Para enseñar a los lectores principiantes que luchan, necesitamos conocerlos bien como lectores. Examinar múltiples registros de ejecución a lo largo del tiempo nos ayuda a notar patrones en las respuestas de los niños. Estos patrones a su vez nos ayudan a decidir qué enfatizar en nuestra enseñanza y qué libros elegir para apoyar las necesidades de instrucción. Más allá de examinar cómo los niños usan el significado, la estructura y las fuentes visuales de información mientras se lee (ver Módulo de lectura guiada 1), podemos analizar más a fondo sus registros de ejecución utilizando el cuadro de «consideraciones adicionales»*. Este cuadro nos guiará para analizar tres áreas importantes relacionadas con el sistema de texto de procesamiento de un niño: contados del maestro, palabras de alta frecuencia y monitoreo.
*El cuadro es una adaptación para los maestros de aula basado en el estudio de investigación de Lea McGee y Mary Fried, desarrollo de actividades de resolución de problemas de los niños en punto de dificultad, presentada en la Conferencia Nacional de Recuperación de Reading de 2011 y Alfabetización K-6. Ver Fried, M., utilizando registros en ejecución para informar las decisiones de enseñanza (2013). The Journal of Reading Recovery, 13 (1), 5-15.
En el Ejemplo 1, el Dr. CC Bates (Profesor Asociado, Educación de Alfabetización, Universidad de Clemson, y Director, Recuperación de Reading y Centro de Entrenamiento de Aprendizaje Temprano para Carolina del Sur) y Maryann McBride (Líder de maestro de recuperación de lectura, Universidad de Clemson), hablan sobre cómo ellos Use cada paso de la tabla para obtener más información sobre la enseñanza de un alumno de primer grado que ha progresado a través de la recuperación de la lectura a la lectura en un nivel 10/11 en la Escuela Primaria Chastain Road, Liberty, SC (Distrito Escolar del Condado de Pickens).
¿Qué estudia el análisis de regresión?
El análisis de regresión es el estudio de las relaciones entre dos o más variables y generalmente se realiza por las siguientes razones:
Cuando queremos saber si realmente existe alguna relación entre dos o más variables;
Cuando estamos interesados en comprender la naturaleza de la relación entre dos o más variables; y
Cuando queremos predecir una variable dado el valor de los demás.
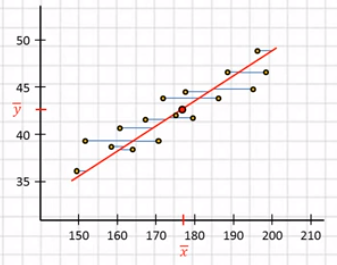
En su forma más simple, el análisis de regresión es muy similar a la correlación; De hecho, los modelos matemáticos subyacentes son prácticamente idénticos. Sin embargo, se puede utilizar el análisis de regresión donde hay muchas variables explicativas y donde se usan varios tipos de datos juntos. El modelo de regresión general es:
Donde α es una constante, x1, x2, etc. son las variables predictoras, y el término de error es la diferencia entre el valor observado y predicho de γ. Un ejemplo práctico de la ecuación anterior utilizando los datos de IQ de rendimiento puede tomar la siguiente forma:
El término de error se omite aquí y se supone que tiene una media de 0. Las distancias entre cada punto de datos y la línea de mejor ajuste que resume su relación se denominan residuos. Estas son las diferencias entre los valores observados y predichos y son una medida de la variación inexplicable. El modelo puede extenderse a ejemplos más complicados, p. Volumen cerebral utilizando el diagnóstico de variables, altura y coeficiente intelectual. La ecuación puede tomar la siguiente forma:
El diagnóstico es una variable categórica y, por lo tanto, no tiene sentido asignar un número a cada categoría de diagnóstico, ya que no hay orden en las categorías. Por lo tanto, tenemos que incluir una serie de «variables ficticias» cada una que indique la presencia o ausencia de un diagnóstico. El ejemplo anterior sería un modelo adecuado cuando solo se considera un diagnóstico, ya que el diagnóstico variable solo tendrá que tomar valores de 1 o 0.
¿Qué es la regresión?
Un modelo de regresión es un modelo matemático que intenta determinar la relación entre una variable de empleado (y), en comparación con otras variables, explicativas o independientes llamadas (x).
El modelo de regresión a menudo se usa en las ciencias sociales para determinar si existe o no una relación causal entre una variable de empleado (y) y un conjunto de otras variables explicativas (x). De la misma manera, el modelo intenta determinar cuál será el impacto en la variable y en caso de variación de las variables explicativas (x).
Así, por ejemplo, un economista puede estar interesado en determinar la relación entre los ingresos de los trabajadores y su nivel de educación. Para esto, podría crear un modelo de regresión en el que la variable independiente (y) sea el ingreso del trabajador. En cuanto a las variables explicativas (x), se deben incluir todas las que podrían explicar los ingresos, incluidos, por supuesto, la educación, la experiencia, la educación de los padres, etc.
El modelo de regresión simple tiene la siguiente forma:
u = término de error que incluye todos los demás factores que influyen en Y, pero no están incluidos en el modelo. También es posible adquirir los errores de estima de la variable del empleado. No observable.
Por lo tanto, el objetivo del modelo de regresión será estimar los valores de A y B de una muestra.
El parámetro B debe reflejar el impacto de una variación de X en la variable Y, cuando el resto de las variables explicativas permanecen constantes (ceteris paribus).
¿Dónde se aplica el análisis de regresión lineal?
La regresión lineal es la base de muchos análisis. A veces, los datos deben transformarse para cumplir con los requisitos del análisis, o la asignación debe hacerse para una incertidumbre excesiva en la variable X. Si no se cumplen los requisitos para el análisis de regresión lineal, se pueden usar métodos no paramétricos robustos alterativos. En algunos conjuntos de datos, la línea recta pasa a través del origen en 0,0, y luego se pueden usar ecuaciones simplificadas. La regresión lineal generalmente se usa para predecir el valor de la variedad Y en cualquier valor de la variada x, pero a veces se necesita la predicción inversa, en función de un enfoque diferente.
Modelos de regresión lineal una variable dependiente y en términos de una combinación lineal de variables independientes de P x = [x1 |… | xp] y estima los coeficientes de la combinación utilizando observaciones independientes (xi, yi), i = 1,…, n. Las condiciones de Gauss-Markov garantizan que la estimación de mínimos cuadrados de los coeficientes de regresión constituye el mejor estimador lineal. Bajo el supuesto de ruido blanco, es posible probar la importancia de cada coeficiente de regresión, evaluar la incertidumbre/bondad del ajuste y usar el modelo ajustado para predecir resultados novedosos. Cuando P> n, no se puede aplicar la regresión lineal clásica, y los enfoques penalizados como la regresión de la cresta, el lazo o la red elástica deben usarse.
Los modelos de regresión lineal generalizados son el marco global de este libro, pero solo los presentaremos. El Capítulo 1 está dedicado a modelos de regresión lineal (estándar y gaussianas). A pesar de ser solo un caso especial de modelos lineales generalizados, los modelos lineales deben discutirse por separado por algunas razones. La realización de regresión lineal en un entorno gaussiano siempre conduce a distribuciones específicas (por ejemplo, para las estadísticas de prueba), independientemente del tamaño de la muestra. Por el contrario, cuando se trabaja con modelos lineales generalizados, las estadísticas de prueba y los intervalos de confianza se construyen mediante argumentos asintóticos. Además, los modelos lineales generalizados son un enfoque extremadamente general para expresar la relación entre una variable de respuesta y un conjunto de variables explicativas. Es más fácil apreciar los beneficios de estas herramientas considerando el caso especial de los modelos lineales gaussianos antes de introducir el formalismo general.
¿Cuándo se aplica el análisis de regresión?
En el texto a continuación, pasaremos por estos puntos con mayor detalle y proporcionaremos un ejemplo del mundo real de cada uno.
La regresión puede modelar asociaciones lineales y no lineales entre una exposición (o tratamiento) y un resultado de interés. También puede modelar simultáneamente la relación entre más de 1 exposición y un resultado, incluso cuando estas exposiciones interactúan entre sí.
De Gonzales et al. Usó un modelo de regresión de Cox para estimar la asociación entre el IMC y la mortalidad entre 1,46 millones de adultos blancos.
Como se esperaba, encontraron que el riesgo de mortalidad aumenta con niveles progresivamente más altos de lo normal de IMC.
El mensaje para llevar es que el análisis de regresión les permitió cuantificar esa asociación al ajustar el tabaquismo, el consumo de alcohol, la actividad física, el nivel educativo y el estado civil, todos los posibles factores de confusión de la relación entre IMC y mortalidad.
También se puede utilizar un modelo de regresión para predecir cosas como los precios de las acciones, las condiciones climáticas, el riesgo de obtener una enfermedad, mortalidad, etc. en función de un conjunto de predictores conocidos (también llamados variables independientes).
Kim et al. usó la regresión de Poisson para desarrollar un modelo de predicción de malaria utilizando datos climáticos como la temperatura y la precipitación en Sudáfrica.
El modelo funcionó mejor con predicciones a corto plazo.
De todos modos, lo importante a notar aquí es la cantidad de complejidades que un modelo de regresión puede manejar. Por ejemplo, en este ejemplo, el modelo tenía que ser lo suficientemente flexible como para explicar las asociaciones no lineales y retrasadas entre la transmisión de la malaria y los factores climáticos.
Artículos Relacionados:

