- Nacionalidad. Por ejemplo, mexicano, argentino y español.
- Sexo. Hombre o mujer.
- Religión. Las diferentes religiones.
- Color de la piel, ojos o cabello.
- Ideología económica. Capitalismo, socialismo, economía mixta, etc.
- Ideología política. Según el diagrama de Nolan tendríamos conservadores, progresivos, centrales, liberales y totalitarios.
Y así podríamos continuar con otros ejemplos que no necesariamente no se pueden ordenar. Al menos, no en términos cuantitativos (no hay jerarquía). A continuación veremos dos ejemplos más desarrollados sobre nacionalidad y género.
Imaginemos estar en una clase con 10 estudiantes. Queremos saber cuántos hombres hay y cuántas mujeres hay para conocer la distribución porcentual. Por lo tanto, tenemos la siguiente tabla:
Por lo tanto, hay cinco hombres y cinco mujeres. Lo que significa que la distribución es del 50% de hombres y 50% de mujeres. Es una variable nominal porque no podemos ordenarla jerárquicamente.
Supongamos que ahora tenemos una tabla de datos que nos ofrece información sobre un conjunto de empresas y sobre el sector económico al que pertenece cada uno.
De las 10 compañías entrevistadas, 2 pertenecen al sector primario, 3 al sector secundario y 5 al sector terciario. Es decir, 20% al sector primario, 30% al sector secundario y 50% al sector terciario. Podríamos ordenar desde el peso más alto hasta el más bajo de la economía, pero la variable estadística sería «el número relativo de empresas por sector» y no «el sector al que pertenecen».
¿Cuáles son las variables cuantitativas nominales?
- Nacionalidad. Por ejemplo, mexicano, argentino y español.
- Sexo. Hombre o mujer.
- Religión. Religiones diferentes.
- Piel, ojos o color de cabello.
- Ideología económica. Capitalismo, socialismo, economía mixta, etc.
- Ideología política. Según el esquema de Nolan, tenemos conservadores, progresistas, centristas, liberales y totalitarios.
Y así podríamos continuar con más ejemplos que no necesariamente no se pueden ordenar. Al menos, no en términos cuantitativos (no hay jerarquía). En lo que sigue, veremos dos ejemplos más desarrollados sobre la nacionalidad y el género.
Imagina que estamos en una clase de 10 estudiantes. Queremos saber cuántos hombres hay y cuántas mujeres son para conocer la distribución en porcentaje. Por lo tanto, tenemos la siguiente tabla:
Entonces hay cinco hombres y cinco mujeres. Esto significa que la distribución es del 50 % de hombres y 50 % de mujeres. Es una variable nominal porque no podemos ordenarla jerárquicamente.
Supongamos ahora que tenemos una tabla de datos que nos ofrece información sobre un conjunto de empresas y el sector económico al que pertenece cada uno.
De las 10 compañías cuestionadas, 2 pertenecen al sector primario, 3 en el sector secundario y 5 en el sector terciario. O 20 % en el sector primario, 30 % en el sector secundario y 50 % en el sector terciario. Podríamos clasificar el peso más bajo al más bajo de la economía, pero la variable estadística sería «el número relativo de empresas por sector» y no «el sector al que pertenecen».
¿Cuáles son las variables cualitativas nominales?
La estadística trata de la encuesta, la representación (en forma de tablas, diagramas, gráficos, etc.) y el análisis de información sobre diferentes variables aleatorias.
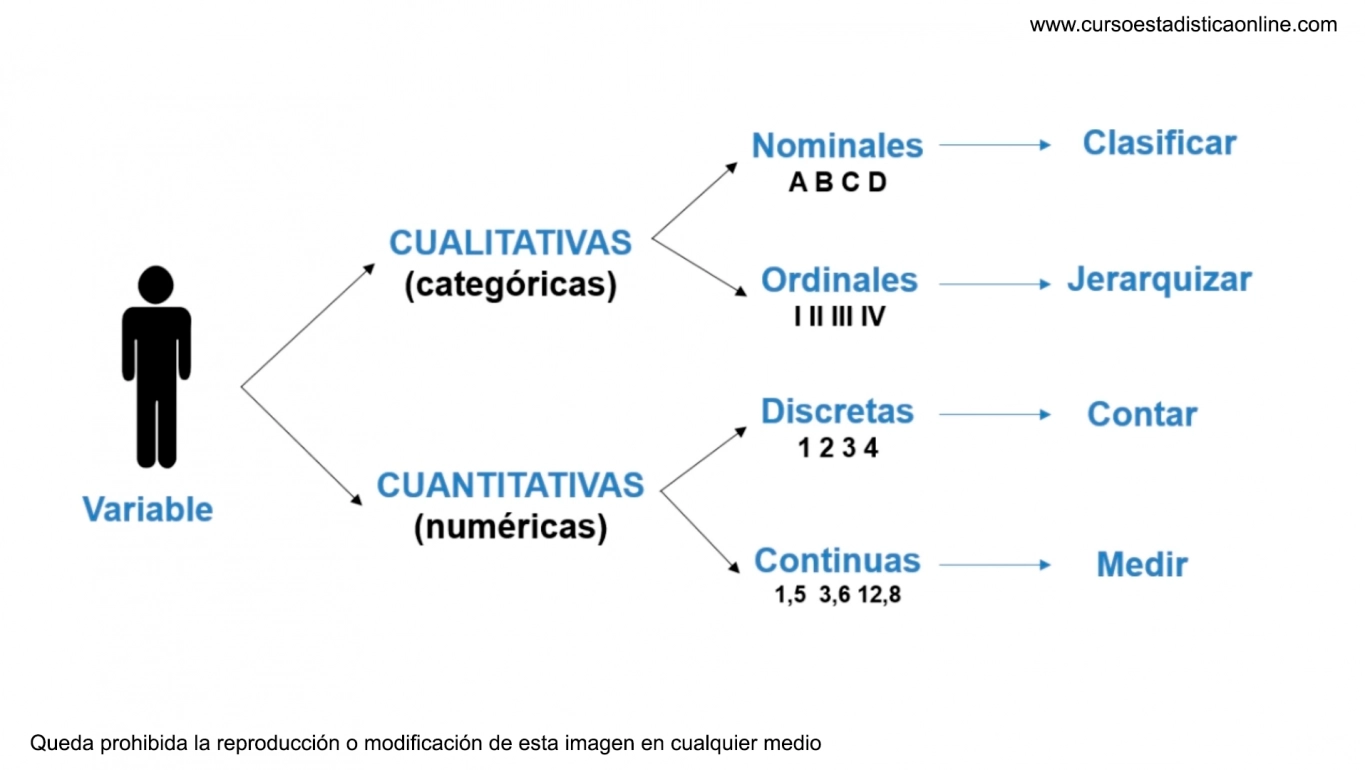
Se pueden contar las variables discretas (inestables), es decir, se muestran, por ejemplo, a lo largo de los números o similares. En particular, hay un siguiente (y uno al frente) para cada valor. Estos son principalmente números.
Las variables continuas (estables) se muestran, por ejemplo, por números reales, es decir, entre dos valores siempre hay un número infinito de otros valores.
Valores discretos: el número de estudiantes en las clases de una escuela el número de puntos en un trabajo escolar el número de niños en una familia el número de llamadas a la clínica ambulatoria en las cantidades de dinero del hospital, etc.
Hay dos tipos de datos cualitativos: ordinal (ordenable) para los cuales existe un orden obvio informativo, y nominal para los cuales tal orden no existe.
Estos se pueden mostrar gráficamente para la presentación clara de los datos. Además de la representación tabular, la representación por histogramas, polígonos o parcelas de boxeo es particularmente relevante.
El histograma de las frecuencias es una cifra que consiste en rectángulos que dependen de los intervalos de agrupación.
El polígono de frecuencias es una posibilidad de la representación gráfica de la densidad de probabilidad de un tamaño aleatorio. Representa un tren polígono que combina los puntos que corresponden a los valores medios de los intervalos grupales y las frecuencias de estos intervalos.
Artículos Relacionados:

