- Hipótesis simple
- Hipótesis compleja
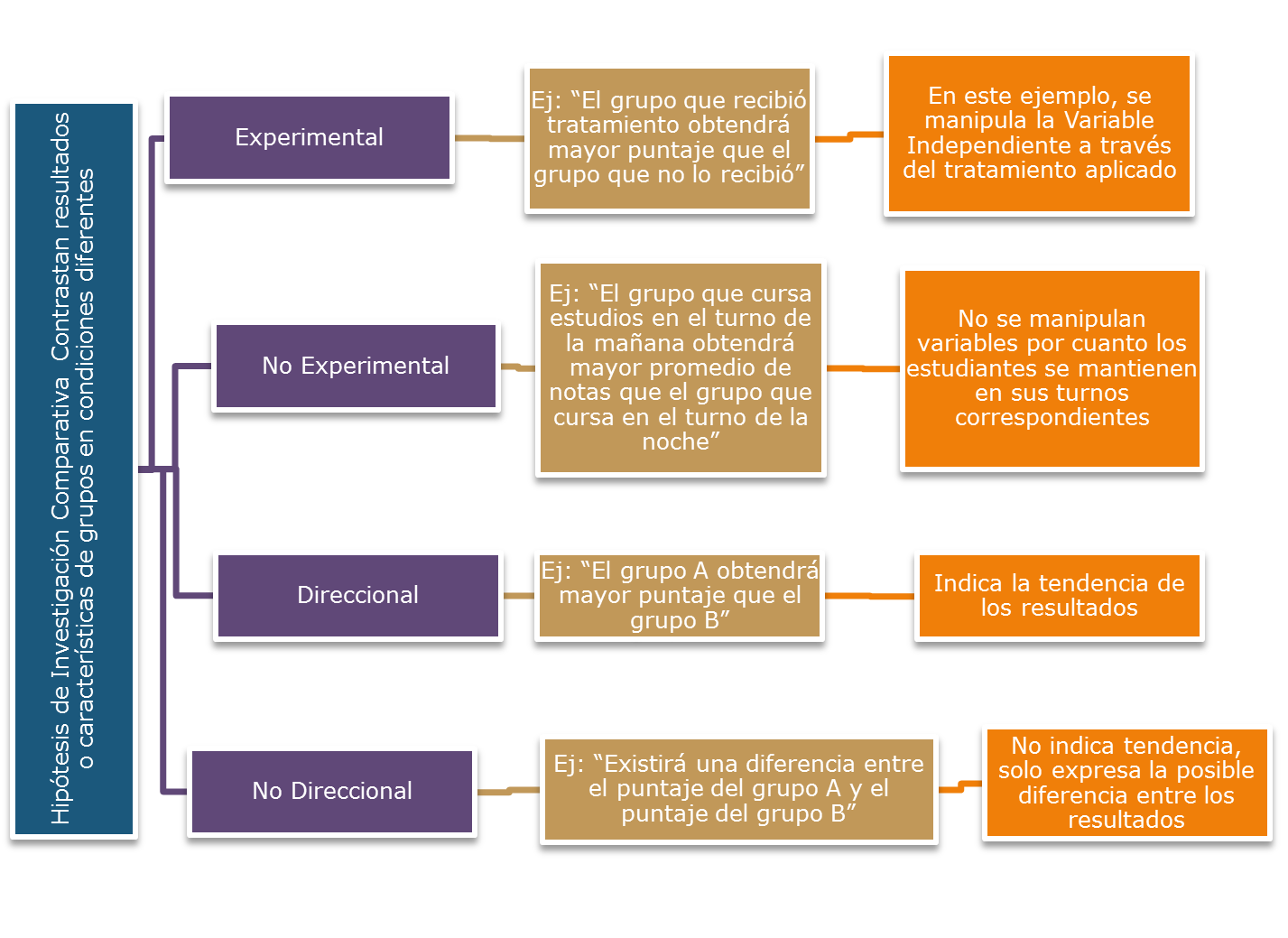
- Hipótesis de trabajo o investigación
- Hipótesis nula
- Hipótesis alternativa
- Hipótesis lógica
- Hipótesis estadística
Una hipótesis simple es una hipótesis que refleja una relación entre dos variables: variable independiente y dependiente.
- Hipótesis simple
- Hipótesis compleja
- Hipótesis de trabajo o investigación
- Hipótesis nula
- Hipótesis alternativa
- Hipótesis lógica
- Hipótesis estadística
Una hipótesis compleja es una hipótesis que refleja una relación entre más de dos variables.
- Hipótesis simple
- Hipótesis compleja
- Hipótesis de trabajo o investigación
- Hipótesis nula
- Hipótesis alternativa
- Hipótesis lógica
- Hipótesis estadística
Una hipótesis, que se acepta para probar y trabajar en la investigación, se llama hipótesis de trabajo. Es una hipótesis que se supone que es adecuada para explicar ciertos hechos y la relación de los fenómenos. Se espera que esta hipótesis genere una teoría productiva y se acepta para evaluar la investigación.
Simplemente puede ser cualquier hipótesis que inicialmente se acepte para trabajar en la investigación.
Si la hipótesis de trabajo se demuestra o se rechaza, se formula otra hipótesis (para reemplazar la hipótesis de trabajo) para explorar el aspecto deseado de la investigación, esto se conoce como una hipótesis alternativa.
¿Cuáles son las hipótesis más utilizadas?
Las pruebas de hipótesis son uno de los elementos más fundamentales de las estadísticas inferenciales. En idiomas modernos como Python y R, estas pruebas son fáciles de realizar, a menudo con una sola línea de código. Pero nunca deja de desconectarme cuán pocas personas los usan o entienden cómo funcionan. En este artículo, quiero usar un ejemplo para mostrar tres pruebas de hipótesis comunes y cómo funcionan bajo el capó, así como para mostrar cómo ejecutarlas en R y Python y comprender los resultados.
Las pruebas de hipótesis existe porque casi nunca es el caso que podamos observar a toda una población cuando intentamos llegar a una conclusión o inferencia al respecto. Casi siempre, estamos tratando de hacer esa inferencia sobre la base de una muestra de datos de esa población.
Dado que solo tenemos una muestra, nunca podemos estar 100% seguros de la inferencia que queremos hacer. Podemos ser 90%, 95%, 99%, 99.999%seguros, pero nunca 100%.
La prueba de hipótesis se trata esencialmente de calcular cuán seguros podemos estar sobre una inferencia basada en nuestra muestra. El proceso más común para calcular esto tiene varios pasos:
- Suponga que la inferencia no es cierta en la población, esto se llama hipótesis nula
- Calcule la estadística de la inferencia en la muestra
- Comprender la distribución esperada del error de muestreo en torno a esa estadística
- Use esa distribución para comprender la máxima probabilidad de que su estadística de muestra sea consistente con la hipótesis nula
- Use un «corte de probabilidad» elegido, conocido como alfa, para tomar una decisión binaria sobre si aceptar la hipótesis nula o rechazarla. El valor más utilizado de alfa es 0.05. Es decir, generalmente rechazamos una hipótesis nula si hace que la máxima probabilidad de que nuestra estadística de muestra sea inferior a 1 de cada 20.
Para ilustrar algunas pruebas de hipótesis comunes en este artículo, usaré el conjunto de datos de vendedores que se puede obtener aquí. Veamoslo en R y echemos un vistazo rápido a las primeras filas.
¿Qué tipos de hipótesis son las más comunes en una investigación por qué?
La generación de hipótesis es un paso importante y a menudo difícil en la aparición en la eclosión. Es mejor mantener la mente abierta y rastrillarse al generar hipótesis. Un buen punto de partida es determinar las exposiciones previamente asociadas con el patógeno dirigido por la encuesta. Para hacer esto, tienes que:
- Haga una búsqueda en una base de datos sobre eclosión, p. ex. Los informes del registro de eclosión, la base de datos Marler Clark o la base de datos en línea sobre la eclosión de alimentos de los Centros para el Control y la Prevención de Enfermedades (CDC) (consulte la sección sobre Herramientas;
- Consulte la literatura sobre el tema utilizando un motor de búsqueda como PubMed o Google Scholar.
Si la definición de casos de la enfermedad sujeta a una encuesta incluye información de subtipo de laboratorio en forma de perfil de electroforesis en el campo pulsado, puede ser aconsejable determinar dónde y cuándo se observó previamente el perfil. Los laboratorios de salud pública provinciales y federales tienen bases de datos de perfiles de electroforesis de campo pulsado que pueden contener información valiosa para las necesidades de un brote. Pulsenet Canada puede proporcionar información sobre la prevalencia de un perfil a nivel nacional, así como sobre el lugar donde se observó por última vez y la fecha, y puede indicar si este perfil se ha detectado en muestras de alimentos en el pasado. Además, Pulsenet Canada tiene acceso a las bases de datos de los perfiles de electroforesis de pulsenet Pulsenet en los Estados Unidos. También puede consultar el sistema FoodNet Canada y sus sitios centinela para averiguar si el perfil ya se ha observado en granjas o en muestras minoristas.
Ciertamente es importante recopilar tales datos históricos, pero el medio más efectivo para generar una hipótesis de alta calidad es identificar una fuente común de exposición entre los casos. Puede llegar a cuestionar los casos utilizando un cuestionario exploratorio y realizando un análisis de las exposiciones.
Artículos Relacionados:

