Redman ofrece este escenario de ejemplo: suponga que es un gerente de ventas que intenta predecir los números del próximo mes. Sabes que docenas, tal vez incluso cientos de factores, desde el clima hasta la promoción de un competidor y el rumor de un modelo nuevo y mejorado, pueden afectar el número. Quizás las personas en su organización incluso tienen una teoría sobre lo que tendrá el mayor efecto en las ventas. «Confía en mí. Cuanto más lluvia tenemos, más vendemos «. «Seis semanas después de la promoción del competidor, salto de ventas».
El análisis de regresión es una forma de resolver matemáticamente cuál de esas variables tiene un impacto. Responde a las preguntas: ¿Qué factores importan más? ¿Cuál podemos ignorar? ¿Cómo interactúan esos factores entre sí? Y, quizás lo más importante, ¿qué tan seguros estamos sobre todos estos factores?
En el análisis de regresión, esos factores se denominan variables. Tiene su variable dependiente: el factor principal que está tratando de comprender o predecir. En el ejemplo de Redman anterior, la variable dependiente son las ventas mensuales. Y luego tiene sus variables independientes: los factores que sospecha tienen un impacto en su variable dependiente.
Para realizar un análisis de regresión, recopila los datos sobre las variables en cuestión. (Recordatorio: es probable que no tenga que hacerlo usted mismo, pero es útil que comprenda el proceso que utiliza su colega de datos). Las variables independientes que le interesan. Entonces, en este caso, digamos que también descubre la lluvia mensual promedio durante los últimos tres años. Luego trazas toda esa información en un gráfico que se ve así:
El eje Y es la cantidad de ventas (la variable dependiente, lo que le interesa, siempre está en el eje Y) y el eje X es la lluvia total. Cada punto azul representa los datos de un mes, mucho mucho ese mes y cuántas ventas realizó ese mismo mes.
¿Qué hace un análisis de regresión?
Y es la variable dependiente, que representa una cantidad que varía de individual a
individuo en toda la población, y es el foco principal de interés. X1,…,
XK son las variables explicativas (las llamadas «independientes
variables ”), que también varían de un individuo a otro, y se cree que están relacionados
a Y. Finalmente, ε es el término residual, que representa el efecto compuesto de todos
Otros tipos de diferencias individuales no identificadas explícitamente en el modelo. [2]
Además del modelo, la otra entrada en un análisis de regresión son algunos datos de muestra relevantes,
que consisten en los valores observados de las variables dependientes y explicativas para una muestra de
miembros de la población.
El resultado principal de un análisis de regresión es un conjunto de estimaciones de la regresión
Coeficientes α, β1,…, βk. Estas estimaciones están hechas por
Encontrar valores para los coeficientes que hacen el promedio residual 0 y la desviación estándar de
el término residual lo más pequeño posible. El resultado se resume en la predicción
ecuación:
Ejemplo: ajuste el modelo anterior a los datos de motor, obtenemos:
Costoped = 107.34 + 29.65 Kilometraje + 73.96 Edad + 47.43 Make.
(Sumérgete para una discusión adicional de los supuestos
Análisis de regresión subyacente, o examinar un libro de trabajo
que ilustra algunos de los cálculos subyacentes).
Por lo general, se realiza un análisis de regresión para uno de dos propósitos: para predecir el valor
de la variable dependiente para individuos para quienes alguna información sobre la explicación
Las variables están disponibles, o para estimar el efecto de alguna variable explicativa en el
variable dependiente.
¿Qué quiere decir una regresión?
El análisis de regresión se usa cuando desea predecir un dependiente continuo
variable de varias variables independientes. Si la variable dependiente es
Dicotómica, entonces la regresión logística debe usarse. (Si la división entre el
Dos niveles de la variable dependiente están cerca de 50-50, luego tanto logísticos como
La regresión lineal terminará dándole resultados similares.) El independiente
Las variables utilizadas en la regresión pueden ser continuas o dicotómicas.
Las variables independientes con más de dos niveles también se pueden usar en la regresión
análisis, pero primero deben convertirse en variables que solo tienen dos
niveles. Esto se llama codificación ficticia y se discutirá más adelante. Normalmente,
El análisis de regresión se usa con variables naturales, en lugar de
variables manipuladas experimentalmente, aunque puede usar regresión con
variables manipuladas experimentalmente. Un punto a tener en cuenta con la regresión
El análisis es que las relaciones causales entre las variables no se pueden determinar.
Si bien la terminología es tal que decimos que X «predice» y no podemos decir
que x «causa» Y.
Al hacer regresión, la relación de las variables de casos a independientes (IVS) debe
Idealmente, ser 20: 1; Eso es 20 casos para cada IV en el modelo. El más bajo tu
La relación debe ser 5: 1 (es decir, 5 casos para cada IV en el modelo).
Si ha ingresado los datos (en lugar de usar un conjunto de datos establecido), es un
Buena idea verificar la precisión de la entrada de datos. Si no quieres volver a verificar
Cada punto de datos, al menos debe verificar el valor mínimo y máximo para
Cada variable para garantizar que todos los valores para cada variable sean «válidos». Para
Ejemplo, una variable que se mide utilizando una escala 1 a 5 no debe tener un
valor de 8.
¿Qué es un análisis de regresión lineal?
La regresión lineal es un algoritmo que proporciona una relación lineal entre una variable independiente y una variable dependiente para predecir el resultado de eventos futuros. Es un método estadístico utilizado en ciencia de datos y aprendizaje automático para el análisis predictivo.
La variable independiente también es la variable predictor o explicativa que permanece sin cambios debido al cambio en otras variables. Sin embargo, la variable dependiente cambia con fluctuaciones en la variable independiente. El modelo de regresión predice el valor de la variable dependiente, que es la respuesta o la variable de resultado que se analiza o estudia.
Por lo tanto, la regresión lineal es un algoritmo de aprendizaje supervisado que simula una relación matemática entre variables y hace predicciones para variables continuas o numéricas como ventas, salario, edad, precio del producto, etc.
Este método de análisis es ventajoso cuando hay al menos dos variables disponibles en los datos, como se observa en el pronóstico del mercado de valores, la gestión de la cartera, el análisis científico, etc.
Una línea recta inclinada representa el modelo de regresión lineal.
Aquí, se traza una línea para los puntos de datos dados que se ajustan adecuadamente a todos los problemas. Por lo tanto, se llama la «mejor línea de ajuste». El objetivo del algoritmo de regresión lineal es encontrar esta mejor línea de ajuste vista en la figura anterior.
La regresión lineal es una herramienta estadística popular utilizada en la ciencia de datos, gracias a los diversos beneficios que ofrece, como:
El modelo de regresión lineal es computacionalmente fácil de implementar, ya que no exige muchos gastos generales de ingeniería, ni antes del lanzamiento del modelo ni durante su mantenimiento.
¿Qué significa la regresión?
Análisis de regresión. La regresión a la media se trata de cómo se igualan los datos. Básicamente establece que si una variable es extrema la primera vez que la mida, estará más cerca del promedio la próxima vez que la mida. En términos técnicos, describe cómo una variable aleatoria que está fuera de la norma eventualmente tiende a volver a la norma. Por ejemplo, sus probabilidades de ganar en una máquina tragamonedas se mantienen igual. Puede alcanzar una «racha ganadora» que, técnicamente, es un conjunto de variables aleatorias fuera de la norma. Pero juegue la máquina el tiempo suficiente, y las variables aleatorias retrocedirán a la media (es decir, «volver a la normalidad») y terminará perdiendo.
El Jinx Sports Illustrated es un excelente ejemplo de regresión a la media. El Jinx afirma que quien aparezca en la portada de SI tendrá un pobre año siguiente (o años). Pero el «Jinx» es en realidad la regresión hacia la media. La mayoría de los jugadores tienen buenos juegos y tienen malos juegos. Una racha ganadora suele ser solo eso: una racha de suerte. Y lleva a estar en la portada de SI. Pero es estadísticamente probable que sea seguido por una caída hacia el rendimiento promedio.
La regresión a la media generalmente ocurre debido al error de muestreo. Una buena técnica de muestreo es probar aleatoriamente de la población. Si no lo hace (es decir, si muestra asimétricamente), sus resultados pueden ser anormalmente altos o bajos para el promedio y, por lo tanto, volverían a la media. La regresión a la media también puede ocurrir porque se toma una muestra muy pequeña y no representativa (por ejemplo, el 1 por ciento más alto de la población o el diez por ciento más bajo).
Puede usar la siguiente fórmula para encontrar el porcentaje de cualquier conjunto de datos:
¿Por qué 1-R? Nota: Para comprender esta discusión, debe estar muy familiarizado con R, el coeficiente de correlación.
¿Cuál es el concepto de regresión?
La «regresión» proviene de la palabra «regresión», derivada de la palabra latina «regresión», que significa «volver» (a algo). Por lo tanto, la regresión es la técnica que te ayuda a «retroceder» de un conjunto de datos confusión y difícil de entender a un modelo más simple y más significativo.
La regresión es una técnica estadística utilizada en economía, inversión y otros campos para evaluar la fuerza y la naturaleza de una relación entre una variable dependiente (generalmente denotada por (y )) y un conjunto de otras variables (conocidas como variables independientes). La regresión intenta encontrar una relación matemática entre un conjunto de variables aleatorias que se cree para predecir (y ).
La regresión lineal simple y la regresión lineal múltiple son los dos tipos básicos de regresión. La regresión lineal múltiple utiliza dos o más variables independientes para predecir el resultado de la variable dependiente (y ). En contraste, la regresión lineal simple utiliza una variable independiente para describir o predecir el resultado de la variable dependiente (y ).
Existen varios tipos de regresión, incluidos lineales, múltiples lineales y no lineales. Los modelos lineales simples y múltiples son los más comunes. Sin embargo, el análisis de regresión no lineal se usa ampliamente para conjuntos de datos más complejos con relaciones no lineales entre las variables dependientes e independientes.
Una línea de regresión puede representar una relación positiva, negativa o sin lineal.
Caso 1: Si (b = ) pendiente de línea (= 0⟹ ) no hay conexión: en regresión lineal simple, la línea gráfica está plana (no inclinada). Las dos variables no tienen ninguna relación.
¿Qué es la regresión en psiquiatria?
Según Sigmund Freud, 1 regresión es un mecanismo de defensa inconsciente, que causa la reversión temporal o a largo plazo del ego a una etapa de desarrollo anterior (en lugar de manejar impulsos inaceptables de una manera más adulta). La regresión es típica en la infancia normal, y puede ser causada por el estrés, la frustración o por un evento traumático. Los niños generalmente manifiestan un comportamiento regresivo para comunicar su angustia. Abordar la necesidad insatisfecha subyacente en el niño generalmente corrige el comportamiento regresivo.
La regresión en adultos puede surgir a cualquier edad; Implica retirarse a una etapa de desarrollo anterior (emocional, social o conductualmente). La inseguridad, el miedo y la ira pueden hacer que un adulto regrese. En esencia, los individuos vuelven a un punto en su desarrollo cuando se sintieron más seguros y cuando el estrés era inexistente, o cuando un padre todopoderoso u otro adulto los habría rescatado.
El comportamiento regresivo puede ser simple o complejo, dañino o inofensivo para el individuo que muestra el comportamiento y para quienes los rodean. La regresión se vuelve problemática, especialmente en un hospital, cuando se emplea para evitar situaciones o factores estresantes difíciles de adultos. El manejo de la regresión en un hospital es intensivo en recursos y puede prolongar estadías en el hospital.2–5
La regresión ha sido retratada en una luz más positiva por otros (por ejemplo, psicólogos como Carl Jung), que han argumentado que la tendencia regresiva de un individuo no es solo una recaída en el infantilismo, sino un intento de lograr algo importante (por ejemplo, un sentimiento universal de inocencia infantil, sentido de seguridad, amor recíproco y confianza) .6,7
¿Qué es un análisis de regresión y correlación simple?
Los profesionales a menudo quieren saber cómo están relacionadas dos o más variables numéricas. Por ejemplo, ¿existe una relación entre la calificación en el segundo examen de matemáticas que toma un estudiante y la calificación en el examen final? Si hay una relación, ¿qué es y qué tan fuerte es la relación?
En otro ejemplo, sus ingresos pueden ser determinados por su educación, su profesión, sus años de experiencia y su capacidad. El monto que paga a una persona de reparación por trabajo a menudo se determina por un monto inicial más una tarifa por hora. Todos estos son ejemplos en los que se puede usar la regresión.
El tipo de datos descritos en los ejemplos son los datos bivariados: «BI» para dos variables. En realidad, los estadísticos usan datos multivariados, lo que significa muchas variables.
En este capítulo, estudiará la forma más simple de regresión, «regresión lineal» con una variable independiente (x). Esto involucra datos que se ajustan a una línea en dos dimensiones. También estudiará la correlación que mide cuán fuerte es la relación.
La regresión lineal para dos variables se basa en una ecuación lineal con una variable independiente. Tiene el formulario:
X es la variable independiente, e y es la variable dependiente. Por lo general, elige un valor para sustituir la variable independiente y luego resolver la variable dependiente.
El gráfico de una ecuación lineal de la forma es una línea recta. Cualquier línea que no sea vertical puede describirse con esta ecuación.
Las ecuaciones lineales de esta forma ocurren en aplicaciones de ciencias de la vida, ciencias sociales, psicología, negocios, economía, ciencias físicas, matemáticas y otras áreas.
¿Qué examina un análisis de regresión lineal simple?
El análisis de regresión es una técnica estadística que intenta explorar y modelar la relación entre dos o más variables. Por ejemplo, un analista puede querer saber si existe una relación entre los accidentes de tráfico y la edad del conductor. El análisis de regresión forma una parte importante del análisis estadístico de los datos obtenidos de los experimentos diseñados y se discute brevemente en este capítulo. Cada experimento analizado en un foilo Weibull ++ Doe incluye resultados de regresión para cada una de las respuestas. Estos resultados, junto con los resultados del análisis de varianza (explicado en los diseños de un factor y los capítulos generales de diseños factoriales completos), proporcionan información que es útil para identificar factores significativos en un experimento y explorar la naturaleza de la relación entre estos factores y la respuesta. El análisis de regresión forma la base de todos los cálculos folio de Weibull ++ DOE relacionados con la suma de los cuadrados utilizados en el análisis de varianza. La razón de esto se explica en el Apéndice B. Además, los folios del DOE también incluyen una herramienta de regresión para ver si se relacionan dos o más variables y para explorar la naturaleza de la relación entre ellas.
Un modelo de regresión lineal intenta explicar la relación entre dos o más variables usando una línea recta. Considere los datos obtenidos de un proceso químico donde se cree que el rendimiento del proceso está relacionado con la temperatura de reacción (ver la tabla a continuación).
Estos datos se pueden ingresar en el folio del DOE como se muestra en la siguiente figura:
Y se puede obtener una gráfica de dispersión como se muestra en la siguiente figura. En el rendimiento de la parcela de dispersión, [math] y_i , ! [/Math] se traza para diferentes valores de temperatura, [math] x_i , ! [/Matemáticas].
¿Que se entiende por regresión simple y múltiple?
En este artículo, trataremos de comprender la regresión lineal en términos simples con algunos ejemplos básicos e intentaremos conocer las matemáticas detrás de él.
La regresión es una forma de explicar la relación entre una variable dependiente (y) y una o más variables explicativas (x). Aquí, como el término consiste lineal, obviamente pensamos en una línea. En sentido básico, la regresión lineal se puede pensar en encontrar una relación entre dos cosas, es decir, variable dependiente (y) y variable independiente (x) utilizando una línea recta.
Algunos ejemplos son la predicción de ventas de la tienda, el aumento del precio de algunas propiedades, etc.
Regresión lineal simple: en la regresión lineal simple solo se predice una variable independiente (x) y se predice en base a esa variable dependiente (y).
Regresión lineal múltiple: en la regresión lineal múltiple hay múltiples variables independientes (x) y se predice en base a esa variable dependiente (y).
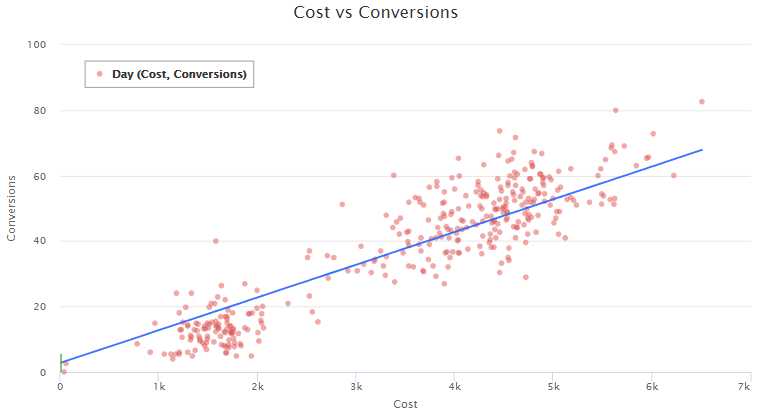
En los datos a continuación hay una variable independiente (x) e y es una variable dependiente. La tarea es identificar, con un valor futuro de X, lo que puede ser el valor de y.
En la traza anterior, los puntos rojos son los puntos de datos y, como necesitamos encontrar una relación lineal, los hemos conectado con una línea. Es bien sabido que la ecuación para una línea es y = mx + c, que también se puede escribir como y = β0 + β1×1. donde, β0 es C de la ecuación original, es decir, la intercepción y β1 es M de la ecuación original, es decir, pendiente
Si se completa esta ecuación de línea, se puede predecir para el futuro X. Aquí de pocos datos anteriores, se conocen X e Y. El objetivo es encontrar valores de β0 y β1 para completar nuestra ecuación.
Artículos Relacionados:

