Definición: El muestreo no probabilidad se define como una técnica de muestreo en la que el investigador selecciona muestras basadas en el juicio subjetivo del investigador en lugar de la selección aleatoria. Es un método menos estricto. Este método de muestreo depende en gran medida de la experiencia de los investigadores. Se lleva a cabo por observación, y los investigadores lo usan ampliamente para la investigación cualitativa.
El muestreo no probabilidad es un método de muestreo en el que no todos los miembros de la población tienen las mismas posibilidades de participar en el estudio, a diferencia del muestreo de probabilidad. Cada miembro de la población tiene una oportunidad conocida de ser seleccionado. El muestreo no probabilidad es más útil para estudios exploratorios como una encuesta piloto (implementando una encuesta a una muestra más pequeña en comparación con el tamaño de la muestra predeterminado). Los investigadores usan este método en estudios donde es imposible dibujar un muestreo de probabilidad aleatorio debido a las consideraciones de tiempo o costo.
El muestreo de conveniencia es una técnica de muestreo no probable donde las muestras se seleccionan de la población solo porque están convenientemente disponibles para el investigador. Los investigadores eligen estas muestras solo porque son fáciles de reclutar, y el investigador no consideró seleccionar una muestra que represente a toda la población.
Idealmente, en la investigación, es bueno probar una muestra que representa a la población. Pero, en algunas investigaciones, la población es demasiado grande para examinar y considerar a toda la población. Es una de las razones por las cuales los investigadores confían en el muestreo de conveniencia, que es el método de muestreo no probable más común, debido a su velocidad, rentabilidad y facilidad de disponibilidad de la muestra.
Este método de muestreo de no probabilidad es muy similar al muestreo de conveniencia, con una ligera variación. Aquí, el investigador elige a una sola persona o un grupo de una muestra, realiza investigaciones durante un período, analiza los resultados y luego pasa a otro sujeto o grupo si es necesario. La técnica de muestreo consecutiva brinda al investigador la oportunidad de trabajar con muchos temas y ajustar su investigación recolectando resultados que tienen ideas vitales.
Hipotéticamente considere, un investigador quiere estudiar los objetivos profesionales de los empleados masculinos y femeninos en una organización. Hay 500 empleados en la organización, también conocidos como la población. Para comprender mejor sobre una población, el investigador solo necesitará una muestra, no toda la población. Además, el investigador está interesado en estratos particulares dentro de la población. Aquí es donde el muestreo de cuotas ayuda a dividir a la población en estratos o grupos.
En el método de muestreo de juicio, los investigadores seleccionan las muestras basadas exclusivamente en el conocimiento y la credibilidad del investigador. En otras palabras, los investigadores eligen solo aquellas personas que consideran adecuadas para participar en el estudio de investigación. El muestreo crítico o intencional no es un método científico de muestreo, y la desventaja de esta técnica de muestreo es que las nociones preconcebidas de un investigador pueden influir en los resultados. Por lo tanto, esta técnica de investigación implica una gran cantidad de ambigüedad.
¿Cuándo es un muestreo no probabilístico?
El error de no muestreo puede ocurrir en todos los aspectos del proceso de la encuesta, y puede clasificarse en las siguientes categorías: error de cobertura, error de medición, error de no respuesta y error de procesamiento.
El error de cobertura consiste en omisiones (encubiertos), inclusiones erróneas, duplicaciones y clasificaciones erróneas (excesivas) de unidades en el marco de la encuesta. Dado que afecta cada estimación producida por la encuesta, son uno de los tipos más importantes de errores. En el caso de un censo, puede ser la principal fuente de error. El error de cobertura puede tener dimensiones espaciales y temporales, y puede causar sesgo en las estimaciones. El efecto puede variar para diferentes subgrupos de la población. Este error tiende a ser sistemático y generalmente se debe a la cobertura, por lo que es importante reducirlo tanto como sea posible.
El error de medición, también llamado error de respuesta, es la diferencia entre los valores medidos y los valores verdaderos. Consiste en sesgo y varianza, y resulta cuando los datos se solicitan, proporcionan o registran los datos incorrectamente. Estos errores pueden ocurrir debido a las ineficiencias con el cuestionario, el entrevistador, el encuestado o el proceso de la encuesta.
- Diseño de cuestionario pobre
Es esencial que la encuesta de muestra o las preguntas del censo se redacten cuidadosamente para evitar la introducción de sesgos. Si las preguntas son engañosas o confusas, entonces las respuestas pueden terminar distorsionadas. - Sesgo del entrevistador
Un entrevistador puede influir en cómo un encuestado responde a las preguntas de la encuesta. Esto puede ocurrir cuando el entrevistador es demasiado amigable o distante o solicita al encuestado. Para evitar esto, los entrevistadores deben ser entrenados para permanecer neutrales durante la entrevista. También deben prestar mucha atención a la forma en que hacen cada pregunta. Si un entrevistador cambia la forma en que está redactada una pregunta, puede afectar la respuesta del encuestado. - Error al encuestado
Los encuestados también pueden proporcionar respuestas incorrectas. Los recuerdos defectuosos, las tendencias de exagerar o minimizar eventos, e inclinaciones a dar respuestas que parecen más socialmente aceptables son varias razones por las cuales un encuestado puede proporcionar una respuesta falsa. - Problemas con el proceso de encuesta
Los errores también pueden ocurrir debido a un problema con el proceso de encuesta real. El uso de respuestas proxy, lo que significa que tomar respuestas de alguien que no sea el encuestado, o que carece de control sobre los procedimientos de encuesta, son solo algunas formas de aumentar el riesgo de errores de respuesta.
Las estimaciones obtenidas después de la no respuesta se han observado y la imputación se ha utilizado para tratar con esta no respuesta, generalmente no son equivalentes a las estimaciones que se habrían obtenido si todos los valores deseados se hubieran observado sin error. La diferencia entre estos dos tipos de estimaciones se denomina error de no respuesta. Hay dos tipos de errores de no respuesta: total y parcial.
¿Cuando la muestra es probabilística?
Basado en los niveles de herramienta determinados, según GLN. (5) y (6) la fiabilidad predicha. La figura 11 muestra las funciones de confiabilidad R (t) de las herramientas en las velocidades de corte de VC = {300; 325; 350; 400} m/min junto con los niveles de herramienta medidos al alcanzar el ancho promedio de la marca de desgaste de espacio abierto de VB = 0.3 mm. Los valores medios calculados de las funciones de confiabilidad en el valor de confiabilidad de 0.5 corresponden a la vida útil prevista a cada velocidad de corte.
La pendiente de la función de confiabilidad aumenta con el aumento de la velocidad de corte de 300 a 400 m/min. Cuanto mayor sea la velocidad de corte, mayor es la disminución de la confiabilidad. Con la velocidad de corte de VC = 350 mm/min, el A-Posteriori debido a la función de los puntos de datos medidos no puede predecir adecuadamente los puntos de datos medidos en comparación con las otras funciones A-Posteriori. Esto se debe al mayor porcentaje de error determinado previamente, que usa la ecuación. (9) En la pestaña 2.
Los valores de confiabilidad predichos se resumen en la pestaña 3. Corresponden a los puntos de datos de nivel de herramienta medidos. La confiabilidad de la herramienta de fresado para las velocidades de corte de VC = {300; 325} m/min están más cerca del agente de funciones 0.5 debido a la predicción más precisa de los puntos de datos de prueba con estas velocidades de corte. Básicamente, la confiabilidad de la herramienta disminuye al aumentar la longitud de corte. Disminuye al aumentar la velocidad de corte. Finalmente, debe tenerse en cuenta que la probabilidad de incumplimiento de una herramienta de corte se puede determinar en un cierto período de corte utilizando la función de confiabilidad.
Los exámenes que se muestran incluyen la predicción probabilística del nivel de herramienta y el análisis de confiabilidad de una herramienta de fresado con velocidades de corte de 300 a 400 m/min. El método MCMC bayesiano se aplicó al modelo Taylor para determinar las distribuciones de probabilidad del nivel de herramienta. La cuantificación numérica y la minimización de la incertidumbre firme se llevaron a cabo utilizando el algoritmo de metrópolis de la simulación MCMC. Las distribuciones A-Priori se modelaron como distribuciones normales log. Las distribuciones A-Posteriori se actualizaron después de que los parámetros del modelo se actualizan utilizando dos niveles de herramienta medidos tm = {7.6; 48} min con las respectivas velocidades de corte de VC = {300; 400} m/min. Según la función de confiabilidad, se modeló y predijo un pronóstico de confiabilidad para lograr el ancho de la marca de desgaste especificado.
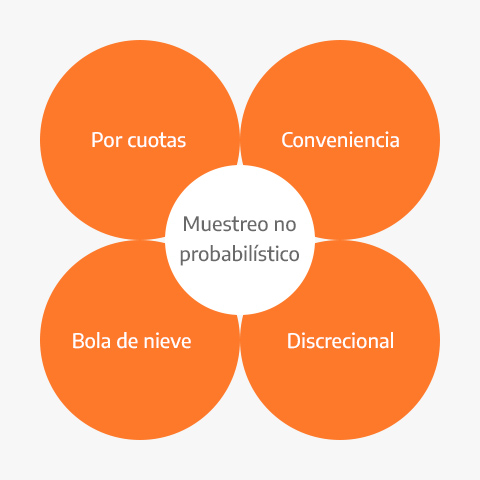
¿Cómo se divide el muestreo no probabilístico?
Muestra de muestra no testabilística, que no se extrajo de la población de acuerdo con los principios aleatorios, pero arbitraria o conscientemente, por ejemplo, una muestra ad hoc o una muestra de cuota.
Si tiene comentarios de contenido en este artículo, puede informar al equipo editorial por correo electrónico. Leemos su carta, pero le pedimos su comprensión de que no podemos responder a todos.
- los autores
El desarrollo conceptual y la implementación rápida, así como la cooperación óptima con los autores son el resultado de 20 años de publicación del gerente del proyecto. Gerd Wenninger es coeditor de The Handbook of Psychology, The Handbook of Media Psychology, The Handbook of Labor, Salud y Protección del Medio Ambiente y editor de la edición alemana del Manual de Psicoterapia. Es profesor privado en la Universidad Técnica de Munich, con un enfoque en la enseñanza y la investigación en el campo de la psicología ambiental y de seguridad. Además, trabaja independiente como consultor de gestión y entrenador de moderación.
Dr. Uwe Peter Kanning, Münster Dr. Jürgen Kaschube, Munich Prof. Dr. Heiner Keup, Munich Prof. Dr. Thomas Kieselbach, Hanover Prof. Dr. Erich Kirchler, Vienna Dr. Ellen Kirsch, Kiel Prof. Dr. Uwe Kleinbeck, Dortmund Dr. Regine Klinger, Prof. Dr. de Hamburgo Friedhart Klix, Berlín Prof. Dr. Rainer H. Kluwe, Hamburgo Nina Knoll, Berlín Stefan Koch, Munich Prof. Dr. Günter Köhnken, Kiel Dr. Ira Kokavecz, Münster Prof. Dr. Günter Krampen, Trier Prof. Dr. Jürgen Kriz, Osnabrück
Artículos Relacionados:
- Ejemplos de muestreo no probabilístico
- 5 tipos de muestreo no probabilistico que puedes utilizar en tu investigación
- Ejemplo de muestreo no probabilístico: Muestreo aleatorio simple
- Los beneficios del muestreo no probabilístico por conveniencia
- No probabilistico por cuotas: una forma de optimizar el rendimiento de tu inversión
- Ventajas y desventajas del muestreo no probabilístico

