Las pruebas F llevan el nombre de su estadística de prueba, F, que fue nombrada en honor a Sir Ronald Fisher. La estadística F es simplemente una relación de dos variaciones. Las variaciones son una medida de dispersión, o hasta qué punto los datos están dispersos de la media. Los valores más grandes representan una mayor dispersión.
La varianza es el cuadrado de la desviación estándar. Para nosotros, los humanos, las desviaciones estándar son más fáciles de entender que las variaciones porque están en las mismas unidades que los datos en lugar de las unidades al cuadrado. Sin embargo, muchos análisis realmente usan variaciones en los cálculos.
Las estadísticas F se basan en la proporción de cuadrados medios. El término «cuadrados medios» puede sonar confuso, pero es simplemente una estimación de la varianza de la población que explica los grados de libertad (DF) utilizados para calcular esa estimación.
A pesar de ser una relación de variaciones, puede usar pruebas F en una amplia variedad de situaciones. Como era de esperar, la prueba F puede evaluar la igualdad de las variaciones. Sin embargo, al cambiar las variaciones que se incluyen en la relación, la prueba F se convierte en una prueba muy flexible. Por ejemplo, puede usar estadísticas F y pruebas F para probar el significado general para un modelo de regresión, comparar los ajustes de diferentes modelos, probar términos de regresión específicos y probar la igualdad de medias.
Para usar la prueba F para determinar si las medias del grupo son iguales, es solo una cuestión de incluir las variaciones correctas en la relación. En ANOVA unidireccional, el estadístico F es esta relación:
F = Variación entre medias de muestra / variación dentro de las muestras
¿Cómo sacar la F en estadística?
La prueba F es una prueba estadística que nos ayuda a encontrar si dos conjuntos de población que tienen una distribución normal de sus puntos de datos tienen la misma desviación o variaciones estándar. Pero lo primero y más importante que realizará la prueba F es que los conjuntos de datos deberían tener una distribución normal. Esto se aplica a la distribución F bajo la hipótesis nula. La prueba F es una parte muy crucial del análisis de varianza (ANOVA) y se calcula tomando las relaciones de dos variaciones de dos conjuntos de datos diferentes. Como sabemos, las variaciones nos dan la información sobre la dispersión de los puntos de datos. La prueba F también se usa en varias pruebas como el análisis de regresión, la prueba de Chow, etc.
- HA: Varianza del primer conjunto de datos> Varianza de un segundo conjunto de datos (para una prueba superior de una cola)
- HA: Varianza del primer conjunto de datos ≠ Varianza de un segundo conjunto de datos (para una prueba de dos colas)
Paso 2: Lo siguiente que tenemos que hacer es que necesitemos descubrir el nivel de importancia y luego determinar los grados de libertad tanto del numerador como del denominador. Esto nos ayuda a determinar sus valores críticos. El grado de libertad es el tamaño de la muestra -1.
Paso 4: Encuentre el valor crítico F de la tabla F con un grado de libertad y nivel de importancia.
Paso 5: Compare estos dos valores y si un valor crítico es menor que el valor F, puede rechazar la hipótesis nula.
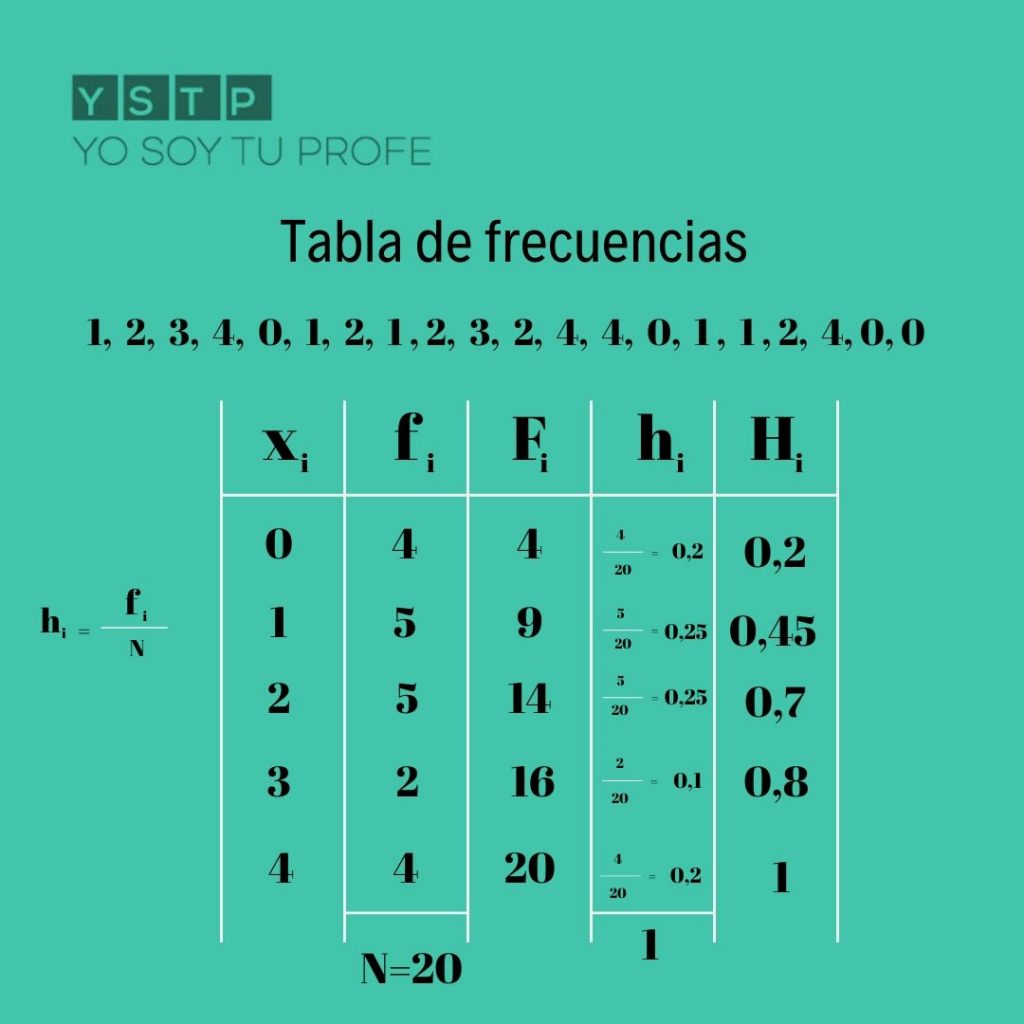
¿Cómo se saca el fi en una tabla de frecuencia?
Wikihow es un «wiki», similar a Wikipedia, lo que significa que muchos de nuestros artículos están coescritos por múltiples autores. Para crear este artículo, 12 personas, algunas anónimas, trabajaron para editarlo y mejorarlo con el tiempo.
Hay 9 referencias citadas en este artículo, que se pueden encontrar en la parte inferior de la página.
El cálculo de la frecuencia acumulativa le brinda la suma (o total de ejecución) de todas las frecuencias hasta cierto punto en un conjunto de datos. Esta medida es diferente de la frecuencia absoluta, que se refiere al número de veces que aparece un valor particular en un conjunto de datos. La frecuencia acumulativa es especialmente útil cuando se trata de responder una pregunta «más que» o «menos que» sobre una población, o para verificar si algunos de sus cálculos son correctos. Con algún orden de valores y adición, puede calcular rápidamente la frecuencia acumulativa para cualquier conjunto de datos que tenga.
- Ejemplo: escriba «número de libros» en la parte superior de la primera columna. Escriba «frecuencia» en la parte superior de la segunda columna.
- En la segunda fila, escriba el primer valor bajo el número de libros: 3.
- Cuente el número de 3s en su conjunto de datos. Dado que hay dos 3s, escriba 2 debajo de la frecuencia en la misma fila.
- Ejemplo: Nuestro valor más bajo es 3. El número de estudiantes que leen 3 libros es 2. Nadie lee menos que eso, por lo que la frecuencia acumulada es 2. Agregue a la primera fila de su tabla:
- Número de perros: discreto. No existe la mitad de un perro.
- Profundidad de nieve: continua. La nieve se acumula gradualmente, no en una unidad a la vez. Si intentas medirlo en pulgadas, es posible que encuentres un escote de nieve que tenía 5.6 pulgadas de profundidad.
- Por ejemplo, si su conjunto de datos va de 1 a 8, dibuje un eje X con ocho unidades marcadas en él. En cada valor en el eje x, dibuje un punto en el valor y que sea igual a la frecuencia acumulativa a ese valor. Conecte cada par de puntos adyacentes con una línea.
- Si no hay puntos de datos con un valor particular, la frecuencia absoluta es 0. Agregar 0 a la última frecuencia acumulativa no cambia su valor, por lo que dibuja un punto al mismo valor Y que el último valor.
- Debido a que la frecuencia acumulativa siempre aumenta junto con los valores, su gráfico de línea siempre debe mantenerse estable o subir a medida que se mueve hacia la derecha. Si la línea baja en cualquier momento, es posible que esté mirando la frecuencia absoluta por error.
- Mire el último punto en el extremo derecho de su gráfico. Su valor Y es la frecuencia acumulativa total, que es el número de puntos en el conjunto de datos. Digamos que este valor es 16
- Multiplique este valor por ½ y encuéntralo en el eje Y. En nuestro ejemplo, la mitad de 16 es 8. Encuentre 8 en el eje Y.
- Encuentre el punto en el gráfico de línea en este valor Y. Mueva el dedo del 8 en el eje Y a través del gráfico. Detente cuando tu dedo toque la línea de tu gráfico. Este es el punto donde se han contado exactamente la mitad de sus puntos de datos.
- Encuentra el eje X en este punto. Mueva el dedo hacia abajo para ver el valor del eje X. Este valor es la mediana de su conjunto de datos. Por ejemplo, si este valor es 65, la mitad de su conjunto de datos está por debajo de 65 y la mitad está por encima de 65.
- Para encontrar el valor del eje Y del cuartil inferior, tome la frecuencia acumulativa máxima y multiplique por ¼. El valor X correspondiente le indica el valor con exactamente ¼ de los datos debajo de él.
- Para encontrar el valor del eje Y del cuartil superior, multiplique la frecuencia acumulativa máxima por ¾. El valor X correspondiente le indica el valor con exactamente ¾ de los datos debajo y ¼ por encima de él.
Para calcular la frecuencia acumulativa, comience clasificando la lista de números de más pequeños a más grandes. Luego, agregue el número de veces que aparece cada valor en el conjunto de datos, o la frecuencia absoluta de ese valor. A continuación, encuentre la frecuencia acumulada de cada número contando cuántas veces se muestra ese valor o un valor más pequeño en el conjunto de datos. Para verificar su trabajo, agregue las frecuencias individuales juntas y confirme que es lo mismo que la frecuencia acumulativa final. Para consejos sobre gráficos de frecuencias absolutas, ¡siga leyendo!
¿Qué es F en probabilidad y estadística?
que se asocia con cada valor x { donnestyle x} asumido por la variable aleatoria x { dongestyle x} La probabilidad de que la variable x { donnestyle x} asuma exactamente ese valor. Además, la siguiente ecuación debe satisfacerse: σi = 1kenpx (xi) = 1 { splatyle sigma _ {i = 1}^{ infsty} p_ {x} (x_ {i}) = 1}
Para extender esta definición a toda la retta real, se supone que para cada valor x { dongestyle x} que x { donnestyle x} no puede tomar (es decir, no contenido en el apoyo de x { donnestyle x}) vale la pena 0, eso es:
Dado que S { displayStyle s}, el soporte de x { splatyle x}, es un conjunto numerable, el px (x) { displayslele p_ {x} (x)} es una función en todas partes.
En el caso de variables multivariadas discretas (es decir, con soporte de un subconjunto discreto de rn { dongestyle mathbb {r} ^{n}}) x = (x1, x2,…, xn) { displayStyle x = (x______ X_ {1}, x_ {2},…, x_ {n})}, la función de probabilidad conjunta se define de la siguiente manera:
El segundo miembro a menudo, por conveniencia de notación, se escribe más simplemente p (x1 = x1, x2 = x2,…, xn = xn) { splatyle p (x_ {1} = x_ {1}, x_ {2 } = x_ {2},…, x_ {n} = x_ {n})}
La función de probabilidad marginal del componente I-EMA se obtiene gracias al teorema de la probabilidad absoluta. Ser n = 2 por simplicidad; Luego de (x = t) = (x = t) ∩ω { splatyle (x = t) = (x = t) cap omega}
- px (x) = fx (x) −fx (x-) { splatyle p_ {x} (x) = f_ {x} (x) -f_ {x} (x {-})}, donde con fx ( x-) { dongestyle f_ {x} (x^{-})} está indicado el límite izquierdo del fx en x.
¿Qué es el valor crítico de F?
Como región de aceptación, en el nivel de significancia α, el intervalo entre las cuantales de orden α2 { splawyle { franc { alpha} {2}}}} y 1-α2 { displaystyle 1-{ franc is is is is es Tomado { alpha} {2}}}, mientras que la región de rechazo es la excluida:
Un valor perteneciente al intervalo] 0, Fα2 [{ dongestyle] 0, f _ { fratc { alpha} {2}} [} sugiere que la varianza de x es menor que la varianza de y, mientras que un valor perteneciente al intervalo] f1 –α2, ∞ [{ dongestyle] f_ {1-{ fratc { alpha} {2}}, infcty [} sugiere el reverso.
En el análisis de los datos, la prueba F se usa comúnmente para comparar los resultados obtenidos con dos métodos diferentes.
y evaluado con el admirador χ2 { splatyle chi ^{2}}. [2]
Si tiene dos variables χ12 { splatyle chi _ {1}^{2}} y χ22 { splatyle chi _ {2}^{2}} que siguen la distribución de χ2 { muestraStyle chi^{2 }} a ν1 { muestra nu _ {1}} y ν2 { dongestyle nu _ {2}} de los grados de libertad respectivamente, se puede construir la variable f { dongestyle f}:
donde f0 { dongestyle f^{0}} es el valor particular de f { splawyle f} obtenido.
El valor de pf { displayle p_ {f}} proporciona la probabilidad de encontrar un valor de f { displayStyle f} igual a f0 { displaysStyle f^{0}} o superior a partir de datos aleatorios si
χ12 { splatyle chi _ {1}^{2}} y χ22 { muestra chi _ {2}^{2}} Estoy de acuerdo.
Típicamente, la prueba f utilizada para χ2 { dongestyle chi ^{2}} compara dos ajustes aplicados a los mismos datos para comprender si uno es mejor que el otro.
Si el valor de PF { Dysplayle P_ {F}} es menor que el nivel de confianza elegido (por ejemplo, 5%), hay una diferencia significativa en la bondad de los dos ajustes.
¿Qué es un valor crítico de la función?
Un punto crítico de una función de una sola variable real, F (x), es un valor x0 en el dominio de F donde no es diferenciable o su derivada es 0 (F ‘(x0) = 0). [1] Un valor crítico es la imagen en F de un punto crítico. Estos conceptos se pueden visualizar a través del gráfico de F: en un punto crítico, el gráfico tiene una tangente horizontal si puede asignar uno.
Aunque se visualiza fácilmente en el gráfico (que es una curva), la noción de punto crítico de una función no debe confundirse con la noción de punto crítico, en alguna dirección, de una curva (ver más abajo para una definición detallada). Si G (x, y) es una función diferenciable de dos variables, entonces g (x, y) = 0 es la ecuación implícita de una curva. Un punto crítico de tal curva, para la proyección paralela al eje y (el mapa (x, y) → x), es un punto de la curva donde ∂g∂y (x, y) = 0 { displaystyle { frac { parcial g} { parcial y}} (x, y) = 0}. Esto significa que la tangente de la curva es paralela al eje y, y que, en este punto, G no define una función implícita de x a y (ver teorema de la función implícita). Si (x0, y0) es un punto tan crítico, entonces x0 es el valor crítico correspondiente. Tal punto crítico también se llama punto de bifurcación, ya que, en general, cuando X varía, hay dos ramas de la curva en un lado de x0 y cero en el otro lado.
De estas definiciones se deduce que una función diferenciable (x) tiene un punto crítico x0 con valor crítico y0, si y solo si (x0, y0) es un punto crítico de su gráfico para la proyección paralela al eje x, con el mismo valor crítico y0. Si F no es diferenciable en x0 debido a que la tangente se vuelve paralela al eje y, entonces X0 es nuevamente un punto crítico de F, pero ahora (x0, y0) es un punto crítico de su gráfico para la proyección paralela a y- eje.
¿Qué es el valor de F en estadística?
El nivel de significación es el umbral que determina si un cierto resultado puede considerarse estadísticamente significativo. Precisamente por esta razón, los niveles de significación son un componente fundamental de la inferencia estadística. En este artículo descubrirá cómo elegir el más adecuado para su estudio.
Los niveles de significancia son un componente fundamental de la inferencia estadística. Sin embargo, a diferencia de otros valores, estos niveles no son calculados por el software, sino que deben ser determinados a priori por aquellos que realizan los análisis. Para obtener este valor, por lo tanto, no se necesita cálculo sino solo un pequeño razonamiento.
El nivel de significación es el umbral que determina si un cierto resultado puede considerarse estadísticamente significativo. Por lo tanto, es un número que se decide a priori, al hacer el diseño del estudio, y en los protocolos de investigación se informa en la sección dedicada a las estadísticas.
Por ejemplo, supongamos que desea comparar el puntaje medio alcanzado con el examen de estadísticas por dos grupos diferentes de estudiantes. El primero se compone de la asistencia del curso, la segunda por personas que no atienden. Analizando los datos, surge que los estudiantes que asisten han logrado una puntuación promedio de 26, mientras que las personas que no atienden de 24. Entonces, en la muestra hay una diferencia entre los dos puntajes promedio.
Para decir si esta diferencia también refleja una diferencia presente en las dos poblaciones (la de todas las asistentes al curso de estadísticas y la de todos los estudiantes que no atienden) o si se debe solo al azar, es necesario llevar a cabo una hipótesis o calcular un intervalo de confianza.
Artículos Relacionados:

