Una diferencia estadísticamente significativa le indica si las respuestas de un grupo son sustancialmente diferentes de las respuestas de otro grupo mediante el uso de pruebas estadísticas. La significación estadística significa que los números son confiablemente diferentes, ayudando en gran medida a su análisis de datos. Aún así, también debe considerar si los resultados son importantes: depende de usted decidir cómo interpretar o tomar medidas en sus resultados.
Por ejemplo, digamos que recibe más quejas de los clientes de las mujeres que de los hombres. ¿Cómo sabes que esta es una diferencia real que debes abordar? Una excelente manera es ejecutar una encuesta para ver si sus clientes masculinos están mucho más satisfechos con su producto. Usando una fórmula estadística, nuestra característica de significación estadística puede ayudarlo a determinar si los hombres tienen niveles significativamente más altos de satisfacción con su producto que las mujeres. Esto le permite tomar medidas en datos, no en anécdota.
Si sus resultados se destacan en su tabla de datos, eso significa que los dos grupos son significativamente diferentes entre sí. La importancia significa que los números son estadísticamente diferentes: no significa que el hallazgo sea importante o significativo.
Si sus resultados no se destacan en su tabla de datos, aunque los porcentajes que se comparan pueden ser diferentes, los dos números no son estadísticamente diferentes.
Las respuestas sin diferencias estadísticamente significativas muestran que los dos elementos que se comparan no son significativamente diferentes en el tamaño de su muestra, pero no necesariamente significa que no son importantes. Es posible que pueda detectar una diferencia estadísticamente significativa al aumentar el tamaño de su muestra.
¿Cómo se calcula la diferencia significativa?
La significación estadística a menudo se calcula con pruebas de hipótesis estadística, que prueba la validez de una hipótesis al descubrir la probabilidad de que sus resultados hayan sucedido por casualidad.
Aquí, una «hipótesis» es una suposición o creencia sobre la relación entre sus conjuntos de datos. El resultado de una prueba de hipótesis nos permite ver si esta suposición se mantiene bajo escrutinio o no.
Una prueba de hipótesis estándar se basa en dos hipótesis.
- Hipótesis nula: la suposición predeterminada de una prueba estadística que intenta refutar (por ejemplo, un aumento en el costo no afectará el número de compras).
- Hipótesis alternativa: una teoría alternativa que contradice su hipótesis nula (por ejemplo, un aumento en el costo reducirá el número de compras). Esta es la hipótesis que esperas probar.
La parte de prueba de las pruebas de hipótesis nos permite determinar qué teoría, la nula o alternativa, está mejor respaldada por los datos. Hay muchas metodologías de prueba de hipótesis, y una de las más comunes es la prueba Z, que es lo que discutiremos aquí. Pero, antes de llegar a la prueba Z, es importante para nosotros visitar otros conceptos estadísticos en los que se basa la prueba Z.
La distribución normal se usa para representar cómo se distribuyen los datos y se define principalmente por:
- Hipótesis nula: la suposición predeterminada de una prueba estadística que intenta refutar (por ejemplo, un aumento en el costo no afectará el número de compras).
- Hipótesis alternativa: una teoría alternativa que contradice su hipótesis nula (por ejemplo, un aumento en el costo reducirá el número de compras). Esta es la hipótesis que esperas probar.
¿Qué es la diferencia significativa?
Al leer o realizar investigaciones, es probable que se encuentre con el término «significación estadística». La «importancia» generalmente se refiere a algo que tiene una importancia particular, pero en la investigación, la «importancia» tiene un significado muy diferente.
La significación estadística es un término utilizado para describir cuán seguros estamos de que existe una diferencia o una relación entre dos variables y no se debe al azar. Cuando se identifica un resultado como estadísticamente significativo, esto significa que usted
confían en que existe una diferencia o relación real entre dos variables, y es poco probable que sea un hecho único.
Sin embargo, es un lugar común para la significación estadística (es decir, estar segura de que la posibilidad no estaba involucrada en sus resultados) para confundirse con la importancia general (es decir, tener importancia).
Un hallazgo estadísticamente significativo puede, o no, tener una utilidad del mundo real. Por lo tanto, tener una comprensión profunda de lo que es la importancia estadística y qué factores contribuyen a él, es importante para realizar una investigación sólida.
Una hipótesis es un tipo particular de predicción para cuáles serán los resultados de la investigación, y viene en dos formas. Una hipótesis nula predice que no hay diferencia o relación entre dos grupos o variables de interés y, por lo tanto,
Los dos grupos o variables son iguales. En contraste, una hipótesis alternativa predice que hay una diferencia o relación entre dos grupos o variables de interés. En este caso, los dos grupos o variables no son iguales, por lo que podría
ser mayor o menos el uno al otro.
Un propósito clave de las pruebas de significación estadística es determinar si su hipótesis nula ocurrió por casualidad. Si su hipótesis nula ocurrió por casualidad, entonces no rechazamos (retenemos) la hipótesis nula y concluyamos que no hay
diferencia. Debido a que el resultado ocurrió por casualidad, no es probable que suceda en el mundo real. Sin embargo, si su hipótesis nula no ocurrió por casualidad, entonces rechazamos la hipótesis nula y concluyimos que hay una diferencia. Porque
no ocurrió por casualidad, es probable que ocurra en el mundo real. Esto a su vez afectará las conclusiones que puede extraer de su investigación.
Al tratar con el azar, siempre existe la posibilidad de errores, incluidos los errores de Tipo I o Tipo II. Se produce un error tipo I cuando la hipótesis nula se rechaza cuando debería haberse retenido (es decir, un falso positivo).
Esto significa que los resultados se identifican como significativos cuando realmente ocurrieron por casualidad. Debido a que ocurrieron por casualidad, es poco probable que ocurra en el mundo real y, por lo tanto, debería haberse identificado como
no significativo. Se produce un error de tipo II cuando se retiene la hipótesis nula cuando debería haber sido rechazada (es decir, un falso negativo). Esto significa que los resultados se identifican como no significativos cuando en realidad
no ocurrió por casualidad. No ocurrir por casualidad sugiere que es probable que suceda en el mundo real, por lo que debería haberse identificado como significativo.
¿Qué significa significativo en estadística?
El significado estadístico indica que la relación de una variable con otra variable no es una coincidencia, sino que se debe a otro factor de esta variable. En términos simples, el significado estadístico es una representación matemática de la fiabilidad de las estadísticas. En este artículo, aprenderá cómo calcular el significado estadístico entre dos factores.
Puede comprender el concepto y encontrar una respuesta detallada calculando la importancia estadística a mano. Puedes usar una calculadora. Estos son los pasos que puede seguir para calcular el significado estadístico:
Primero, debe determinar la hipótesis nula. Puede averiguar si hay una diferencia en el conjunto de datos que utiliza. Nunca debes creer tu hipótesis cero, porque es solo una suposición.
Después de encontrar la hipótesis cero y la alternativa, determinará el nivel de significado o alfa. Es posible que deba rechazar su hipótesis nula incluso si es cierto. El alfa estándar es de 0.05 a 5 %.
Ahora decida la prueba que elegirá, unilateral o bilateral. Sin embargo, el área de distribución de la prueba unilateral es unilateral, y para la prueba bilateral, es bilateral. En otras palabras, en pruebas unilaterales, analizará la relación entre las dos variables en una dirección y en dos direcciones en pruebas bilaterales. Si sus muestras son unilaterales, entonces su hipótesis alternativa es cierta.
¿Qué quiere decir significativo en estadística?
Las palabras son importantes. Y es importante comprender su significado. Para aclarar algunos de los términos más utilizados por los medios, a continuación proponemos un pequeño léxico organizado en orden alfabético. Para acceder al significado, haga clic en palabras individuales.
Es la clasificación de las actividades económicas existentes. Es la versión nacional de la nomenclatura (NACE Rev. 2) definida y aprobada en el contexto europeo y que, a su vez, se deriva de la definida en el nivel de la ONU (ISIC Rev. 4). ATECO (término que resume las palabras actividades económicas) también es necesario para producir y difundir los datos de las investigaciones estadísticas. De hecho, todo eso es objeto de necesidades de detección estadística, para facilitar el trabajo, se clasificará con un código. Por lo tanto, cada actividad económica corresponde a un código hecho de números, mientras se usa las letras del alfabeto para indicar secciones, es decir, las categorías macro productivas como la agricultura, la fabricación, etc. Cuanto más numerosos pueden ir los números del código, hasta seis, más detallada es la actividad. Por ejemplo, en la sección M que distingue actividades profesionales, científicas y técnicas, el código 73 indica actividades de publicidad y investigación de mercado, pero podemos detallar más: el código 73.1 especifica la publicidad específicamente, 73.11.0 Las agencias de la publicidad, 73.11.01 indica el Actividad particular de la creación de campañas publicitarias.
Estos son aquellos datos a los que se han aplicado técnicas estadísticas que permiten eliminar las fluctuaciones vinculadas a períodos/estaciones específicas por razones de clima, leyes, costumbres, etc. Esta transformación de datos le permite comprender más correctamente el progreso de un fenómeno entre un período y otro. Aquí hay un par de ejemplos típicos: la disminución de la producción industrial en agosto, debido al cierre de muchas empresas para las vacaciones y el aumento en las ventas minoristas en diciembre, como resultado de las vacaciones de Navidad. El uso de datos disminuidos le permite monitorear la evolución de los fenómenos a lo largo del tiempo y promueve las comparaciones entre datos de diferentes países.
¿Cuando un valor es significativo?
Cuando realiza una prueba estadística, un valor p lo ayuda a determinar la importancia de sus resultados en relación con la hipótesis nula.
La hipótesis nula establece que no existe una relación entre las dos variables que se estudian (una variable no afecta a la otra). Establece que los resultados se deben al azar y no son significativos en términos de apoyar la idea que se está investigando. Por lo tanto, la hipótesis nula supone que lo que sea que esté tratando de probar no sucedió.
La hipótesis alternativa es la que creerías si la hipótesis nula se concluye como falsa.
La hipótesis alternativa establece que la variable independiente afectó la variable dependiente, y los resultados son significativos en términos de respaldo de la teoría que se está investigando (es decir, no debido al azar).
Un valor p, o un valor de probabilidad, es un número que describe la probabilidad de que sus datos se hubieran ocurrido por casualidad aleatoria (es decir, que la hipótesis nula es verdadera).
El nivel de significación estadística a menudo se expresa como un valor p entre 0 y 1. Cuanto más pequeño es el valor p, más fuerte es la evidencia de que debe rechazar la hipótesis nula.
- Un valor p inferior a 0.05 (típicamente ≤ 0.05) es estadísticamente significativo. Indica una fuerte evidencia contra la hipótesis nula, ya que hay menos del 5% de probabilidad de que el nulo sea correcto (y los resultados son aleatorios). Por lo tanto, rechazamos la hipótesis nula y aceptamos la hipótesis alternativa.
¿Cuando la diferencia entre dos valores es significativa?
SISA supondrá que las variaciones son desiguales y calcularán la prueba t de Welch. Este método produce un valor T ligeramente más pequeño como la prueba t tradicional del estudiante. Los grados de libertad para la prueba t de Welch se calculan utilizando una fórmula complicada. El número de grados de libertad será menor como en la prueba t de Student. Si marca el cuadro «igual var», SISA calculará la prueba t de Student del estudiante tradicional con grados de libertad N1+N2-2. La prueba T del estudiante es más poderosa que la prueba t de Welch y debe usarse si las variaciones son iguales. Hay una prueba F para estimar la probabilidad de que las variaciones sean iguales.
Verificar esta opción le brinda intervalos de confianza adicionales para la diferencia entre dos proporciones, la diferencia entre dos medias y el NNT. Tenga en cuenta que los intervalos de confianza predeterminados, los que obtiene cuando no solicita intervalos de confianza adicionales, serían la opción preferida para muchos investigadores. El intervalo de confianza CC-WALD es la versión corregida de continuidad del intervalo de confianza habitual de Wald. Da un intervalo de confianza ligeramente más amplio y se puede usar cuando el número de casos es pequeño. Newcombe (1998) propone el intervalo de confianza de la puntuación híbrida de Newcombe-Wilson (NW). Se basa en diferentes supuestos con respecto a la relación entre la muestra y la varianza de la población, el enfoque de prueba de puntaje. Da un intervalo de confianza un poco más estrecho. Aunque el método tiene algunas propiedades superiores, rara vez se usa.
Hay varias formas en que se puede calcular el número de grados de libertad para la prueba t de dos muestras. En el caso de las variaciones no iguales, la prueba t de Welch se usa principalmente y el número de grados de libertad para este método se calcula con la ecuación de Welch-Satterthwaite.
El número de grados para la prueba T del estudiante es igual a N1+N2-2. En el caso de la suposición de igual varianza, este número de grados de libertad es correcto para la prueba t de Student. Sin embargo, si la varianza de la media1 es diferente de la varianza de la media2, este número de grados de libertad es demasiado grande para la prueba t de Student. El uso del número N1+N2-2 de grados de libertad conduce a que una diferencia se declare estadísticamente significativa demasiado fácilmente y una mayor probabilidad de un error tipo I. Wonnacott y Wonnacott, entre otros, sugieren usar N1-1 o N2-1, lo que sea más pequeño. Desafortunadamente, el uso de esta fórmula hace que sea demasiado difícil declarar una diferencia estadísticamente significativa, una mayor posibilidad de un error tipo II. Si desea utilizar este método de todos modos (¡no sugerido!) Puede hacer sus cálculos y utilizar el procedimiento de significación en el sitio web de SISA para calcular el valor p.
¿Qué significa que una diferencia sea significativa?
Lo más probable es que haya escuchado o leído el término «estadísticamente significativo» en numerosas ocasiones en su vida. ¿Qué significa eso realmente y cómo determinamos si algo es significativo o no?
En la forma más básica, estadísticamente significativo significa algo que no se debe a la variabilidad aleatoria (no se atribuye al azar).
Si queremos obtener técnicos, la significación estadística se trata de la determinación de la hipótesis nula. La hipótesis nula es la hipótesis de que no hay diferencias significativas entre las poblaciones especificadas, cualquier diferencia observada se debe al muestreo o al error experimental. Al realizar pruebas de hipótesis, obtienes un resultado conocido como valor p, que es la probabilidad de observar resultados extremos en los datos que ha recopilado. Un valor p del 5% o menos se considera típicamente como estadísticamente significativo.
Al medir la relación entre múltiples variables (es decir, una nueva dieta versus dieta estándar, vacuna versus no vacuna, etc.), esto nos permite establecer la probabilidad de que un resultado sea causado por lo que estamos estudiando en lugar de suceder al azar. Esto significa que podemos determinar si algo realmente funciona mejor que dejar las cosas solo. Los nutricionistas hacen esto todo el tiempo al probar nuevas raciones; Las compañías farmacéuticas hacen esto al probar nuevos medicamentos o vacunas. Los veterinarios, y los científicos de investigación más probables, pueden usar esto para determinar si vale la pena un nuevo tipo de cirugía o un tratamiento costoso.
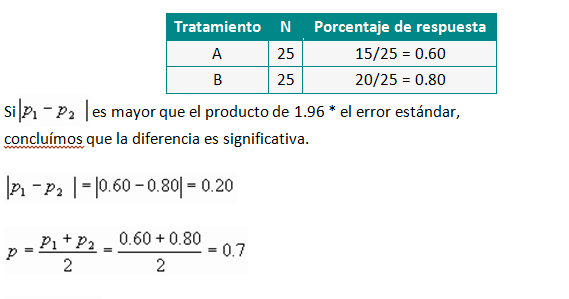
¿Cuánto es una diferencia significativa?
«Dos de mis estímulos tienen la misma puntuación, pero solo uno de ellos está mostrando una diferencia estadísticamente significativa en una norma o puntaje de referencia. ¿Por qué es esto?»
Al probar los puntajes medios para la importancia contra una norma, se tienen en cuenta varios factores, no solo la diferencia en la puntuación. El número de encuestados (el tamaño de la muestra) y la propagación de respuestas (el error estándar) también juegan un papel en el cálculo.
Al probar los puntajes de sus encuestas entre sí, Zappi usa una prueba t, tanto para medios como para proporciones. Al comparar una puntuación de la encuesta con una norma, utilizamos una prueba t unilateral de equivalencia para medias y una prueba z de proporciones.
Nuestras pruebas estadísticas predeterminadas solo destacan las diferencias con un nivel de confianza del 95%, y en algunos casos, también ofrecemos una opción de nivel de confianza del 99% o 90%.
A veces, sus puntajes pueden resultar en resultados confusos de la prueba SIG. Para mayor claridad, lo guiaremos a través de un ejemplo específico (ver más abajo). La puntuación más alta en el tercer anuncio no se marcó como significativamente por encima de la norma para una puntuación de 7.0, y la puntuación más baja en el primer anuncio, está significativamente por encima de la norma con una puntuación de 6.9.
El cálculo de la significación estadística tiene en cuenta la propagación (o distribución) de las respuestas del encuestado. Al tratar de responder la pregunta «es la puntuación media significativamente diferente a la norma», debemos tener la confianza de que la media es una representación justa de los datos. La forma en que la ecuación explica esto es utilizar la desviación estándar.
Artículos Relacionados:

