Como analista de datos, el objetivo de un análisis factorial es reducir el número de variables para explicar e interpretar los resultados. Esto se puede lograr en dos pasos:
- extracción de factores
- rotación de factores
La extracción de factores implica tomar una decisión sobre el tipo de modelo y el número de factores para extraer. La rotación del factor viene después de que se extraen los factores, con el objetivo de lograr una estructura simple para mejorar la interpretabilidad.
Hay dos enfoques para la extracción de factores que provienen de diferentes enfoques para la partición de varianza: a) Análisis de componentes principales y b) Análisis de factores comunes.
A diferencia del análisis factorial, el análisis de componentes principales o la PCA suponen que no hay una varianza única, la varianza total es igual a la varianza común. Recuerde que la varianza puede dividirse en una varianza común y única. Si no hay una varianza única, la varianza común absorbe la varianza total (consulte la figura a continuación). Además, si la varianza total es 1, entonces la varianza común es igual a la comunalidad.
El objetivo de un PCA es replicar la matriz de correlación utilizando un conjunto de componentes que son menos combinaciones lineales y lineales del conjunto original de elementos. Aunque el siguiente análisis derrota el propósito de hacer un PCA, comenzaremos extrayendo tantos componentes como sea posible como un ejercicio de enseñanza y para que podamos decidir sobre el número óptimo de componentes para extraer más adelante.
¿Cómo se realiza un análisis factorial?
- Realice una revisión de la literatura para ayudarlo a elegir un modelo apropiado. Por ejemplo, puede elegir un diagrama o ecuaciones.
- Determine si los valores únicos son posibles para la estimación de los parámetros de población.
- Recolectar datos.
- Realice un análisis inicial de datos para verificar la presencia de problemas como datos faltantes, colinas o anomalías.
- Estimar los parámetros de la población.
- Determine si el modelo elegido funciona. Si el modelo no es aceptable, considere la posibilidad de llevar a cabo el análisis de los factores explicativos.
- Interpretar los resultados.
Como su nombre indica, el análisis factorial exploratorio se toma sin tener una hipótesis en mente. Es un proceso de investigación que ayuda a los investigadores a comprender si hay asociaciones entre las variables iniciales y, de ser así, dónde están y cómo se agrupan.
Se usa cuando no hay idea de la estructura de datos o el número de tamaño de un conjunto de variables. Se puede realizar utilizando los siguientes dos métodos:
- Realice una revisión de la literatura para ayudarlo a elegir un modelo apropiado. Por ejemplo, puede elegir un diagrama o ecuaciones.
- Determine si los valores únicos son posibles para la estimación de los parámetros de población.
- Recolectar datos.
- Realice un análisis inicial de datos para verificar la presencia de problemas como datos faltantes, colinas o anomalías.
- Estimar los parámetros de la población.
- Determine si el modelo elegido funciona. Si el modelo no es aceptable, considere la posibilidad de llevar a cabo el análisis de los factores explicativos.
- Interpretar los resultados.
¿Cuándo se hace adecuado utilizar un análisis factorial?
Al igual que el análisis del grupo implica agrupar casos similares, el análisis factorial implica agrupar variables similares en dimensiones. Este proceso se utiliza para identificar variables o construcciones latentes. El propósito del análisis factorial es reducir muchos elementos individuales en una menor cantidad de dimensiones. El análisis factorial se puede utilizar para simplificar los datos, como reducir el número de variables en los modelos de regresión.
La mayoría de las veces, los factores se rotan después de la extracción. El análisis factorial tiene varios métodos de rotación diferentes, y algunos de ellos aseguran que los factores sean ortogonales (es decir, sin correlacionarse), lo que elimina los problemas de multicolinealidad en el análisis de regresión.
El análisis factorial también se usa para verificar la construcción de escala. En tales aplicaciones, los elementos que componen cada dimensión se especifican por adelantado. Esta forma de análisis factorial se usa con mayor frecuencia en el contexto del modelado de ecuaciones estructurales y se conoce como análisis factorial confirmatorio. Por ejemplo, se podría realizar un análisis factorial confirmatorio si un investigador quisiera validar la estructura de factores de los rasgos de personalidad de los cinco grandes utilizando el inventario de los cinco grandes.
Alinear el marco teórico, la recopilación de artículos, sintetizar brechas, articular una metodología y plan de datos claros, y escribir sobre las implicaciones teóricas y prácticas de su investigación son parte de nuestros servicios integrales de edición de tesis.
- Rastree todos los cambios, luego trabaje con usted para lograr una escritura académica.
¿Cuándo se utiliza el análisis factorial?
El análisis factorial es una técnica de reducción y análisis de datos estadísticos que se esfuerza por explicar las correlaciones entre los resultados múltiples como resultado de una o más explicaciones o factores subyacentes. La técnica implica la reducción de datos, ya que intenta representar un conjunto de variables por un número menor.
El análisis factorial intenta descubrir los factores inexplicables que influyen en la co-variación entre múltiples observaciones. Estos factores representan conceptos subyacentes que no pueden medirse adecuadamente por una sola variable. Por ejemplo, varias medidas de actitudes políticas pueden estar influenciadas por uno o más factores subyacentes.
El análisis factorial es especialmente popular en la investigación de encuestas, en la que las respuestas a cada pregunta representan un resultado. Debido a que múltiples preguntas a menudo están relacionadas, los factores subyacentes pueden influir en las respuestas de los sujetos.
Debido a que el propósito del análisis factorial es descubrir los factores subyacentes que explican las correlaciones entre los resultados múltiples, es importante que las variables estudiadas estén al menos algo correlacionadas; De lo contrario, el análisis factorial no es una técnica analítica apropiada.
El análisis factorial requiere el uso de una computadora, generalmente con un programa de software estadístico, como SAS o SPSS. El programa de hoja de cálculo de Excel no puede realizar un análisis factorial sin un programa que amplíe sus capacidades estadísticas.
Un programa que permite a Excel realizar un análisis estadístico más complejo, como el análisis factorial, es XLSTAT, que se puede comprar en línea.
¿Cuándo aplicamos análisis factorial y cuando componentes principales?
El análisis factorial y el análisis de componentes principales identifican patrones en las correlaciones entre variables. Estos patrones se utilizan para inferir la existencia de variables latentes subyacentes en los datos. Estas variables latentes a menudo se denominan factores, componentes y dimensiones.
La aplicación más conocida de estas técnicas es identificar las dimensiones de la personalidad en psicología. Sin embargo, tienen una aplicación amplia en todo el análisis de datos, desde las finanzas hasta la astronomía. A nivel técnico, el análisis factorial y el análisis de componentes principales son técnicas diferentes, pero la diferencia es en el detalle más que en la amplia interpretación de las técnicas.
La siguiente tabla muestra una matriz de correlación de las correlaciones entre la visualización de programas de televisión en el Reino Unido en la década de 1970. Cada uno de los números en la tabla es una correlación. Esto muestra la relación entre la visualización del programa de TV que se muestra en la fila con la que se muestra en la columna. Cuanto mayor sea la correlación, mayor será la superposición en la visualización de los programas. Por ejemplo, la mesa muestra que las personas que miran a World of Sport con frecuencia tienen más probabilidades de ver el boxeo profesional con frecuencia que las personas que miran hoy. En otras palabras, la correlación de .5 entre el mundo del deporte y el boxeo profesional es más alta que la correlación de .1 entre hoy y el boxeo profesional.
¿Qué es el análisis factorial de segundo orden?
Estoy trabajando en un proyecto en el que estoy tratando de estimar un análisis factorial utilizando 9 variables de muñecas.
En un primer paso estimé un análisis factorial confirmatorio de primer orden, y no tuve problemas, pero cuando intento estimar
Un análisis factorial confirmatorio de segundo orden, el modelo ejecuta y ejecuta y ejecuta y me da el mensaje de que las iteraciones «no son cóncavas».
Debido a que todas las variables tienen dos categorías, utilizo el método ADF (sin distribución asimpótica),
Pero también intenté estimar el modelo utilizando el método (ml) combinado con la opción VCE (robuste) y con VCE (bootstrap). Tengo el mismo problema
Mi pregunta es la siguiente: ¿Qué significa este mensaje «no cóncavo»? ¿Qué tengo que hacer?
Ilustra el método a continuación utilizando un conjunto de datos falso. Para mayor comodidad en la ilustración, en lugar de usar el método de distribución asintóticamente sin distribución, uso la matriz de correlación tetracórica de las variables binarias manifiestas y uso -sem- con estadísticas resumidas en un marco separado. Comience en el comentario «Comience aquí» en la salida a continuación; La primera parte de la salida solo muestra la creación del conjunto de datos falso… (Acorto los nombres de las variables manifiestas y latentes para la brevedad, y solo uso nombres de variables de caso inferior para variables manifiestas).
Primero muestro que el CFA de segundo orden no puede converger (que es su problema). Luego, muestre que el modelo equivalente con tres covarianzas (en lugar de dos cargas de factores y una varianza de la variable latente de segundo orden) converge, que también es lo que observa con su conjunto de datos. Luego tomo los valores ajustados de las tres estimaciones de parámetros sensibles (las variaciones de los tres factores latentes de primer orden) y los uso para restringir las variaciones correspondientes en el CFA de segundo orden y voilà. (Cada paso del proceso está marcado con un comentario A // para que pueda seguir más fácilmente lo que está sucediendo).
¿Cómo se realiza el análisis factorial?
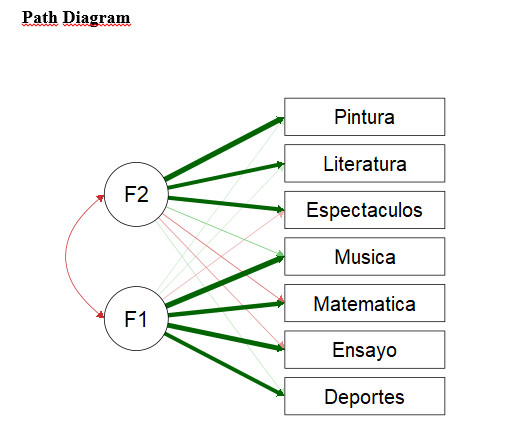
Matemáticamente, el análisis factorial implica el análisis de las variaciones y las covarianzas entre los ítems. Se supone que la varianza compartida entre los elementos representa la construcción. En el análisis factorial, las construcciones (las variaciones compartidas) se conocen comúnmente como factores. La varianza no compartida se considera la varianza de error. Durante un EFA, las covarianzas entre todos los elementos se analizan juntas, y los elementos que comparten una cantidad sustancial de varianza se colapsan en un factor. Durante un CFA, se extrae la varianza compartida entre los elementos que se especifican para medir la misma construcción subyacente. La Figura 1 ilustra EFA y CFA en un instrumento que consta de ocho variables observables (ítems) con el objetivo de medir dos construcciones (factores): F1 y F2. En EFA, no hay una suposición a priori de qué elementos representan qué factores son necesarios: la EFA determina estas relaciones. En CFA, el investigador especifica la varianza compartida de los ítems 1–4 para representar F1, y la varianza compartida de los ítems 5–8 se especifica para representar F2. Aún más, parte de lo que CFA prueba es que los ítems 1–4 no representan F2, y los ítems 5–8 no representan F1. Tanto para EFA como para CFA, la varianza no compartida se considera la varianza de error.
Figura 1. Ilustración conceptual de EFA y CFA. Las variables observadas (ítems 1–8) por cuadrados, y las construcciones (factores F1 y F2) están representadas por los óvalos. Los coeficientes de carga/patrón de factores que representan el efecto del factor en el elemento (es decir, la correlación única entre el factor y el ítem) se representan mediante flechas. σj, varianza para el factor J; EI, varianza de error única para el elemento i. El factor de carga para un elemento en cada factor se establece en 1 para dar a los factores una escala interpretable.
Las figuras que ilustran las relaciones entre elementos y factores (como la Figura 1) se interpretan de la siguiente manera. La flecha de doble cabeza entre los factores representa la correlación entre los dos factores (correlaciones de factores). Cada flecha individual entre los factores y los elementos representa la correlación única entre el factor y el ítem (llamado «coeficiente de patrón» en EFA y «carga de factores» en CFA). Los coeficientes de patrón y las cargas de factores son similares a los coeficientes de regresión en una regresión múltiple. Por ejemplo, considere el elemento de autopromoción en el instrumento de administración de objetivos de Diekman. El coeficiente de carga del factor/patrón para este elemento le dice al investigador cuánto de la respuesta promedio del encuestado sobre este elemento se debe a su interés general en los objetivos de la agente versus algo único sobre ese elemento (varianza de error). Para los lectores interesados en más detalles matemáticos sobre el análisis factorial, recomendamos Kline (2016), Tabachnick y Fidell (2013), o Yong y Pearce (2013).
Si un investigador decide que EFA es el mejor enfoque para analizar los datos, los resultados de la EFA idealmente deben confirmarse con un CFA antes de usar el instrumento de medición para la investigación. Esta confirmación nunca debe realizarse en la misma muestra que la EFA inicial. Hacerlo no proporciona información generalizable, ya que el CFA será (esencialmente) repitiendo muchas de las relaciones que se establecieron a través de la EFA. Además, podría haber algo matizado sobre la forma en que la muestra particular responde a los elementos que podrían no encontrarse en una segunda muestra. Por estas razones (entre otras), es la mejor práctica realizar una EFA y CFA en muestras independientes. Si un investigador tiene un tamaño de muestra lo suficientemente grande, esto se puede hacer dividiendo aleatoriamente la muestra inicial en dos grupos independientes. Tampoco es raro que un investigador que use una encuesta existente decida que un CFA es adecuado para comenzar, pero luego descubra que los datos no se ajustan al modelo teórico especificado. En este caso, está completamente justificado y se recomienda realizar una segunda ronda de análisis que comienzan con un EFA en la mitad de la muestra inicial seguida de un CFA en la otra mitad de la muestra (Bandalos y Finney, 2010).
Artículos Relacionados:

