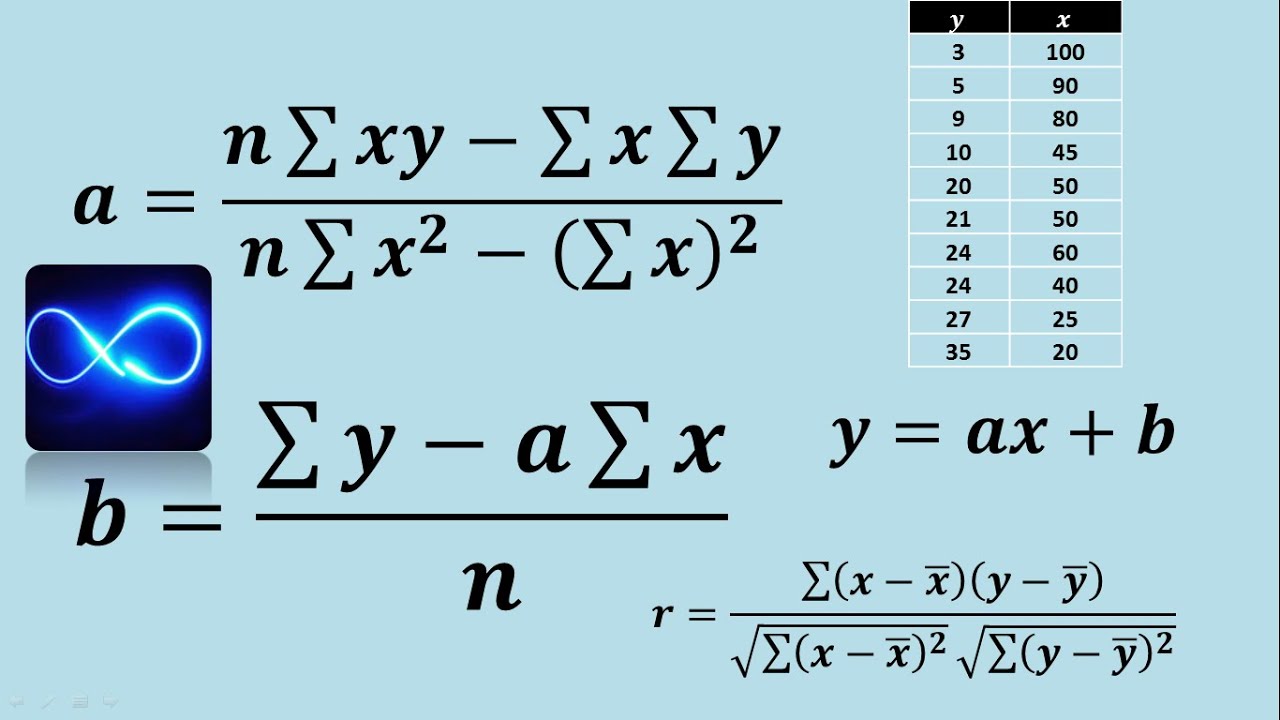
El análisis de regresión se trata de determinar cómo los cambios en las variables independientes se asocian con los cambios en la variable dependiente. Los coeficientes le dicen sobre estos cambios y los valores p le dicen si estos coeficientes son significativamente diferentes de cero.
Todos los efectos en esta publicación han sido los principales efectos, que es la relación directa entre una variable independiente y una variable dependiente. Sin embargo, a veces la relación entre un IV y un DV cambia en función de otra variable. Esta condición es un efecto de interacción. Obtenga más información sobre estos efectos en mi publicación: Comprender los efectos de interacción en las estadísticas.
Gracias por hacer explicaciones tan maravillosamente fáciles de entender sobre la regresión. Aunque estoy en la universidad, algunos de estos conceptos todavía me parecen esquivos.
¡Lo siento mucho si esta pregunta es larga, estaría muy agradecido por la ayuda! Me siento tan estúpido que no lo entiendo correctamente. Estoy haciendo una regresión ordinaria múltiple para un conjunto de variables x1, x2, x3, x4. La asignación es hacer conclusiones estadísticamente válidas, como si se fueran de verdad. He revisado la multicolinealidad. Lamento las matrices improvisadas, espero que sean legibles. Sabía que X4 estaba fuertemente correlacionado con Y antes de la mano, y lo uso como una variable de control.
Usando solo una variable independiente a la vez, obtengo (AR = R-cuadrado ajustado, C = coeficiente):
Todos los modelos tienen una constante, y no sé si es relevante, pero varía en valor, positivo y negativo, y a veces tiene un valor p <0.05 y, a veces, no. Hay 52 puntos de datos. Las variables son sobre el comportamiento humano, por lo que todas las r^2 parecen bastante altas. Realmente espero que X1 y X2 estén al menos un poco correlacionados con Y.
¿Qué es el coeficiente en una regresión lineal?
Hoy en día hay una gran cantidad de algoritmos de aprendizaje automático que podemos probar para encontrar el mejor ajuste para nuestro problema particular. Algunos de los algoritmos tienen una interpretación clara, otros funcionan como un Blackbox y podemos usar enfoques como cal o fase para derivar algunas interpretaciones.
En este artículo, me gustaría centrarme en la interpretación de los coeficientes del modelo de regresión más básico, a saber, la regresión lineal, incluidas las situaciones en las que se han transformado variables dependientes/independientes (en este caso, estoy hablando de transformación log).
Supongo que el lector está familiarizado con la regresión lineal (si no, hay muchos buenos artículos y publicaciones medianas), por lo que me centraré únicamente en la interpretación de los coeficientes.
La fórmula básica para la regresión lineal se puede ver anteriormente (omití los residuos a propósito, para mantener las cosas simples y al punto). En la fórmula, y denota la variable dependiente y X es la variable independiente. Por simplicidad, supongamos que es una regresión univariada, pero los principios obviamente también se mantienen para el caso multivariado.
Para ponerlo en perspectiva, digamos que después de ajustar el modelo que recibimos:
Desglosaré la interpretación de la intersección en dos casos:
- x es continuo y centrado (restando la media de x de cada observación, el promedio de x transformado se convierte en 0): el promedio y es 3 cuando X es igual a la media de muestra
¿Qué significa el coeficiente de regresion lineal?
En estadísticas, dada una muestra aleatoria, un modelo de regresión simple supone la siguiente relación de refino entre Yi y Xi:
La regresión lineal consiste en determinar una estimación de los valores A y B y cuantificar la validez de esta relación gracias al coeficiente de correlación lineal. Generalización (la generalización es un proceso que consiste en abstracto un conjunto de…) a P variable explicativa de este modelo (en las tecnologías de la información, una descripción elemental es una descripción elemental,…) por
Empíricamente, según las observaciones (la observación es la acción del monitoreo atento de los fenómenos, sin voluntad de…), hemos representado en un gráfico (el gráfico de la palabra tiene varios significados. Se usa en particular :) todo (en teoría De conjuntos, un conjunto designa intuitivamente una colección…) de estos puntos que representan medidas de una cantidad de Yi según otro XI, por ejemplo, el tamaño Yi de los niños según su edad XI.
Los puntos parecen alineados. Luego podemos proponer un modelo lineal, es decir, buscar el derecho cuya ecuación (en matemáticas, una ecuación es una igualdad que vincula diferentes cantidades, generalmente…) es yi = axi + b y que pasa lo más cerca posible a los puntos del gráfico.
Pasando (el pase de género fue creado por el zoólogo francés Mathurin Jacques…) lo más cerca posible, de acuerdo con el método de cuadrados más pequeños (el método de mínimo cuadrado, desarrollado independientemente por Legendre en…), es hacer mínimo el mínimo suma de los cuadrados de las diferencias de los puntos a la derecha
¿Cómo se interpreta el coeficiente de determinación en una regresión lineal?
Con y_i el valor del punto I, ^y_i el valor predicho para el punto I por regresión lineal, y_barre el promedio empírico de los puntos dados.
Este coeficiente está entre 0 y 1, y crece con la adecuación de la regresión al modelo:
– Si el R² está cerca de cero, la línea de regresión se adhiere al 0% con todos los puntos dados.
– Si el R2 de un modelo es 0.50, entonces la mitad de la variación observada en el modelo calculado puede explicarse por los puntos
– Si el R² es 1, entonces la regresión determina el 100% de la distribución de puntos. En la práctica, es imposible obtener un R2 de 1 a partir de datos empíricos. Consideramos que un cuadrado R es alto cuando está entre 0.85 y 1
En general, se usa un cuadrado en finanzas para seguir el porcentaje de variación de un fondo o un activo que se explica por los movimientos de otro índice, en índices de referencia particular como el S & P500.
La versión beta en las finanzas también es una medida de correlación de activos, títulos o índices, pero diferentes de Square R. De hecho, R-Carré mide en qué medida la variación en el precio de un activo se correlaciona con un índice de referencia. La beta mide la magnitud de estas variaciones de precios en comparación con un índice de referencia. Un título cuya beta es alta puede producir más rendimientos del índice de referencia, mientras que un alto cuadrado R muestra que la correlación con este índice es muy fuerte. Como recordatorio, para Beta, el punto de referencia es 1: si Beta es inferior a 1, el título es menos volátil que, mientras que si Beta es mayor que 1, el título es más.
¿Cómo se interpreta el coeficiente de regresión lineal?
El coeficiente de regresión lineal β1 asociado con un predictor X es la diferencia esperada en el resultado y al comparar 2 grupos que difieren en 1 unidad en X.
β1 es el cambio esperado en el resultado y por unidad de cambio en X. Por lo tanto, aumentar el predictor X en 1 unidad (o pasar de 1 nivel a otro) se asocia con un aumento en Y por las unidades β1.
La última interpretación implica que la manipulación de X conducirá a un cambio en y, que es una interpretación causal de la relación entre X e Y y, por lo tanto, debe evitarse a menos que:
- Sus datos provienen de un diseño experimental.
- Ha identificado y controlado el sesgo y los efectos de confusión.
Intentemos interpretar los coeficientes de regresión lineal para el siguiente ejemplo:
Supongamos que queremos estudiar la relación entre fumar y la frecuencia cardíaca, por lo que utilizamos el modelo de regresión lineal:
La siguiente tabla resume los resultados de ese modelo:
Observe que el coeficiente de fumar es estadísticamente significativo (p <0.05), lo que implica que dentro de los niveles de fumar debemos esperar diferentes velocidades cardíacas promedio.
¿Pero cómo interpretar la magnitud de esta relación?
Entonces β1 = 2.94 será la diferencia promedio en la frecuencia cardíaca entre fumadores y no fumadores.
Se espera que la frecuencia cardíaca de un fumador sea de 2.94 latidos por minuto más alta en comparación con un no fumador.
Tenga en cuenta que no dijimos que convertirse en un fumador aumenta su frecuencia cardíaca en 2.94 latidos por minuto. Esto se debe a que nuestros datos provienen de un estudio de observación y nuestro modelo no se ajusta por la confusión (si está interesado en este tema, vea un ejemplo de identificación y ajuste de confusión).
¿Qué indica el coeficiente de regresión?
Una regresión evalúa si las variables predictoras representan la variabilidad en una variable dependiente. Esta página describirá el análisis de regresión de preguntas de investigación, supuestos de regresión, la evaluación del R-cuadrado (coeficiente de determinación), la prueba F, la interpretación de los coeficientes beta (s) y la ecuación de regresión.
Preguntas de ejemplo respondidas por un análisis de regresión:
¿La edad y el género predicen las actitudes de regulación de armas?
¿Las cinco facetas de la atención plena influyen en los puntajes de la tranquilidad?
Alinear el marco teórico, la recopilación de artículos, sintetizar brechas, articular una metodología y plan de datos claros, y escribir sobre las implicaciones teóricas y prácticas de su investigación son parte de nuestros servicios integrales de edición de tesis.
- Rastree todos los cambios, luego trabaje con usted para lograr una escritura académica.
- Apoyo continuo para abordar los comentarios del comité, reduciendo las revisiones.
Primero, el análisis de regresión es sensible a los valores atípicos. Los valores atípicos se pueden identificar estandarizando los puntajes y verificando los puntajes estandarizados para valores absolutos superiores a 3.29. Dichos valores pueden considerarse valores atípicos y es posible que deba eliminarse de los datos.
En segundo lugar, los principales supuestos de regresión son la normalidad, la homoscedasticidad y la ausencia de multicolinealidad. La normalidad se puede evaluar examinando una gráfica P-P normal. Si los datos forman una línea recta a lo largo de la diagonal, se puede suponer normalidad. Para evaluar la homoscedasticidad, el investigador puede crear un diagrama de dispersión de valores predichos estandarizados de versos estandarizados. Si la trama muestra una dispersión aleatoria, se cumple la suposición. Sin embargo, si la dispersión tiene una forma de cono, entonces no se cumple la suposición. La multicolinealidad se puede evaluar mediante factores de inflación de varianza calculados (VIF). Los valores de VIF superiores a 10 indican que la multicolinealidad puede ser un problema.
¿Cómo se interpreta el R2?
El valor R cuadrado es la proporción de la varianza en la variable de respuesta que puede explicarse por las variables predictoras en el modelo.
El valor para R-cuadrado puede variar de 0 a 1 donde:
- Un valor de 0 indica que la variable de respuesta no puede explicarse por las variables predictoras.
- Un valor de 1 indica que la variable de respuesta puede explicarse perfectamente por las variables predictoras.
Aunque esta métrica se usa comúnmente para evaluar qué tan bien un modelo de regresión se adapta a un conjunto de datos, tiene un inconveniente serio:
R-cuadrado siempre aumentará cuando se agrega una nueva variable predictor al modelo de regresión.
Incluso si una nueva variable predictor está casi completamente no relacionada con la variable de respuesta, el valor R cuadrado del modelo aumentará, aunque solo sea por una pequeña cantidad.
Por esta razón, es posible que un modelo de regresión con una gran cantidad de variables predictoras tenga un alto valor R cuadrado, incluso si el modelo no se ajusta bien a los datos.
Afortunadamente, hay una alternativa a R-cuadrado conocido como R-cuadrado ajustado.
El R-cuadrado ajustado es una versión modificada de R-cuadrado que se ajusta para el número de predictores en un modelo de regresión.
- Un valor de 0 indica que la variable de respuesta no puede explicarse por las variables predictoras.
- Un valor de 1 indica que la variable de respuesta puede explicarse perfectamente por las variables predictoras.
Debido a que R-cuadrado siempre aumenta a medida que agrega más predictores a un modelo, el R-cuadrado ajustado puede decirle cuán útil es un modelo, ajustado para el número de predictores en un modelo.
¿Cómo se calculan los coeficientes de regresión?
La fórmula de regresión se utiliza para evaluar la relación entre la variable dependiente e independiente y descubrir cómo afecta la variable dependiente del cambio de la variable independiente y representada por la ecuación y es igual a Ax más B donde y es la variable dependiente, A es la pendiente de la ecuación de regresión, X es la variable independiente y B es constante.
- Y – es la variable dependiente
- X – es la variable independiente (explicativa)
- A – es la intersección
- B – Es la pendiente
- ∈ – y es el residual (error)
La fórmula para la intercepción «A» y la pendiente «B» se pueden calcular a continuación.
Introgemos ahora los valores en la fórmula de regresión para obtener regresión.
El Banco Estatal de la India estableció recientemente una nueva política de vincular la cuenta de la cuenta de ahorro a la tasa de interés de repos. Siempre que haya habido cambios en la tasa de repositorio. El siguiente es el resumen de la tasa de repo y la cuenta de ahorro del banco que prevaleció en esos meses se proporcionan a continuación.
El Auditor del Banco Estatal se ha acercado a usted para realizar un análisis y proporcionar una presentación sobre la misma en la próxima reunión. Use la fórmula de regresión y determine si la tasa del banco cambió a medida que se cambió la tasa de repositorio.
Análisis: Parece que State Bank of India está siguiendo la regla de vincular su tasa de ahorro con la tasa de repositorio, ya que hay algún valor de pendiente que indica una relación entre la tasa de repositorio y la tasa de cuentas de ahorro del banco.
Artículos Relacionados:

