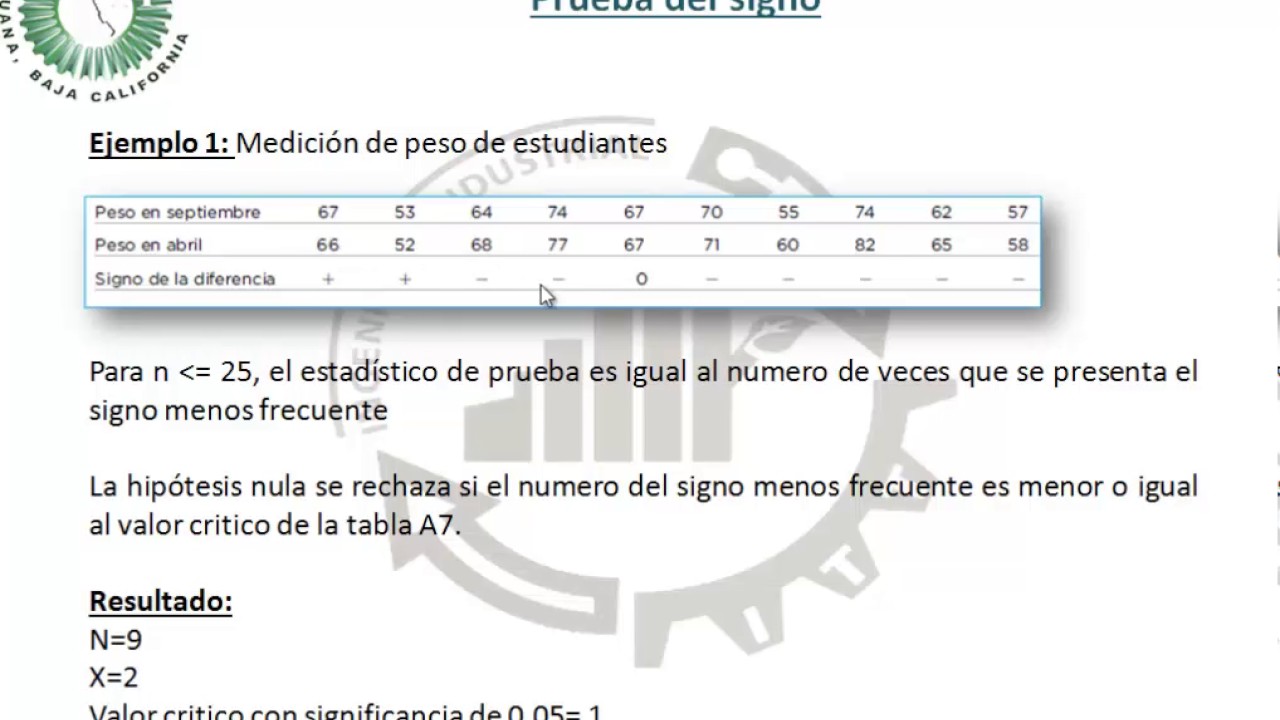
Supongamos que un investigador está interesado en estimar el número de bebés nacidos con ictericia en el estado de California. Se puede realizar un análisis del conjunto de datos tomando una muestra de 5,000 bebés. Una estimación de toda la población de bebés que llevan ictericia nacida al año siguiente es la medición derivada.
Para un segundo caso, considere dos grupos de diferentes investigadores. Están interesados en saber si el marketing general o el marketing comercial están asociados con la rapidez con que una empresa gana el posicionamiento de la marca. Suponiendo que el tamaño de la muestra se elige al azar, su distribución con respecto a qué tan rápido se da cuenta de que una empresa se da cuenta de un posicionamiento de marca es normal. Sin embargo, no se puede suponer que un experimento que mida los objetivos estratégicos de la compañía para abordar la dinámica del mercado (que también determina el posicionamiento de la marca) adquiere una distribución normal.
La idea principal detrás del fenómeno es que los datos seleccionados al azar pueden contener factores como la dinámica del mercado. En el otro extremo, si los factores como el segmento de mercado y la competencia entran en juego, no es probable que los objetivos estratégicos de la compañía afecten el tamaño de la muestra. Tal enfoque es efectivo cuando los datos carecen de una interpretación numérica clara.
Por ejemplo, las pruebas sobre si los clientes prefieren un producto en particular debido a su valor nutricional pueden incluir clasificar sus métricas como totalmente de acuerdo, de acuerdo, indiferente, en desacuerdo y totalmente en desacuerdo. En tal escenario, un método no paramétrico es útil.
El uso de enfoques de estadísticas no paramétricas en la investigación exige la debida diligencia en sus debilidades, fortalezas y posibles dificultades. Para la distribución de datos con exceso de curtosis o asimetría, las pruebas no paramétricas basadas en rango resultan ser más potentes que las pruebas paramétricas.
¿Qué estudia la estadística no paramétrica?
La práctica basada en la evidencia requiere que los médicos se mantengan al día con la literatura científica. Desafortunadamente, los profesionales de rehabilitación a menudo se enfrentan a la literatura de investigación que es difícil de interpretar clínicamente. Los datos de investigación clínica a menudo se analizan con probabilidad estadística tradicional (valores P), lo que puede no dar a los profesionales de rehabilitación suficiente información para tomar decisiones clínicas. Las diferencias o resultados estadísticamente significativos simplemente abordan si aceptar o rechazar una hipótesis nula o direccional, sin proporcionar información sobre la magnitud o dirección de la diferencia (efecto del tratamiento). Para mejorar la interpretación de la significación clínica en la literatura de rehabilitación, los investigadores comúnmente incluyen información más clínicamente relevante, como intervalos de confianza y tamaños de efecto. Es importante que los médicos puedan interpretar los intervalos de confianza utilizando tamaños de efectos, diferencias mínimas clínicamente importantes e inferencias basadas en la magnitud. El propósito de este comentario es discutir los diferentes aspectos del análisis estadístico y las determinaciones de la relevancia clínica en la literatura, incluida la validez, la importancia, el efecto y la confianza. Comprender estos aspectos de la investigación ayudará a los profesionales a utilizar mejor la evidencia para mejorar sus habilidades clínicas de toma de decisiones.
Se supone que la práctica basada en la evidencia afecta la toma de decisiones clínicas, pero interpretar la investigación a menudo es difícil para algunos médicos. La interpretación clínica de la investigación sobre los resultados del tratamiento es importante debido a su influencia en la toma de decisiones clínicas, incluida la seguridad y la eficacia del paciente. La publicación en una revista revisada por pares no implica automáticamente el diseño adecuado del estudio o estadísticas, o que la interpretación de los datos por parte del autor fue apropiada. Además, las diferencias estadísticamente significativas entre los conjuntos de datos (o la falta de ellos) pueden no siempre dar como resultado un cambio apropiado en la práctica clínica. La investigación clínica es solo de valor si se interpreta adecuadamente.
Desde una perspectiva clínica, la presencia (o ausencia) de diferencias estadísticamente significativas es de valor limitado. De hecho, un resultado no significativo no implica automáticamente el tratamiento no fue clínicamente efectivo porque los tamaños de muestra pequeños y la variabilidad de la medición pueden influir Con respecto a la aplicación del hallazgo de investigación, incluida la magnitud y la dirección de un resultado de tratamiento.
El propósito de este comentario clínico es discutir los diferentes aspectos del análisis estadístico y las determinaciones de la relevancia clínica en la literatura, incluida la validez, la importancia, el efecto y la confianza. Comprender estos aspectos de la investigación ayudará a los profesionales a utilizar mejor la evidencia para mejorar sus habilidades clínicas de toma de decisiones.
Los médicos deben poder evaluar críticamente la investigación para la validez interna y externa para determinar si un estudio es clínicamente aplicable. La validez interna refleja la cantidad de sesgo dentro de un estudio que puede influir en los resultados de la investigación. El diseño adecuado del estudio y el análisis estadístico son factores importantes para la validez interna. Para obtener información adicional sobre el diseño de investigación adecuado, se remite al lector al artículo «Diseños de investigación en fisioterapia deportiva» .2
¿Qué estudia la estadística paramétrica?
En general, se ha argumentado que las estadísticas paramétricas no deben aplicarse a los datos con distribuciones no normales. La investigación empírica ha demostrado que Mann-Whitney generalmente tiene mayor poder que la prueba t a menos que los datos se muestreen de lo normal. En el caso de los ensayos aleatorios, generalmente estamos interesados en cómo un punto final, como la presión arterial o el dolor, cambia después del tratamiento. Dichos ensayos deben analizarse utilizando ANCOVA, en lugar de la prueba t. Los objetivos de este estudio fueron: a) comparar el poder relativo de Mann-Whitney y Ancova; b) determinar si ANCOVA proporciona una estimación imparcial para la diferencia entre los grupos; c) Investigar la distribución de las puntuaciones de cambio entre las evaluaciones repetidas de una variable distribuida no normalmente.
Se desarrollaron polinomios para simular cinco distribuciones no normales arquetípicas para las puntuaciones de base y posterior al tratamiento en un ensayo aleatorizado. Los estudios de simulación compararon el poder de Mann-Whitney y ANCOVA para analizar cada distribución, tamaño de muestra variable, correlación y tipo de efecto del tratamiento (relación o cambio).
El cambio entre la línea de base sesgada y los datos posteriores al tratamiento tendían hacia una distribución normal. ANCOVA era generalmente superior a Mann-Whitney en la mayoría de las situaciones, especialmente donde los datos transformados log se ingresaron en el modelo. La estimación del efecto del tratamiento de ANCOVA no fue sesgada importante.
ANCOVA es el método preferido para analizar ensayos aleatorios con medidas de base y posteriores al tratamiento. En ciertos casos extremos, ANCOVA es menos poderoso que Mann-Whitney. En particular, en estos casos, la estimación del efecto del tratamiento proporcionado por ANCOVA es de interpretabilidad cuestionable.
¿Qué significa no paramétrica?
En matemáticas, una representación paramétrica o configuración de un conjunto es su descripción como una imagen conjunta de una o más variables y luego parámetros. Para un conjunto de puntos del plan o un espacio más grande provisto de un punto de referencia, la expresión de los diferentes componentes se descompone en restricciones en la configuración llamadas ecuaciones paramétricas.
El ejemplo introductorio muestra cómo es posible definir un conjunto geométrico de espacio utilizando una ecuación configurada de una línea. Esta propiedad no se limita a un derecho, un arco paramétrico también se define utilizando una ecuación de esta naturaleza. Por lo tanto, una hélice se define mediante una ecuación del tipo [2]:
La superficie es un objeto que puede estudiar utilizando dos parámetros simultáneamente: luego obtenemos un mantel configurado, para el cual los datos de U y V determinan un punto m (U, V). Si uno varía solo uno de los dos parámetros, el otro permanece en un valor fijo, obtenemos un arco configurado. De hecho, un mantel configurado puede concebirse como formado por una especie de «cerca» cuyos cables están establecidos.
Una configuración de la clase CK { displayStyle { mathcal {c}}^{k}} en el espacio vectorial de la dimensión terminada son los datos de un área u (generalmente supuestamente relacionada) de ℝ2 donde la pareja variará los parámetros reales (t , u) y una función f de u en e, de la clase ck { displaystyle { mathcal {c}}^{k}}
Artículos Relacionados:
- Libros sobre estadística no paramétrica: aprende a analizar datos sin suponer una distribución
- Aprende a optimizar tus datos con estadística no paramétrica
- Estadística paramétrica y no paramétrica: qué diferencias hay y cuál es mejor para tu estudio
- Ejemplos cortos de estadística descriptiva: aprenda a describir datos con estas técnicas

