Tanto Pearson como Spearman se usan para medir la correlación, pero la diferencia entre ellos radica en el tipo de análisis que queremos.
Correlación de Spearman: la correlación de Spearman evalúa la relación monotónica. El coeficiente de correlación de Spearman se basa en los valores clasificados para cada variable en lugar de los datos sin procesar.
Determinación de la asociación entre la circunferencia y la altura de los cerezos negros (utilizando el conjunto de datos existente «árboles» que ya está presente en R y se puede acceder escribiendo el nombre del conjunto de datos, la lista de todo el conjunto de datos se puede ver utilizando el comando datos() )
3. Prueba de suposiciones de correlación, aquí se verifican dos suposiciones que deben cumplirse antes de realizar la correlación (prueba de Shapiro, que se prueba para verificar la variable de entrada está siguiendo la distribución normal o no, se usa para verificar si las variables es decir, i.e. La circunferencia y la altura se distribuyen normalmente o no)
Dado que el valor p es inferior a 0.05 (para Pearson es 0.002758 y para Spearman, es 0.01306, podemos concluir que la circunferencia y la altura de los árboles se correlacionan significativamente tanto para los coeficientes con el valor de 0.5192801 (Pearson) como para 0.4408387 (Spearman).
Como podemos ver, los coeficientes de correlación dan el valor de correlación positivo para la circunferencia y la altura de los árboles, pero el valor dado por ellos es ligeramente diferente porque los coeficientes de correlación de Pearson miden la relación lineal entre las variables, mientras que los coeficientes de correlación de Spearman miden solo relaciones monotónicas, relaciones de relación, relación en el que las variables tienden a moverse en la misma dirección/opuesta, pero no necesariamente a una velocidad constante, mientras que la velocidad es constante en una relación lineal.
¿Cuándo utiliza Spearman?
Use la correlación de rango de Spearman para probar la asociación entre dos variables clasificadas, o una variable clasificada y una variable de medición. También puede usar la correlación de rango de Spearman en lugar de regresión lineal/correlación para dos variables de medición si le preocupan la no normalidad, pero esto generalmente no es necesario.
Use la correlación de rango de Spearman
Cuando tienes dos variables clasificadas, y quieres ver si las dos variables covary; ya sea,
A medida que aumenta una variable, la otra variable tiende a aumentar o
disminuir. También usa la correlación de rango de Spearman si tiene una variable de medición y una variable clasificada; En este caso, convierte la variable de medición en rangos y usa la correlación de rango de Spearman en los dos conjuntos de rangos.
Por ejemplo, Melfi y Poyser (2007) observaron el comportamiento de 6 monos colobos masculinos (Colobus generosa) en un zoológico. Al ver qué monos empujaron a otros monos fuera de su camino, pudieron clasificar a los monos en una jerarquía de dominio, desde la mayoría dominante a menos dominante. Esta es una variable clasificada; Si bien los investigadores saben que Erroll es dominante sobre Milo porque Erroll empuja a Milo fuera de su camino, y Milo es dominante sobre Fraiser, no saben si la diferencia en el dominio entre Erroll y Milo es mayor o menor que la diferencia en el dominio entre Milo y Fraiser. Después de determinar las clasificaciones de dominio, Melfi y Poyser (2007) contaron huevos de nematodos de Trichuris por gramo de heces de mono, una variable de medición. Querían saber si el dominio social se asociaba con el número de huevos de nematodos, por lo que convirtieron los huevos por gramo de heces a las filas y usaron la correlación de rango de Spearman.
¿Qué es Spearman y cuál es su utilidad?
Este artículo describe la correlación de rango de Spearman y cómo se usa para el análisis empresarial.
La correlación es una medida estadística que indica la medida en que dos variables fluctúan juntas una correlación positiva indica la medida en que esas variables aumentan o disminuyen en paralelo. Una correlación negativa indica la medida en que una variable aumenta a medida que la otra disminuye. La correlación de rango de Spearman es una medida de correlación entre dos variables clasificadas (ordenadas). Este método mide la fuerza y la dirección de asociación entre dos conjuntos de datos cuando se clasifican por cada una de sus cantidades.
Calculemos el coeficiente de correlación de rango de Spearman entre dos variables clasificadas X e Y que ilustrarán una correlación positiva:
Cuanto más cerca sea el valor de ± 1, más fuerte es la relación entre variables. Cuanto más cerca sea este valor para 0, más débil es la relación/asociación entre ambas variables.
¿Cómo es útil la correlación de rango de Spearman para el análisis de negocios?
Veamos dos casos de uso para ver la aplicación y el beneficio de la correlación de rango de Spearman.
Problema comercial: una organización educativa quiere evaluar la calificación de los estudiantes, basado en dos fuentes de observación diferentes.
Beneficio comercial: este análisis ayudará a la organización a evaluar la consistencia de las calificaciones proporcionadas por las dos fuentes de clasificación y observación de estudiantes. Si la clasificación dada por ambos observadores es similar, la organización puede poner más fe en las calificaciones que si la clasificación del observador varía ampliamente de uno a otro. Esto también reducirá la posibilidad de sistemas de clasificación sesgados o poco éticos.
¿Qué es el método Spearman?
Área de aplicación. El coeficiente de recuperación del rango utilizado para evaluar la calidad de la comunicación entre dos conjuntos. Además, su significación estadística se usa al analizar los datos para la heterogesticidad.
Ejemplo. En una muestra de datos de las variables observadas x e y:
- hacer una clasificación;
- Encuentre el coeficiente de correlación del rango de Spearman y verifica su significado en el nivel 2A
- evaluar la naturaleza de la adicción
- Solución. Asigne rangos a la función Y y al factor X.
En los casos en que las mediciones de las características estudiadas se llevan a cabo en una escala de pedido, o la forma de la relación difiere de la lineal, el estudio de la relación entre dos variables aleatorias se lleva a cabo utilizando coeficientes de correlación de rango. Considere el coeficiente de correlación del rango de Spearman. Durante el cálculo, es necesario clasificar (ordenar) las opciones de muestra. La clasificación es la agrupación de datos experimentales en cierto orden, creciendo o disminuyendo.
La operación de clasificación se realiza de acuerdo con el siguiente algoritmo:
1. Se le asigna un valor más bajo un rango más bajo. El valor más alto se asigna un rango correspondiente al número de valores clasificados. Al valor más pequeño se le asigna un rango de 1. Por ejemplo, si n = 7, entonces el valor más alto recibirá el número 7, excepto las disposiciones de la segunda regla.
¿Cuándo usar chi cuadrado o Pearson?
Los cursos de estadísticas, especialmente para los biólogos, asumen fórmulas = comprender y enseñar cómo hacer estadísticas, pero ignoran en gran medida lo que esos procedimientos suponen, y cómo sus resultados son incorrectos cuando esos supuestos no son razonables. El mal uso resultante es, digamos, predecible…
La prueba compite con la prueba t para ser la prueba estadística más utilizada en prácticamente todas las disciplinas. Varios autores (en particular Sokal & Rholf) han abogado por su reemplazo por la prueba de relación de probabilidad G. Dichas súplicas han caído en gran medida en oídos sordos (al menos para analizar las tablas 2 × 2), aunque hemos incluido un par de ejemplos de su uso. Quizás porque la prueba Chi Square de Pearson se usa tan ampliamente, también es uno de los procedimientos estadísticos más mal aplicados. Cuando se aplica a los resultados de los ensayos aleatorios de grupos, puede producir algunas de las inferencias más engañosas que se pueden encontrar en la literatura.
La falta de independencia del resultado es el factor más común que invalida la prueba. Esto puede surgir de varias maneras. Si las muestras se emparejan (ya sea en estudios anteriores a después o muestras coincidentes), entonces el cuadrado chi de Pearson no es la prueba apropiada. Damos ejemplos de tal uso indebido en un estudio antes de la incidencia de la malaria, y la presencia/ausencia de dos especies de ranas en pares de estanques naturales y artificiales. Otra causa de no independencia del resultado es el uso del muestreo de grupos. Damos ejemplos sobre el muestreo de cerdos de granjas y muestras de periwinkles usando cuadrantes. En experimentos, las frecuencias en la tabla de contingencia deben aplicarse al número de unidades que se asignaron aleatoriamente; no es válido cambiar la unidad experimental después de la aleatorización. Damos ejemplos en los que esto se hizo en los ensayos de una vacuna contra el cólera y de redes de mosquitos impregnadas de insecticidas. El mismo problema surge si las madres se asignan aleatoriamente, pero la prueba se aplica a la descendencia, ya sea de cerdos o parasitoides.
Un problema relacionado es el de la agrupación de frecuencias de múltiples tablas 2 × 2. Esto puede ser muy engañoso si las muestras no son homogéneas, y de todos modos está tirando datos sobre la variabilidad entre las réplicas. Damos varios ejemplos que incluyen infección de cerdos con tapeworms e infección de ardillas con virus. Múltiples tablas deben analizarse utilizando métodos Mantel Haenszel. Otro tipo de agrupación es hacerlo entre categorías de una tabla de contingencia, por ejemplo, colapsando, digamos una tabla 3 × 2 a tres tablas 2 × 2. Se debe tener mucho cuidado al hacer esto para garantizar que las categorías sin sentido no se creen en el proceso.
Existe un problema real sobre cómo lidiar con frecuencias esperadas muy pequeñas. La corrección de continuidad de los Yates hace que la prueba sea demasiado conservadora. Hasta hace poco, la sabiduría convencional era usar la prueba exacta de Fisher a pesar de que el modelo (totales marginales fijos) está mal. Mostramos en el texto central que una prueba exacta de Monte Carlo es muy preferible. Las diferentes opiniones entre los estadísticos introducen un sesgo porque uno puede elegir en qué prueba usar: ejemplos citados incluyen si un parasitoide se alimenta preferentemente en huéspedes y factores parasitados que afectan la infección con la influenza equina. Por último, debido a que la prueba Chi Square de Pearson a menudo se usa como prueba de asociación, uno debería enfatizar que la asociación nunca puede probar la causalidad, por fuerte que sea la asociación. Damos un ejemplo que cuestiona si el pobre estado de vitamina D hace que uno sea más susceptible a la tuberculosis o si la tuberculosis es responsable de la deficiencia de vitamina D observada.
¿Cuándo es mejor usar chi cuadrado y por qué?
Primero, Chi-Square solo prueba si dos variables individuales son independientes en un formato binario, «sí» o «no».
Las pruebas de chi-cuadrado no proporcionan ninguna idea del grado de diferencia entre las categorías de encuestados, lo que significa que los investigadores no pueden saber qué estadística (resultado de la prueba de chi-cuadrado) es mayor o menor que la otra.
En segundo lugar, Chi-cuadrado requiere que los investigadores usen valores numéricos, también conocidos como recuentos de frecuencia, en lugar de usar porcentajes o proporciones. Esto puede limitar la flexibilidad que los investigadores tienen en términos de los procesos que usan.
Las pruebas de chi-cuadrado se pueden ejecutar en Microsoft Excel o Google Sheets, sin embargo, hay paquetes de software estadísticos más intuitivos disponibles para los investigadores, como SPSS, Stata y SAS.
Hoy, cada organización recopila datos de retroalimentación, pero muy pocos actúan en consecuencia. Alchemer saca los datos de los paneles y los pone en manos de las personas que toman medidas. A través de los sistemas que usan todos los días. Con todas las barandillas para mantenerlo feliz. Aprende más
Este sitio web utiliza cookies para que podamos brindarle la mejor experiencia de usuario posible. La información de las cookies se almacena en su navegador y realiza funciones como reconocerlo cuando regresa a nuestro sitio web y ayuda a nuestro equipo a comprender qué secciones del sitio web le resulta más interesante y útil.
La cookie estrictamente necesaria debe habilitarse en todo momento para que podamos guardar sus preferencias para la configuración de cookies.
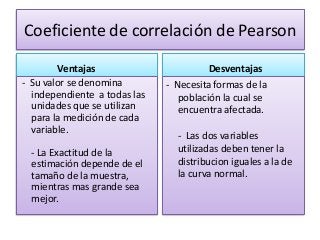
¿Cuándo es significativa la correlacion de Pearson?
Para establecer si una correlación es significativa, se hace referencia a la distribución de la muestra de R, elegida en tablas especiales, en correspondencia con los grados de libertad (n – 2) del coeficiente. Una correlación igual a 0 indica que no hay relación entre las dos variables.
En estadísticas, una correlación es una relación entre dos variables, de modo que cada valor del primero corresponde a un valor del segundo, siguiendo una cierta regularidad. La correlación no depende de una relación causa-efecto como de la tendencia de una variable a cambiar de acuerdo con otra.
¿Cómo se interpreta el coeficiente de correlación?
Un valor R positivo es una indicación de una correlación positiva, en la que los valores de las dos variables tienden a aumentar en paralelo. Un valor R negativo es una indicación de una correlación negativa, en la que el valor de una variable tiende a aumentar cuando la otra disminuye.
¿Qué significa una correlación entre dos variables iguales?
La correlación se refiere a una relación entre dos (o más) variables que cambian juntas. Una correlación positiva significa que si una variable aumenta (por ejemplo, el consumo de helado) la otra también aumenta. Una correlación negativa funciona en lo contrario: si uno aumenta el otro disminuye.
Para decidir que tiene que analizar sus datos con una prueba estadística. Si la prueba «le aconseja» que rechace la hipótesis cero, entonces la diferencia observada se declara estadísticamente significativa. Si, por otro lado, la prueba «recomienda» aceptar la hipótesis cero, entonces la diferencia no es estadísticamente significativa.
¿Cuándo se dice que la correlación es significativa al 0.05 de significancia?
Los valores p se malinterpretan con frecuencia, lo que causa muchos problemas. No repetiré esos problemas aquí, ya que hemos refutado las preocupaciones sobre los valores p en la Parte 1. Pero el hecho es que el valor p continuará siendo una de las herramientas más utilizadas para decidir si un resultado es estadísticamente importante.
Sabes la vieja sierra sobre «mentiras, malditas mentiras y estadísticas», ¿verdad? Suena cierto porque las estadísticas realmente se trata tanto de interpretación y presentación como matemáticas. Eso significa que los seres humanos que analizan datos, con todas nuestras debilidades y fallas, tenemos la oportunidad de sombrear y seguir la forma en que se informan los resultados.
La mayoría de nosotros encontramos los valores P cuando realizamos pruebas de hipótesis simples, aunque también son parte integral de muchos métodos más sofisticados. Usemos el software estadístico de Minitab para hacer una revisión rápida de cómo funcionan (si desea seguir y no tiene Minitab, el paquete completo está disponible gratis durante 30 días). Vamos a comparar el consumo de combustible para dos tipos diferentes de hornos para ver si hay una diferencia entre sus medios.
Vaya a Archivo> Abra la hoja de trabajo y haga clic en el botón «Busque la carpeta de datos de muestra de Minitab». Abra el conjunto de datos de muestra llamado Furnace.mtw y elija STAT> Estadísticas básicas> 2 Muestra t… En el menú. En el cuadro de diálogo, ingrese «btu.in» para muestras e ingrese «amortiguador» para ID de muestra.
Presione OK y Minitab Devuelve la siguiente salida, en la que he resaltado el valor p.
¿Cómo interpretar la correlación de Pearson en SPSS?
Esto significa que hay un fuerte
relación entre tus dos variables. Esto significa que cambian en uno
Las variables están fuertemente correlacionadas con los cambios en la segunda variable. En nuestro
Ejemplo, la R de Pearson es 0.985. Este número está muy cerca de 1. para esto
razón, podemos concluir que existe una fuerte relación entre nuestro
Variables de agua y piel. Sin embargo, no podemos hacer ninguna otra conclusión
sobre esta relación, basado en este número.
Esto significa que hay un débil
relación entre tus dos variables. Esto significa que cambian en uno
Las variables no están correlacionadas con los cambios en la segunda variable. Si nuestro
Las r de Pearson fueron 0.01, podríamos concluir que nuestras variables no eran
fuertemente correlacionado.
Esto significa que como una variable
aumenta en el valor, la segunda variable también aumenta en el valor. Similarmente,
Como una variable disminuye en el valor, la segunda variable también disminuye en
valor. Esto se llama una correlación positiva. En nuestro ejemplo, nuestro Pearson’s
El valor R de 0.985 fue positivo. Sabemos que este valor es positivo porque SPSS
No pusió un signo negativo frente a él. Entonces, positivo es el valor predeterminado.
Dado que nuestro ejemplo de R Pearson es positivo, podemos concluir que cuando el
La cantidad de agua aumenta (nuestra primera variable), la piel participante
La clasificación de elasticidad (nuestra segunda variable) también aumenta.
Esto significa que como una variable
aumenta en el valor, la segunda variable disminuye en el valor. Esto se llama un
correlación negativa. En nuestro ejemplo, el valor R de nuestro Pearson de 0.985 fue
positivo. Pero, ¿qué pasa si SPSS generó un valor R de Pearson de -0.985? Si SPSS
generó un valor R de Pearson negativo, podríamos concluir que cuando el
La cantidad de agua aumenta (nuestra primera variable), la piel participante
La clasificación de elasticidad (nuestra segunda variable) disminuye.
Puedes encontrar este valor en el
Caja de correlaciones. Este valor le dirá si hay una estadísticamente
Correlación significativa entre sus dos variables. En nuestro ejemplo, nuestro sig.
(2 colas) El valor es 0.002.
¿Qué es la correlacion de Pearson en SPSS?
Para calcular una correlación de fila, vaya a analizar | Correlacionar | Bivariado, verificación, en coeficientes de correlación, Spearmann y/o Kendall’s Tau-B. Las variables que han ingresado se correlacionarán y obtenemos una matriz completa, es decir, una tabla con todas las correlaciones de las variables dos por dos.
- Todo relacionado con la significativa: aún no se trata en el primer año
- Opciones: «Valores faltantes»: importantes solo si analizamos varias variables al mismo tiempo.
El diagrama de dispersión permite presentar la relación entre dos variables métricas. Cada punto en el gráfico representa un caso, es decir, un par de valores de dos variables. Para obtener un diagrama de dispersión, pase por gráficos | Dispersión: «simple». Por eso :
- Todo relacionado con la significativa: aún no se trata en el primer año
- Opciones: «Valores faltantes»: importantes solo si analizamos varias variables al mismo tiempo.
¡IDENTIFICACIÓN!)
Para obtener el número de un caso individual
En el editor gráfico:
- Todo relacionado con la significativa: aún no se trata en el primer año
- Opciones: «Valores faltantes»: importantes solo si analizamos varias variables al mismo tiempo.
¡IDENTIFICACIÓN!)
¿Cómo calcular la r de Pearson en SPSS?
He creado un conjunto de datos simple que contiene 10 filas de datos, cada fila significa una persona. Tengo dos variables, la primera edad (en años) y la otra son niveles de colesterol total en sangre (en MMOL/L).
No hay correlación entre las edades participantes y los niveles de colesterol total de sangre.
Por otro lado, la hipótesis alternativa se leería:
Existe una correlación entre las edades participantes y los niveles de colesterol total de sangre.
- Dentro de SPSS, vaya a analizar> Correlato> Bivariado.
Se abrirá una nueva ventana llamada correlaciones bivariadas. Aquí, debe especificar qué variables desea incluir en el análisis.
Arrastre ambas variables desde la ventana izquierda, a la ventana derecha llamadas variables. En este caso, tanto la edad como el colesterol serán trasladados. Tenga en cuenta que puede arrastrar más de dos variables en la prueba, y cada combinación es posible que se pruebe al mismo tiempo.
2. Asegúrese de que Pearson se vuelva a marcar los coeficientes de correlación del título. Dado que no hemos hecho suposiciones previas, también dejaremos la prueba de importancia como dos colas.
Al ir a la ventana de salida SPSS, habrá un nuevo rumbo de correlaciones con una matriz de correlación que se muestra.
Dentro de la cuadrícula, hay tres piezas de información que se enumeran a continuación.
- Dentro de SPSS, vaya a analizar> Correlato> Bivariado.
Artículos Relacionados:

