
Le Monde.fr, «Hidroelectricidad, energía discreta y limpia, proporciona una respuesta ideal a las dos necesidades para reindustrializar y supervisar el gasto»
Las dos medidas para priorizar los autobuses STL reducirían en última instancia la «gran variabilidad de los tiempos de viaje intermedio», que la oficina del proyecto de tranvía ha destacado en sus comunicaciones con el BAPE.
Le Journal de Québec, Tramway: No hay carreteras reservadas para autobuses en puentes | JDQ
¿Qué es la variabilidad y un ejemplo?
La variabilidad, casi por definición, es la medida en que los puntos de datos en una distribución estadística o el conjunto de datos divergen, varían, del valor promedio, así como la medida en que estos puntos de datos difieren entre sí. En términos financieros, esto se aplica con mayor frecuencia a la variabilidad de los rendimientos de inversión. Comprender la variabilidad de los rendimientos de la inversión es tan importante para los inversores profesionales como comprender el valor de los rendimientos mismos. Los inversores equiparan una alta variabilidad de los rendimientos a un mayor grado de riesgo al invertir.
- La variabilidad se refiere a la divergencia de los datos de su valor medio, y se usa comúnmente en los sectores estadísticos y financieros.
- La variabilidad en las finanzas se aplica más comúnmente a la variabilidad de los rendimientos, en el que los inversores prefieren inversiones que tienen un mayor rendimiento con menos variabilidad.
- La variabilidad se utiliza para estandarizar los rendimientos obtenidos en una inversión y proporciona un punto de comparación para un análisis adicional.
Los inversores profesionales perciben que el riesgo de que una clase de activos sea directamente proporcional a la variabilidad de sus rendimientos. Como resultado, los inversores exigen un mayor rendimiento de los activos con una mayor variabilidad de los rendimientos, como acciones o productos básicos, de lo que podrían esperar de los activos con una menor variabilidad de los rendimientos, como las facturas del Tesoro.
Esta diferencia en la expectativa también se conoce como la prima de riesgo. La prima de riesgo se refiere a la cantidad requerida para motivar a los inversores a colocar su dinero en activos de mayor riesgo. Si un activo muestra una mayor variabilidad de los retornos pero no muestra una mayor tasa de rendimiento, los inversores no tendrán como probabilidades de invertir dinero en ese activo.
¿Qué es variable y variabilidad?
Una consideración muy básica (pero a menudo pasada por alto) en la selección de variables para un análisis estadístico es su varianza. Como mínimo, sus datos deben contener al menos dos valores únicos para una variable para analizarlo. Por ejemplo, no puede realizar un análisis estadístico del sexo si solo hay mujeres en su muestra. Esto puede parecer bastante obvio, pero he visto un sorprendente número de estudiantes que proponen cosas como las comparaciones sexuales en todas las muestras femeninas (o todos los hombres). Este es un ejemplo extremo, pero destaca la importancia de la varianza en sus datos. Si su variable no varía, por definición ya no es una variable (en cambio, se consideraría una constante).
Alinear el marco teórico, la recopilación de artículos, sintetizar brechas, articular una metodología y plan de datos claros, y escribir sobre las implicaciones teóricas y prácticas de su investigación son parte de nuestros servicios integrales de edición de tesis.
- Rastree todos los cambios, luego trabaje con usted para lograr una escritura académica.
- Apoyo continuo para abordar los comentarios del comité, reduciendo las revisiones.
La varianza en sus datos puede tener un impacto importante en el poder estadístico de su análisis. Usemos una prueba t de muestras independientes como ejemplo. Diga que desea comparar los puntajes de prueba estandarizados de estudiantes de dos aulas (Clase A y Clase B). Idealmente, cada aula tendría el mismo número de estudiantes (por ejemplo, 50 en la clase A y 50 en la clase B). La prueba t de muestras independientes tendrá el máximo poder estadístico cuando los tamaños de grupo son exactamente iguales. Si los tamaños de su grupo son desiguales (por ejemplo, 75 en la clase A y 25 en la clase B), el análisis tendrá menos poder, lo que significa que es menos probable que encuentre un resultado significativo. En otras palabras, si reduce la varianza de su variable independiente (membresía en el aula), se reduce su poder estadístico. Algunos cálculos de potencia hipotética en la potencia G*muestran cuánto puede reducirse su potencia mediante tamaños de grupo desiguales. Los valores de potencia a continuación se calcularon para una prueba t de muestras independientes de dos colas con un tamaño de efecto medio y un nivel de significancia de .05:
- Rastree todos los cambios, luego trabaje con usted para lograr una escritura académica.
- Apoyo continuo para abordar los comentarios del comité, reduciendo las revisiones.
Puede ver que tener tamaños de grupo extremadamente desiguales puede reducir la potencia del análisis en más de la mitad, incluso cuando el tamaño general de la muestra sigue siendo el mismo. Ahora, esto no significa necesariamente que los tamaños de su grupo siempre deben ser iguales. Esto tampoco significa necesariamente que más varianza siempre sea mejor. Más bien, este ejemplo simplemente demuestra una de las consecuencias de tener muy poca variación en sus datos.
¿Qué significa la variabilidad genética?
La variabilidad genética es la presencia o la generación de diferencias genéticas.
Se define como «la formación de individuos que difieren en el genotipo, o la presencia de individuos genotípicamente diferentes, en contraste con las diferencias inducidas por el medio ambiente que, por regla general, causan solo cambios temporales y no sujetables del fenotipo». [1] La variabilidad genética en una población es importante para la biodiversidad. [2]
- La recombinación homóloga es una fuente significativa de variabilidad. Durante la meiosis en los organismos sexuales, dos cromosomas homólogos se cruzan entre sí e intercambian material genético. Los cromosomas se dividen y están listos para contribuir a formar una descendencia. La recombinación es aleatoria [cita necesaria] y se rige por su propio conjunto de genes. Controlarse por genes significa que la recombinación es variable en frecuencia.
- Inmigración, emigración y translocación: cada uno de estos es el movimiento de un individuo dentro o fuera de una población. Cuando un individuo proviene de una población previamente aislada genéticamente en una nueva, aumentará la variabilidad genética de la próxima generación si se reproduce. [3]
- Polpoidy: tener más de dos cromosomas homólogos permite aún más recombinación durante la meiosis, lo que permite una mayor variabilidad genética en la descendencia de uno.
- Centrómeros difusos: en organismos asexuales donde la descendencia es una copia genética exacta de los padres, existen fuentes limitadas de variabilidad genética. Sin embargo, una cosa que aumentó la variabilidad es haber difundido en lugar de centrómeros localizados. Ser difundido permite que las cromátidas se separen de muchas maneras diferentes, permitiendo la fragmentación cromosómica y la poliploidía creando más variabilidad. [4]
- Mutaciones genéticas: contribuyen a la variabilidad genética dentro de una población y pueden tener efectos positivos, negativos o neutros en una aptitud. [5] Esta variabilidad se puede propagar fácilmente a lo largo de una población mediante selección natural si la mutación aumenta la aptitud del individuo afectado y sus efectos se minimizarán/ocultarán si la mutación es perjudicial. Sin embargo, cuanto más pequeña sea la población y su variabilidad genética, más probable es que aparezcan mutaciones nocivas recesivas/ocultas causando la deriva genética. [5]
¿Qué es la variabilidad y cómo se calcula?
La variabilidad es un término utilizado para describir cuántos puntos de datos en cualquier distribución estadística difieren entre sí y de su valor medio. Las herramientas estadísticas utilizadas para medir la variabilidad son el rango, la desviación estándar y la varianza.
Es una métrica útil en finanzas cuando se aplica para medir la variabilidad de los rendimientos de inversión. En general, los inversores reacios al riesgo prefieren inversiones que proyectan una baja variabilidad en los rendimientos.
- La variabilidad mide cuánto puntos de datos en cualquier distribución estadística difieren entre sí, así como de su valor medio.
- Es una métrica útil en finanzas cuando se aplica para medir la variabilidad de los rendimientos de inversión.
- La alta variabilidad en los rendimientos se asocia con un alto grado de riesgo, mientras que la baja variabilidad se asocia con un grado de riesgo relativamente bajo.
El precio del activo X es de $ 100, y proporciona diferentes rendimientos en diferentes años, como se muestra en la siguiente tabla:
La variabilidad en los retornos del activo X se puede calcular utilizando las siguientes herramientas estadísticas:
El rango es simplemente la diferencia entre los valores más altos y más bajos en el conjunto de datos en consideración. En el ejemplo anterior:
La desviación estándar mide la medida en que todos los puntos de datos difieren de su valor medio. La fórmula para calcular la desviación estándar es
¿Cómo se calcula la variabilidad?
Sin embargo, la desviación estándar es la medida de variabilidad más utilizada. La desviación estándar nos dice, en promedio, cuánto de nuestras observaciones está cerca del promedio. Una desviación estándar más grande indica que nuestros datos están más extendidos. Esta página (disponible en inglés) presenta las líneas principales de la fórmula detrás del cálculo de la desviación estándar. Cómo calcular esto en Excel, ¡es simple!
Para obtener más información: ¿Cuál es el significado de la desviación estándar? La situación se puede resumir simplemente como se muestra en el siguiente gráfico:
Esto generalmente supone que utiliza la desviación estándar cuando la distribución gráfica de sus datos parece una campana (es una distribución gaussiana).
Supongamos que desea comprender el impacto de la construcción de pozos en la población de beneficiarios en un campamento, que mide por la cantidad de agua que las personas reciben pozos por día en las casas circundantes. Gracias a una encuesta, encuentra un valor promedio de 21 litros por persona por día y una desviación estándar de 2.1. Esto significa que el 68.2 % de los valores son entre 18.9 y 23.1 litros por persona por día. Además, el 95 % de los valores estarán entre 21 litros – 22.1 = 16.8 y 21 + 22.1 = 25.2.
Por lo tanto, puede plantear la hipótesis de que (si su encuesta se ha llevado a cabo con un método de muestreo apropiado) la mayoría de sus beneficiarios en el área (95% de ellos) recibieron al menos 16.8 litros/persona/persona/día (y hasta 25.2).
¿Qué es la variabilidad en matemáticas?
La variabilidad a menudo es un tema difícil para los recién llegados a las estadísticas que comprendan. Esencialmente es la propagación de los puntajes en una distribución de frecuencia. Si tiene una curva de campana que es bastante plana, diría que tiene una alta variabilidad. Si tiene una curva de campana que es puntiaguda, diría que tiene baja variabilidad. La variabilidad es realmente una medida cuantitativa de las diferencias entre las puntuaciones y describe el grado en que el puntaje se extiende o se agrupa. El propósito de medir la variabilidad es poder describir la distribución y medir qué tan bien una puntuación individual representa la distribución.
- Rango: la distancia entre la puntuación más baja y más alta en una distribución. Se puede describir como un número o representado escribiendo el número más bajo y más alto juntos (por ejemplo, valores 4-10). Calculado restando la puntuación más alta de la puntuación más baja. Si está trabajando con variables continuas, es el límite real superior para Xmax menos el límite real inferior para Xmin.
- Desviación estándar: la distancia promedio entre los puntajes en un conjunto de datos y la media. Este valor es también la raíz cuadrada de la varianza. Aquí hay un video para ayudarlo a conceptualizar esto.
- Varianza: mide la distancia cuadrada promedio de la media. Este número es bueno para algunos cálculos, pero en general queremos que la desviación estándar determine cuán dispersa es una distribución. Calculado con esta ecuación:
La varianza de la muestra es solo la varianza que debe calcularse como un sustituto a veces cuando la varianza de la población no está disponible (esto se hablará más adelante). Vea la primera diapositiva a continuación para un video que explica esto más. Los grados de libertad determinan el número de puntajes en la muestra que son independientes y libres de variar. Esto es importante porque en una muestra, todos los puntos de datos pueden ser cualquier puntaje, pero el último puntaje debe ser tal que la media calculamos que calculamos las medidas. Entonces, si tenemos 3 puntajes en un conjunto, y sabemos que la media es 5, los dos primeros puntajes pueden ser cualquier número, en este caso son 9 y 2. Debido a que calculamos que la media es 5, el último número debe ser 4 Para sumar hasta 15 y dividir por 3 para obtener 5. El último puntaje depende de los otros puntajes. Al esto significa prácticamente que la ecuación de la varianza de la muestra difiere de la varianza de la población en que el denominador es N-1. Entonces, N-1 literalmente significa que todos los puntajes, excepto el «último», puede ser lo que quieran. Vea la segunda diapositiva a continuación para obtener un video con algo más de explicación.
Una estimación imparcial de un parámetro de población es cuando el valor promedio de una estadística es igual al parámetro y el valor promedio usa todas las muestras posibles de un tamaño particular n. Una estimación sesgada de un parámetro de población sobreestima o subestima sistemáticamente el parámetro de población. En este caso, sabemos que la variabilidad de la muestra tiende a subestimar la variabilidad de la población correspondiente. Corrimos esto usando grados de libertad y contabilizamos esto cuando usamos un error estándar.
La variabilidad en los datos influye en lo fácil que es ver patrones. La alta variabilidad oscurece los patrones para comparar dos conjuntos de datos que serían visibles en muestras de baja variabilidad. Sin embargo, no puede decirle si hay una diferencia significativa entre los grupos. Debe ejecutar un análisis de varianza o prueba t para determinar eso.
¿Cómo interpretar la variabilidad de los datos?
¿Por qué necesita saber sobre las medidas de variabilidad?
Debe poder comprender cómo el grado en que datos
Los valores se extienden en una distribución se pueden evaluar utilizando simple
Las medidas para representar mejor la variabilidad en los datos.
¿Por qué? Porque, las medidas de variabilidad también ocurren muy
frecuentemente en la literatura de investigación médica.
De nuevo, como fue el caso con las medidas de
tendencia central,
No puedes entender, y mucho menos críticamente
Evaluar estudios de investigación médica a menos que comprenda el
Uso apropiado de tales medidas.
Veamos el concepto de variabilidad. Es básicamente un
concepto simple. Cuando estás hablando de variabilidad, estás
Hablando de cuán disperso o disperso o extendido los datos.
El concepto básicamente tiene que ver con el ancho de un
distribución.
En general, otras cosas son iguales, la
Más amplia la distribución, más variabilidad (ver Figura 2.5 a continuación).
Entonces, a qué variabilidad se refiere es cómo dispersado o extendido el
Los valores de los datos son, o mirarlo desde otro punto de vista
Qué tan amplia es la distribución de datos cuando está gráfica.
Si todos los valores de datos son los mismos, entonces, por supuesto, hay
variabilidad cero. El gráfico de la distribución tendría un ancho cero.
Si todos los valores se encuentran muy cerca de cada uno
Otro hay poca variabilidad y el gráfico de la distribución
ser bastante estrecho. Si, por otro lado, los números se extienden
fuera por todas partes, hay más variabilidad y el gráfico
ser más ancho.
Ninguna respuesta
Altura de una distribución
Ancho de una distribución
Curvatura de una distribución
Desesperación de una distribución
¿Qué indica la variabilidad de los datos?
El índice de variabilidad más simple es el campo de variación, definido como la diferencia entre el valor máximo y el valor mínimo de los datos estadísticos:
El campo de variabilidad representa una medida de dispersión gruesa y no muy significativa, porque los valores intermedios de distribución no lo afectan. Sin embargo, tiene la ventaja de calcularse fácilmente y es particularmente útil en pequeños campeones.
Son x1, x2,… xn las modalidades de un carácter cuantitativo. Si son sus medios aritméticos, se llaman residuos, las diferencias:
La diferencia entre cada uno de los valores de los datos estadísticos y el promedio aritmético del mismo se define del promedio.
Los desechos pueden ser positivos, negativos o nulos, pero su suma es siempre la misma que cero.
Como se mencionó, los desechos pueden ser positivos, negativos o nulos, pero su suma es siempre la misma que cero.
Para eliminar la influencia de los signos y no tener que administrar valores absolutos, se introdujo otro índice de variabilidad, varianza.
La varianza σ² se define como una distribución de datos El promedio aritmético de los cuadrados de residuos:
A menudo, para no hacer demasiados cálculos, se utiliza la fórmula abreviada de la varianza:
Si se da una distribución de frecuencia, en el cálculo de la varianza debemos tener en cuenta, calculando el promedio aritmético ponderado de los cuadrados de residuos, con pesos igual a sus respectivas frecuencias.
¿Cómo saber si la variabilidad de los datos es aceptable?
Para describir la variabilidad de los datos, el promedio, la mediana, la desviación estándar… son un buen comienzo, pero puede ser interesante ofrecer otras medidas.
- El alcance: simplemente especifique el mínimo y el máximo de los datos. La diferencia entre el Minium y el máximo se denomina extensión. Esto pasa por alto los extremos de los datos.
- La desviación estándar, para obtenerla, debe aplicar la siguiente fórmula:
Para obtener una desviación estándar, es simplemente necesario:
- El alcance: simplemente especifique el mínimo y el máximo de los datos. La diferencia entre el Minium y el máximo se denomina extensión. Esto pasa por alto los extremos de los datos.
- La desviación estándar, para obtenerla, debe aplicar la siguiente fórmula:
Si solo tiene el promedio y la desviación estándar, puede calcular el coeficiente de variación que le permite tener una idea del alcance relativo de los datos. El coeficiente de variación se calcula dividiendo el promedio por la desviación estándar. Por ejemplo, si el promedio es 40 y la desviación estándar de 6, el coeficiente de variación es 6/40 = 0.15. Esto puede comparar la variabilidad de dos muestras.
Si los datos cumplen con la distribución normal (en forma de campana, con un promedio y mediana bastante cercana), la desviación estándar permite la distribución de valores.
- El alcance: simplemente especifique el mínimo y el máximo de los datos. La diferencia entre el Minium y el máximo se denomina extensión. Esto pasa por alto los extremos de los datos.
- La desviación estándar, para obtenerla, debe aplicar la siguiente fórmula:
Esto permite, por ejemplo, ver los valores a tener en cuenta para satisfacer el 95% de los usuarios.
Artículos Relacionados:
- La variabilidad estadística y sus aplicaciones para la toma de decisiones en la empresa
- ¿Qué es la variación directa? ¡Aprende aquí la definición y cómo aplicarla en matemáticas!
- Intervalos estadísticos: definición y cómo utilizarlos
- ¿Qué es una variable en estadística?
- ¿Cuál es la diferencia significativa en estadística?

