Los datos nominales se pueden analizar utilizando el método de agrupación. Las variables nominales de entrada se agrupan y se clasifican en diferentes categorías. Para cada categoría, calculamos el porcentaje o frecuencia (modo) de las variables de entrada. Después de este análisis, los datos nominales ahora se pueden interpretar como un gráfico de barras o un gráfico circular.
El análisis de los datos nominales se basa en el porcentaje y la distribución de frecuencia debido a su naturaleza cualitativa. Incluso si se organiza en orden ascendente o descendente, la media no se puede calcular.
Al analizar los datos nominales, los resumimos en una tabla de distribución de frecuencia, que muestra las categorías y sus recuentos. Es decir, la tabla enumera las respuestas y la cantidad de veces que aparecen en el conjunto de datos.
La tabla se puede analizar a través de algunas técnicas gráficas, a saber; Gráfico circular y gráfico de barras. Estas técnicas son aplicables tanto para todos los datos en la tabla como para una muestra seleccionada de él.
- Gráfico de barras
Un gráfico de barras se utiliza principalmente para analizar datos nominales. Representa gráficamente la frecuencia de cada respuesta como una barra que se eleva verticalmente desde el eje horizontal.
La altura de cada barra es directamente proporcional a la frecuencia de la respuesta correspondiente.
- Gráfico de barras
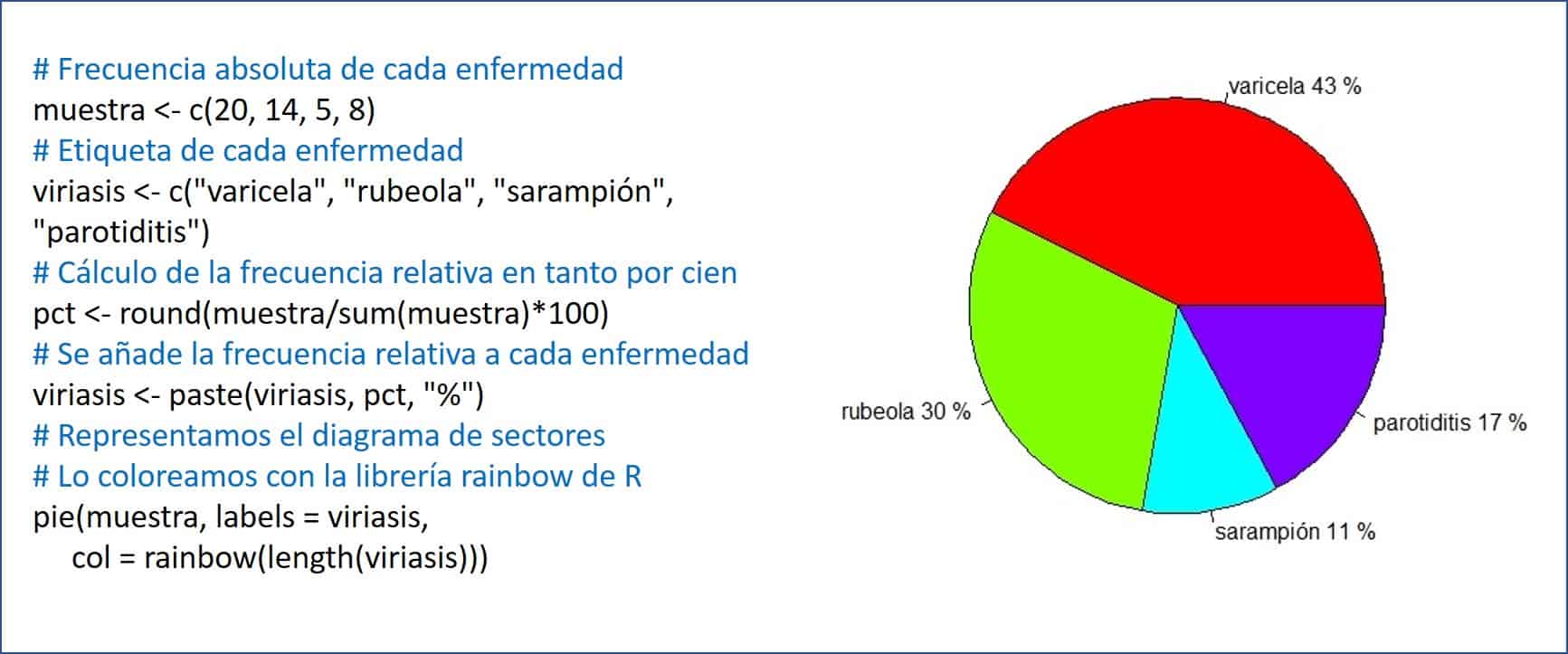
El gráfico circular también se usa para analizar datos nominales. Se utiliza para representar el porcentaje de frecuencia de cada muestra en un conjunto de datos nominales.
Aunque tanto el gráfico de barras como el gráfico circular se usan para analizar datos nominales, se usan en diferentes casos dependiendo del factor que se está considerando.
¿Qué es una variable cualitativa nominal en estadística?
«¿Qué procedimientos estadísticos necesito?» – Esta es, con mucho, la pregunta más común que se hace en el consejo estadístico. La selección del procedimiento estadístico depende esencialmente del nivel de escala de sus variables. El nivel de escala puede ser nominal, ordinario o métrico. Las variables nominales también pueden ser dicotoma, es decir, que solo tienen dos formas diferentes. A continuación encontrará los procedimientos más utilizados y qué tipos de hipótesis se pueden probar con ellos. Los métodos alternativos se pueden usar para variables dependientes ordinarias. Probablemente pueda determinar qué procedimientos estadísticos debe aplicar utilizando la siguiente lista de los procedimientos estadísticos más comunes.
Como recordatorio: la variable independiente (UV) es la variable influyente y la variable dependiente (AV) es la variable influenciada.
La prueba t para muestras independientes es adecuada para probar hipótesis con una variable dicotómica y una variable dependiente métrica.
El requisito previo es que se cumple al menos una de las siguientes condiciones:
- Distribución normal en variable dependiente
- Ambos grupos de muestra son mayores de 30
Ejemplo de hipótesis: en promedio, las mujeres y los hombres gastan diferentes cantidades de dinero en comida para gatos.
La prueba t para muestras unidas es adecuada para hipótesis, en la que se prueba una diferencia entre dos valores variables diferentes (métricos). En la mayoría de los casos, la diferencia se refiere a dos tiempos de medición diferentes de la misma variable.
¿Qué significa variables nominales en estadística?
Una variable nominal describe un nombre o categoría. A diferencia de una variable ordinal, los posibles nombres o categorías no siguen un orden natural. El sexo y el tipo de alojamiento son ejemplos. En la Tabla 1, el «modo de transporte para ir a trabajar» variable es una variable nominal, ya que describe una categoría de modo de transporte.
Una variable ordinal es una variable categórica llamada en la que las posibles categorías pueden clasificarse en un orden específico o en cualquier orden natural. En la Tabla 2, la variable de «comportamiento» es ordinal porque la categoría «excelente» es mejor que la categoría «muy buena», etc. Hay un cierto orden natural, pero está limitado por el hecho de que no sabemos en qué medida el comportamiento «excelente» es mejor que el comportamiento «muy bueno».
Una variable digital, también conocida como variable cuantitativa, es una variable que puede asumir un número infinito de números reales, como la edad o el número de miembros de un hogar. Sin embargo, no consideramos que todas las variables descritas por los números son variables digitales. Por ejemplo, cuando se le pide que indique su nivel de satisfacción mediante un valor que varía de 1 a 5, usa números, mientras que la variable de «satisfacción» es en realidad una variable ordinal. Las variables digitales pueden ser continuas o discretas.
¿Qué es nominal en estadistica ejemplos?
En estadísticas, los datos nominales (también llamados escala nominal) son un tipo de datos utilizado para etiquetar variables sin proporcionar un valor cuantitativo. Es la forma más simple de una escala de medición. Una de las características más notables de los datos ordinales es que los datos nominales no se pueden ordenar y no se pueden medir.
Aquí, ¿cuál es un ejemplo de datos nominales?
Los datos nominales se denominan datos que se pueden separar en categorías discretas que no se superponen. Un ejemplo común de datos nominales es el sexo; hombre y mujer. Otros ejemplos incluyen el color de los ojos y el color del cabello. Una manera fácil de recordar este tipo de datos son los sonidos nominales como nombrados, nominal = nombrado.
¿Sabe también cuál es la diferencia entre lo nominal y lo ordinal en estadísticas? Los datos nominales son un grupo de variables no paramétricas, mientras que los datos ordinales son un grupo de variables ordenadas no paramétricas. Aunque son variables no paramétricas, lo que las diferencia es el hecho de que los datos ordinales se colocan en una especie de orden por su posición.
La gente también pregunta, ¿qué es la medida nominal?
Alderman nominal: definición. Una escala nominal es una medición de escala, en la que los números se usan solo como «etiquetas» o «etiquetas», para identificar o clasificar un objeto. Una escalada nominal La medida normalmente trata con variables no digitales (cuantitativas) o cuando los números no tienen valor.
¿Cuándo se dice que una variable estadística es nominal y cuando es cuantitativa?
Aunque hay docenas de tipos de variables estadísticas, generalmente podemos encontrar dos tipos de variables:
- Variable cuantitativa: son variables que se expresan numéricamente.
- Variable continua: asume un valor infinito de valores entre un intervalo de datos. El momento en que un corredor necesita para el sprint de 100 metros.
- Variable discreta: asume un valor finito de valores entre un intervalo de datos. Número de helados vendidos.
- Variable cualitativa: son variables que generalmente se expresan en palabras.
- Variable ordinal: expresa diferentes niveles y orden. Por ejemplo, primero, segundo, tercero, etc.
- Variable nominal: expresa un nombre claramente diferenciado. Por ejemplo, el color de los ojos puede ser azul, negro, marrón, verde, etc.
Además, cada una de estas variables podría tener más tipos sub -tipos, ya que tenemos variables económicas, categóricas, dicotómicas, dependientes e independientes. Como ya se dijo, estos son muchos tipos de variables estadísticas. Por ejemplo, podríamos tener una variable estadística cuantitativa, discreta y dependiente.
Además, también tenemos que dejar en claro que el hecho de que las variables cualitativas con los nombres se expresan no significa que no puedan ser parte de un modelo matemático. Entonces podríamos crear una variable cuantitativa a partir de una variable cualitativa. Por ejemplo, podríamos asignar un 1 para el color de los ojos si tienes ojos azules, un 2 si tienes ojos verdes y un 3 si tienes ojos marrones. En otros casos, también podríamos convertir variables dicotómicas que muestren sí o no, en 1 o 0.
¿Cuándo se dice que una variable estadística es nominal?
En un nivel nominal, cada respuesta u observación se ajusta solo a una categoría.
Los datos nominales se pueden expresar en palabras o en números. Pero incluso si hay etiquetas numéricas para sus datos, no puede pedir las etiquetas de manera significativa o realizar operaciones aritméticas con ellos.
En la investigación científica social, las variables nominales a menudo incluyen género, etnia, preferencias políticas o número de identidad estudiantil.
- 2138
- 90210
- 1007
- Empleado
- Desempleados
- Comedia
- Drama
- Sátira
- Épico
- Tragedia
Las variables que se pueden codificar de solo 2 maneras (por ejemplo, sí/no o empleadas/desempleadas) se denominan binarias o dicotómicas. Dado que el orden de las etiquetas dentro de esas variables no importa, son tipos de variables nominales.
Los datos nominales se pueden recopilar a través de preguntas de encuesta abierta o cerrada.
Si la variable que le interesa tiene solo unas pocas etiquetas posibles que capturan todos los datos, use preguntas cerradas.
Si su variable de interés tiene muchas etiquetas posibles o etiquetas para las que no puede generar una lista completa, use preguntas abiertas.
- 2138
- 90210
- 1007
- Empleado
- Desempleados
- Comedia
- Drama
- Sátira
- Épico
- Tragedia
Para analizar datos nominales, puede organizar y visualizar sus datos en tablas y gráficos.
Luego, puede recopilar algunas estadísticas descriptivas sobre su conjunto de datos. Estos ayudan a evaluar la distribución de frecuencia y encontrar la tendencia central de sus datos. Pero no todas las medidas de tendencia o variabilidad central son aplicables a los datos nominales.
¿Cuando decimos que una variable es cuantitativa y cuando es cualitativa?
Ahora que hemos esbozado nuestro contexto, podemos entender cómo se calculan las variaciones.
Nota: En algunos casos, el mismo ejercicio se realiza desglosando la desviación total. La situación no cambia lógicamente, solo recuerde que la desviación es la varianza multiplicada por N.
Suma de todo el valor y dividido contando. Si tiene una tabla de entrada doble, multiplica los métodos cuantitativos por sus frecuencias asociadas y divide la suma final para n, que es el número total de observaciones.
Use el método indirecto y si necesita revisarlo, puede encontrarlo aquí. Él eleva el Xi al cuadrado y multiplica por sus frecuencias asociadas que obtienen una suma.
Divida la suma obteniendo el segundo momento en que es la primera parte de la varianza utilizando el método indirecto.
Lo prefiero al directo porque puede aprovechar la calculadora para un cálculo subsidiado.
Haga un segundo menos que el promedio del cuadrado obteniendo la varianza total. Esto explica cuánto los números tomé juntos. Ahora hay que entender si la división de cosas en los grupos de datos cambia.
Lo mismo que hizo para el promedio general del punto 1, replíquelo para cada grupo. Por ejemplo, si coloca los dos grupos en las líneas que se refieren a hombres y mujeres, calcule sus respectivos promedios.
Saber lo que está haciendo que recuerde que la varianza entre los grupos es una varianza de los medios de tamaño medio. En consecuencia, considere los promedios condicionales encontrados en el punto 3 como sus nuevas formas que tendrán sus respectivas frecuencias.
Artículos Relacionados:

