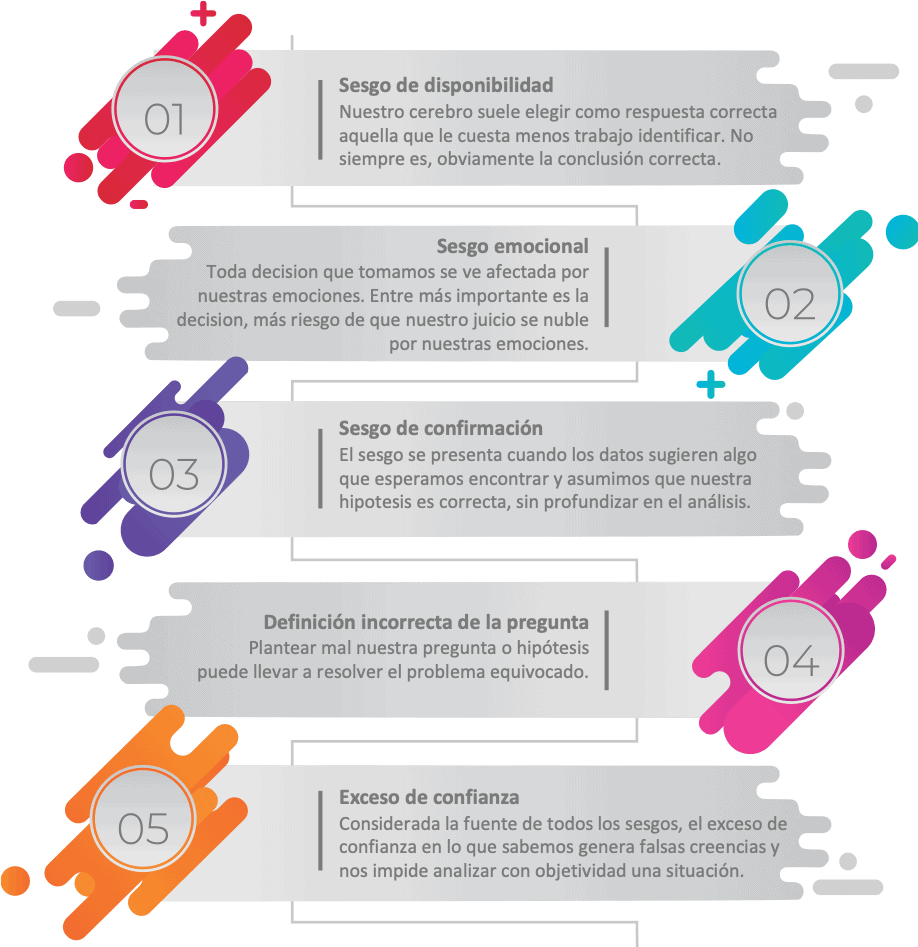
Los prejuicios inconscientes y las actitudes negativas hacia ciertos grupos de personas pueden comprometer una buena atención médica cuando esos prejuicios involucran a pacientes o dificultan el lugar de trabajo clínico. La investigación muestra que estos sesgos no expresados se pueden cambiar, pero las personas deben reconocer que los tienen en primer lugar.
Estas ocho tácticas, que explican «implícitos», pueden ayudarlo a mitigar sus propios prejuicios implícitos:
Introspección: explore e identifique sus propios prejuicios tomando pruebas de asociación implícitas o mediante otros medios de autoanálisis.
Mindfulness: dado que es más probable que cedas a tus prejuicios cuando estás bajo presión, practique formas de reducir el estrés y aumentar la atención plena, como la respiración enfocada.
Taking Perspective: Considere las experiencias desde el punto de vista de la persona que está estereotipada. Puede hacer esto leyendo o mirando contenido que discute esas experiencias o interactúa directamente con personas de esos grupos.
Aprenda a reducir la velocidad: antes de interactuar con personas de ciertos grupos, pausa y reflexione para reducir las acciones reflexivas. Considere ejemplos positivos de personas de ese grupo estereotipado, como figuras públicas o amigos personales.
Individuación: evalúe a las personas en función de sus características personales en lugar de aquellas afiliadas a su grupo. Esto podría incluir conectarse sobre intereses compartidos.
Consulte su mensajería: en lugar de decir cosas como «No vemos color», use declaraciones que dan la bienvenida y abarcan el multiculturalismo u otras diferencias.
¿Cómo se calcula el sesgo en Excel?
La fiabilidad del pronóstico o la precisión del pronóstico es un indicador clave en la planificación de la demanda. Si se elige correctamente y se mide correctamente, le permitirá reducir sus acciones, aumentar su tasa de servicio y reducir el costo de su cadena de suministro. Aprenda en 5 pasos cómo dominar las fórmulas de precisión de pronóstico e implementar el KPI adecuado en su negocio.
Puede descargar la calculadora de precisión de pronóstico utilizada en este artículo aquí:
Hay muchos métodos para medir la calidad de los pronósticos de ventas. Los estudié mucho: me rodeé de expertos, leí libros de referencia y los comparé con mis propias experiencias en el pronóstico de ventas. Llegué a la conclusión de que el método perfecto no existe y que las muchas soluciones existentes son como un laberinto de fórmulas matemáticas. Ordenarlos puede ser difícil.
Es por eso que lo mejor que debe hacer es elegir un método consistente que sea fácil de implementar y mantener, y que le permita estimar la calidad de sus pronósticos de ventas en una mirada.
Te guiaré paso a paso sobre cómo hacer esto, desde seleccionar los parámetros hasta los detalles del cálculo.
El primer paso es… tener un pronóstico de demanda o ventas. Puede sonreír, pero muchas compañías no tienen una. Si no tiene uno, simplemente comience con este cálculo: crecimiento promedio de ventas x estacionalidad x crecimiento. Si tiene un ERP u otro software, probablemente ya tenga pronósticos.
El pronóstico de ventas es un tema muy amplio, y no voy a entrar más en este artículo. Si tiene una necesidad específica en esta área, mi programa de «experto en pronóstico» (aún en proceso) proporcionará los mejores modelos de pronóstico para toda su cadena de suministro.
¿Cómo saber si unos datos tienen sesgo?
El primer paso clave para identificar el sesgo es comprender cómo se generaron los datos. Como he discutido anteriormente, una vez que se ha asignado el proceso de generación de datos, se pueden anticipar los tipos de sesgo y uno puede diseñar intervenciones para preprocesar datos u obtener datos adicionales. Otro paso clave es realizar análisis de datos exploratorios integrales (EDA) [16]. Las técnicas EDA se discuten en varios libros de texto y documentos.
Identificar y tratar con el sesgo social requiere técnicas especiales, algunas de las cuales haré referencia a continuación. Para el sesgo debido a los bucles de retroalimentación, un enfoque sería diseñar el sistema para aleatorizar una pequeña muestra de consultas. Por ejemplo, en una pequeña fracción de solicitudes (por ejemplo, 0.1%), los elementos se seleccionan y se presentan de manera aleatoria. Solo los datos para estas solicitudes se utilizan en capacitación y evaluación de modelos. A veces, esto no es factible debido a las preocupaciones de la experiencia del usuario. En estos casos, las técnicas de ponderación de propensión propuestas en [9] son un enfoque posible.
Para los sesgos en el contenido generado por los humanos, recientemente ha habido mucha investigación sobre la cuantificación de la discriminación y también en las técnicas de debiaes para mejorar la equidad. Recientemente, los puntos de referencia cuantifican la discriminación [20] e incluso los conjuntos de datos diseñados para evaluar la equidad de estos algoritmos [21] han surgido. El desafío, por supuesto, es mejorar la equidad sin sacrificar el rendimiento. Sin embargo, estas técnicas son típicamente específicas del conjunto de datos y la aplicación. En general, estas técnicas se dividen en una de las tres categorías:
- aquellos que usan el preprocesamiento de datos antes del entrenamiento
- Entrada durante el entrenamiento
- postprocesamiento después del entrenamiento
Sin embargo, el problema de los conjuntos de datos de capacitación severamente desequilibrados y la cuestión de cómo integrar las capacidades de debiaes en los algoritmos de IA siguen siendo en gran medida sin resolver [19]. Una investigación publicada recientemente [19] utiliza el procesamiento posterior después del entrenamiento y ha intentado la integración de las capacidades de debiasing directamente en un proceso de capacitación modelo que se adapta automáticamente y sin supervisión a las deficiencias de los datos de capacitación. Su enfoque presenta un algoritmo de aprendizaje profundo de extremo a extremo que simultáneamente aprende la tarea deseada, así como la estructura latente subyacente de los datos de capacitación. Aprender las distribuciones latentes de manera no supervisada permite descubrir sesgos ocultos o implícitos dentro de los datos de capacitación. Bolukbasi et al [15] describen un enfoque posterior al procesamiento para la incrustación de palabras de sesgo para mitigar el sesgo de género.
¿Cómo saber el sesgo de una gráfica?
Esta publicación de blog, proporcionada por TheIPR Behavioral Insights Research Center y escrita por el Dr. Terry Flynn y Tim Li, se basa en un trabajo de investigación de Yasmina Okan, Ph.D., Rocio Garcia-Retamero, Ph.D., Edward T. Cokely , Ph.D. y Antonio Maldonado, Ph.D.
- Para los medios de presentación de gráficos de barras, los valores dentro de la barra a menudo se creen incorrectamente como más probable que un valor equidistante fuera de la barra. Este sesgo se llama sesgo «dentro de la barra» y resulta de cómo percibimos formas y distancias.
- El sesgo «dentro de la barra» puede influir en la toma de decisiones, lo que resulta en juicios y decisiones más pobres.
- Los gráficos DOT no conducen al sesgo «dentro de la barra» y pueden ser más apropiados para la presentación de medios en forma gráfica.
Los gráficos son una forma valiosa de agregar atractivo visual y comunicar información complicada. Sin embargo, la interpretación de gráficos puede ser sesgada por cómo nuestros cerebros perciben y procesan formas y objetos. Los gráficos de barras que transmiten medios o promedios pueden conducir al sesgo «dentro de la barra», donde los valores dentro de la barra parecen ser incorrectamente más probables de que aquellos fuera de la barra. Este sesgo es especialmente problemático cuando el gráfico es una fuente clave de información para tomar decisiones importantes, como las de la salud. Los profesionales de las relaciones públicas deben evitar usar gráficos de barras para presentar medios si los gráficos se utilizan para hacer estimaciones y usar gráficos DOT en su lugar.
Los gráficos resumidos son una forma efectiva de presentar datos al público de una manera más atractiva y accesible. La interpretación correcta de la información presentada es esencial para la toma de decisiones bien informada. Sin embargo, la investigación ha demostrado que el procesamiento de gráficos de las personas puede ser sesgado por el diseño, lo que resulta en un juicio y decisiones más pobres.
¿Qué es el sesgo de una grafica?
Las visualizaciones de datos permiten a las personas explorar y comunicar fácilmente el conocimiento extraído de los datos. Los métodos de visualización van desde diagramas de dispersión estándar y gráficos de línea hasta sistemas interactivos intrincados para analizar grandes volúmenes de datos de un vistazo. Pero, ¿cómo podemos elaborar visualizaciones que comuniquen efectivamente la información correcta de nuestros datos? ¿Qué aspectos de los datos y el diseño deben unirse para desarrollar ideas precisas? La respuesta radica en la forma en que vemos el mundo: las personas usan sus sistemas visuales y cognitivos (es decir, nuestros ojos y cerebro) para extraer el significado de los datos visualizados. Sin embargo, las visualizaciones llamativas no siempre están optimizadas para ayudar a las personas a ver lo que importa. Este artículo revisa las prácticas comunes de visualización que pueden inhibir un análisis efectivo, por qué estos diseños son problemáticos y cómo evitarlos. La discusión ilustra la necesidad de comprender mejor cómo las visualizaciones pueden soportar el análisis de datos flexible y preciso al tiempo que mitigan las posibles fuentes de sesgo.
Mirando la tabla de barras en la Figura 1 probablemente lo convencerá de que un método funciona dos veces y el otro. Sin embargo, esta visualización es engañosa: la verdadera diferencia entre los métodos es solo del 5 por ciento. Las conversaciones y artículos con frecuencia presentan visualizaciones llamativas como esta: visualizaciones que, a pesar de la simplicidad de los datos, rompen varias reglas para la visualización de datos honestas y efectivas, exageran las diferencias entre los métodos y cuestionan las conclusiones estadísticas extraídas de los resultados. ¿Son nefastos estas violaciones? No. ¿Se han hecho con la intención de hacer un gráfico genial? Probablemente. ¿Se encuentran con esos datos? Sí.
Los errores cometidos en esta visualización, el uso innecesario de 3D, la falta de información de incertidumbre, los ejes que comienzan por encima de cero) son comunes en todo el mundo científico. La gente a menudo justifica estos diseños con comentarios como «He aprendido a leer estos cuadros correctamente» o «Si etiqueto mis ejes, nadie cometirá ese error». Si bien hay pequeñas diferencias individuales en cómo interpretamos las visualizaciones, todos tienen el mismo sistema visual, están sujetos a los mismos sesgos visuales y pueden ser engañados por las mismas ilusiones visuales. Y solo nos estamos engañando si asumimos de manera diferente.
¿Cómo saber el sesgo de un histograma?
Estoy tratando de demostrar que hay un sesgo en juzgar las conversaciones académicas. Hubo una competencia de conversaciones en las que se dieron 147 conversaciones en 23 secciones. En cada sección, había un juez que determinaba la mejor charla del grupo. Tengo una lista de los ganadores de cada sección, y creo que había un sesgo a las conversaciones dadas anteriormente en cada sección. He creado un histograma de los ganadores, que creo que debería ser plano, ya que debería ser bastante aleatorio qué persona gana en cada grupo, pero no parece ser así. Quiero aprender más sobre las estadísticas de cómo puedo probar esto o mostrar que puede existir un sesgo en las conversaciones anteriores. Aquí están los datos:
donde Winners_Pos es el orden del presentador en esa sección y Total_in_Group es el número total de presentaciones en ese grupo. He creado el siguiente histograma:
Que es simplemente la frecuencia de los ganadores basados en su orden en la presentación de su grupo. No estoy seguro de si realmente hay un sesgo calculable ya que hay muy pocos datos, pero tengo curiosidad sobre si esto es algo que puede probarse si existe.
Cuando no hay sesgo en un grupo de tamaño $ k $, cada posición $ 1,2, ldots, K $ tiene las mismas posibilidades de ganar. La posición esperada es $ mu (k) = (k+1)/2 $ y su varianza es $ V (k) = (k^2-1)/12 $.
Cuando, además, los resultados son independientes entre las secciones, cada una con tamaños $ k_i $ ($ i = 1,2, ldots, n = 23 $), la suma esperada de las posiciones ganadoras $ x_i $ es $ sum_ {i = 1}^n mu (k_i) $ y la varianza de las posiciones ganadoras es $ sum_ {i = 1}^n v (k_i) $. Con estas muchas secciones, la distribución de la suma de las posiciones ganadoras $ sum_ {i = 1}^n x_i $ será (con una excelente aproximación) aproximadamente normal. Esto proporciona una prueba simple basada en
¿Qué mide el sesgo?
Los prejuicios están dentro de nosotros. Podemos decirnos absolutamente a nosotros mismos contrarios a cualquier forma de discriminación, pero en nuestro inconsciente hotica una desconfianza de aquellos que son diferentes. Esto, al menos, es lo que afirman el Proyecto Impicit Scholars, dirigido por el profesor de psicología en la Universidad de Washington Anthony G. Greenwald. No se limitó a sí mismo, con su colega Mahzarin R. Banaji para escribir el libro «Blindspot: prejuicios ocultos de las buenas personas» (punto ciego: los prejuicios ocultos de las buenas personas). Desarrolló una prueba de asociación de prueba, IAT o implícita, que desde mediados de los finales monitorea las asociaciones de ideas entre caras y conceptos. La prueba se divide en ocho secciones, cada una de las cuales trata un tema de prejuicios: edad, raza, nacionalidad, género, discapacidad, color de la piel, peso, orientación sexual.
De alguna manera es similar a un videojuego. Una vez que sus datos han sido puestos y expresados sus preferencias políticas y religiosas, pasamos a la fase de la Asociación de Caras. Si a la izquierda está escrito «Magri» y a la derecha está escrito «gordo» y aparece la cara de una persona magra, haga clic en el botón izquierdo y viceversa con personas gordas. Entonces los conceptos están asociados con el mismo sistema. Para dar un ejemplo, a la izquierda se escribe «bien» y a la derecha «malo»; Si aparece la escritura «Gloria», se escribirá el botón de la izquierda, si el correcto aparecerá «malvado». Posteriormente, en la prueba, las fotos y conceptos están intercalados, con un par de pasajes que invierten la posición del bien y el mal y la división (para permanecer en el ejemplo del primero) entre Magri y Grassi. El jugo es este: si toma menos tiempo para asociar un concepto positivo con el bien después de que se haya asociado una cara delgada, tendrá una preferencia por las personas delgadas. Y viceversa.
¿Demasiado complicado? Aquí puede probar la prueba, alojada en el sitio web de la Universidad de Harvard. También está en italiano.
¿Qué trata de medir el sesgo?
El sesgo de respuesta aparece en muchos campos de la investigación del comportamiento y la salud donde se utilizan datos autoinformados. Demostramos cómo usar la estimación de frontera estocástica (SFE) para identificar el sesgo de respuesta y sus covariables. En nuestra aplicación a una intervención familiar, examinamos los efectos de la demografía participante en el sesgo de respuesta antes y después de la participación; El género y la raza/etnia están relacionados con la magnitud del sesgo y con los cambios en el sesgo a lo largo del tiempo, y el sesgo es menor en la prueba posterior que en la prueba previa. Discutimos cómo se puede usar SFE para abordar el problema del «sesgo de cambio de respuesta», es decir, un cambio en la métrica de antes a después de una intervención causada por la intervención misma y puede conducir a subestimaciones de los efectos del programa.
En este artículo, demostramos el potencial de una herramienta econométrica común, la estimación de fronteras estocásticas (SFE), para medir el sesgo de respuesta y sus covariables en los datos autoinformados. Ilustramos el enfoque utilizando medidas autoinformadas de los comportamientos de crianza antes y después de una intervención familiar. Demostramos que, además de afectar los comportamientos específicos, una intervención también puede afectar cualquier sesgo asociado con la autoevaluación de esos comportamientos. Mostramos que SFE puede usarse para identificar y corregir el sesgo en la autoevaluación tanto antes como después del tratamiento, lo que resulta en estimaciones más precisas de los efectos del tratamiento.
El sesgo de respuesta es un fenómeno ampliamente discutido en la investigación conductual y de atención médica donde se utilizan datos autoinformados; Ocurre cuando los individuos ofrecen medidas autoevaluadas de algún fenómeno. Hay muchas razones por las que las personas pueden ofrecer estimaciones sesgadas de comportamiento autoevaluado, que van desde un malentendido de lo que es una medida adecuada hasta el sesgo de desidenabilidad social, donde el encuestado quiere ‘verse bien’ en la encuesta, incluso si la encuesta es anónima. . El sesgo de respuesta en sí puede ser problemático en la evaluación y la investigación del programa, pero es especialmente problemático cuando causa una recalibración de sesgo después de una intervención. La recalibración de los estándares puede causar un tipo particular de sesgo de medición conocido como «sesgo de cambio de respuesta» (Howard, 1980). El sesgo del cambio de respuesta ocurre cuando el marco de referencia de un encuestado cambia a través de los puntos de medición, especialmente si el marco de referencia cambiado es una función del tratamiento o la intervención, por lo tanto, confundir el efecto del tratamiento con la recalibración de polarización. Más específicamente, una intervención puede cambiar la comprensión o la conciencia de los encuestados sobre el concepto objetivo y la estimación de su nivel de funcionamiento con respecto al concepto (Sprangers y Hoogstraten, 1989), cambiando así el sesgo en cada punto de medición. De hecho, algunos tratamientos o intervenciones tienen la intención de cambiar la forma en que los encuestados miran el concepto objetivo. Más complicando las cosas es que una intervención puede afectar no solo la métrica de un encuestado para los comportamientos específicos en los puntos de tiempo (que resulta en el sesgo de cambio de respuesta), sino que también puede afectar otros tipos de sesgo de respuesta. Por ejemplo, el sesgo de deseabilidad social puede disminuir en el transcurso de una intervención a medida que los encuestados llegan a conocer y confiar en un proveedor de servicios. Por lo tanto, es necesario comprender el grado y el tipo de sesgo de respuesta tanto en la prueba previa como en la prueba posterior para determinar si se ha producido el cambio de respuesta.
¿Qué es el sesgo y cómo se interpreta?
Por ejemplo, los sesgos de interpretación en línea pueden afectar el procesamiento y las reacciones inmediatas, mientras que un individuo está inmerso en una situación social, mientras que los sesgos fuera de línea pueden afectar el procesamiento posterior a los eventos y las decisiones sobre si participar en situaciones sociales futuras (Clark y Wells, 1995).
El sesgo de interpretación ocurre en maneras diferentes en pruebas de baja inferencia y alta inferencia con remedios potencialmente diferentes. El Rorschach en el formato RCS y el MMPI/MMPI-2 son pruebas de baja inferencia con sistemas de puntuación formales y datos normativos utilizados como marco de referencia para interpretar puntuaciones e índices de derivados. Los devotos europeos de RCS también usan el Rorschach como prueba de baja interpretación (Andronikof-Sanglade, 1999). El pre-RCS Rorschach y el TAT son pruebas de alta inferencia y el TAT se usó durante muchos años en los Estados Unidos sin beneficio de los puntajes formales (Rossini y Moretti, 1997) a pesar de una historia temprana de procedimientos de puntuación formal y datos normativos en España Dentro de un sistema de puntuación objetivo (Avila-Espada, 1999). Las puntuaciones TAT formales de baja inferencia ya están disponibles (Jenkins, 2008). En Europa, la controversia permanece con respecto al uso de Rorschach con especialistas en interpretación de alta inferencia que favorecen un enfoque psicoanalítico. La interpretación de alta inferencia puede emplear pruebas de hipótesis sistemáticas y rigurosas con una organización posterior de hipótesis a niveles descriptivos e inferenciales como base para la declaración de personalidad y diagnóstico. La interpretación de Rorschach y TAT de alta inferencia se basa en pautas para indicar cuándo se deben insertar marcadores formales o puntos de control en el proceso de análisis de datos para aumentar la confiabilidad de la interpretación (Dana, 1982, 2005). Los procedimientos de alta inferencia son análogos al uso de formulaciones culturales para aumentar la confiabilidad de los diagnósticos psiquiátricos (Dana, 1997). La elección de la interpretación de alta o baja influencia, como sugirió Handler (1996), puede basarse en la comodidad del evaluador con uno o ambos enfoques. Esta «comodidad» probablemente está relacionada con las características de personalidad del evaluador (ver Dana, 2000, Capítulo 1) que también puede resultar en preferencias para el control de la predicción o la comprensión como el objetivo principal de la ciencia psicológica. La interpretación que utiliza la interpretación de alta y baja inferencia es necesaria para una ciencia que honra tanto el control de la predicción como la comprensión, y esta reconciliación se puede lograr dentro de un modelo de evaluación multicultural (Dana, 1999).
Este sesgo es una variación del sesgo de interpretación mencionado anteriormente. Los niños leen historias de línea por línea. Se les dice que algunas de estas historias tienen un buen final y otras tienen un mal final, y su tarea es determinar lo más rápido posible qué finalización tiene cada historia. Alternativamente, declarado, los niños deben decidir lo antes posible si el final de una historia va a dar miedo o no. Es de destacar que este método de evaluación es en parte una prueba proyectiva, ya que aprovecha el estado existente de la red del niño para completar un patrón. Esta prueba activa el principio de red 6 con respecto a la finalización del patrón de parcialidad, que se analiza a continuación y en el Capítulo 4.
Artículos Relacionados:

