Un modelo estadístico generalmente se especifica como una relación matemática entre una o más variables aleatorias y otras variables no aleatorias. Como tal, un modelo estadístico es «una representación formal de una teoría» (Herman Adèr cita a Kenneth Bollen). [2]
Informalmente, un modelo estadístico puede considerarse como una suposición estadística (o conjunto de supuestos estadísticos) con una determinada propiedad: que la suposición nos permite calcular la probabilidad de cualquier evento. Como ejemplo, considere un par de dados ordinarios de seis lados. Estudiaremos dos supuestos estadísticos diferentes sobre los dados.
La primera suposición estadística es esta: para cada uno de los dados, la probabilidad de cada cara (1, 2, 3, 4, 5 y 6) que aparece es 1/6. A partir de esa suposición, podemos calcular la probabilidad de que ambos dados lleguen 5: 1/6 × 1/6 = 1/66. En términos más generales, podemos calcular la probabilidad de cualquier evento: p. (1 y 2) o (3 y 3) o (5 y 6).
La suposición estadística alternativa es esta: para cada uno de los dados, la probabilidad de que la cara 5 llegue es 1/8 (porque los dados están ponderados). A partir de esa suposición, podemos calcular la probabilidad de que ambos dados lleguen 5: 1/8 × 1/8 = 1/64. Sin embargo, no podemos calcular la probabilidad de ningún otro evento no trivial, ya que se desconocen las probabilidades de las otras caras.
La primera suposición estadística constituye un modelo estadístico: porque solo con la suposición, podemos calcular la probabilidad de cualquier evento. La suposición estadística alternativa no constituye un modelo estadístico: porque solo con la suposición, no podemos calcular la probabilidad de cada evento.
¿Qué es un modelo estadístico y para qué sirve?
El modelado estadístico es el proceso de aplicación de análisis estadístico a un conjunto de datos. Un modelo estadístico es una representación matemática (o modelo matemático) de datos observados.
Cuando los analistas de datos aplican varios modelos estadísticos a los datos que están investigando, pueden comprender e interpretar la información de manera más estratégica. En lugar de examinar los datos sin procesar, esta práctica les permite identificar relaciones entre variables, hacer predicciones sobre futuros conjuntos de datos y visualizar esos datos para que los no analizadores y las partes interesadas puedan consumirlo y aprovecharlo.
«Cuando analiza datos, está buscando patrones», dice Mello. «Estás usando una muestra para hacer una inferencia sobre el todo».
A menudo, los científicos a menudo tienen la tarea de construir modelos y algoritmos de escritura, los analistas también interactúan con modelos estadísticos en su trabajo en ocasiones. Por esta razón, los analistas que buscan sobresalir deberían apuntar a obtener una comprensión sólida de lo que hace que estos modelos tengan éxito.
«A medida que el aprendizaje automático y la inteligencia artificial se vuelven más comunes, cada vez más empresas y organizaciones están aprovechando el modelado estadístico para hacer predicciones sobre el futuro basado en datos», dice Mello. «[Entonces] si trabaja en el área de análisis de datos, debe comprender cómo funcionan los modelos subyacentes… no importa qué tipo de análisis esté haciendo o con qué tipo de datos esté trabajando, necesitará usar modelado estadístico de alguna manera «.
¿Cómo definir un modelo estadistico?
En la teoría de la probabilidad, un modelo estadístico es un modelo matemático que refleja un conjunto de supuestos estadísticos con respecto al proceso que rige la generación de datos de muestra de una población más grande. El modelo estadístico es, por lo tanto, una forma idealizada del verdadero mecanismo de generación de datos (DGM). Todas las pruebas de hipótesis estadística y todos los estimadores estadísticos se basan en modelos estadísticos, incluidas las pruebas de significación y los intervalos de confianza.
El propósito de un modelo estadístico es especificar las premisas inferenciales, permitirnos asignar probabilidades a todos los eventos de interés (espacio de muestra) y proporcionar probabilidades de error que se pueden usar para evaluar la optimización y la confiabilidad de los métodos para aprender de los datos .
En una hipótesis nula, prueba estadística, se elige una hipótesis para ser probada (la hipótesis nula) y, aunque generalmente se comunica como una afirmación simple en su forma más completa, es un modelo estadístico y sus premisas estadísticas. Una descripción genérica de un modelo estadístico es: & phmmat; θ (x) = {ƒ (x; θ), θ∈θ}, x∈X: = & reals; nx, donde ƒ (x; θ), θ∈θ es La distribución conjunta de la muestra que encapsula la estructura probabilística de la muestra x: = (x1,…, xn). Θ (theta) denota el espacio de parámetros, x es el espacio de muestra y θ es el parámetro desconocido. Las hipótesis nulas y alternativas son luego subcapacios del modelo general (θ0, θ1).
La especificación completa y correcta del modelo es clave ya que en la inferencia frecuente el aprendizaje de los datos ocurre cuando la probabilidad de error relevante (error de tipo I o error de tipo II) se relaciona directamente con una descripción adecuada del mecanismo de generación de datos subyacente. Si el modelo no es estadísticamente adecuado en el sentido de que sus supuestos probabilísticos no son válidos para los datos en cuestión, significa que no podría haber generado los datos que observamos, por lo que cualquier conclusión a la que llegamos es defectuoso si puede interpretarse en todos.
El prominente estadístico George Box comentó famosamente que «todos los modelos son falsos, ¡pero algunos son útiles!» Lo que a veces se malinterpreta al enfocarse en la primera parte e interpretarlo como lo que significa que nada se puede aprender a través de modelos estadísticos mientras se olvida por completo de la segunda parte. Sin embargo, la primera parte es un mero truismo: un modelo es, por definición, una representación imperfecta de un mecanismo complejo. La segunda parte, sin embargo, es lo que es realmente interesante y nos dice que podemos usar modelos para guiar las decisiones en el mundo real. La cita que da el mayor contexto es de hecho: «Recuerde que todos los modelos están equivocados; la pregunta práctica es qué tan equivocados tienen que ser para no ser útiles». [1] que obviamente cambia el enfoque de la primera parte al tema de las pruebas de especificación errónea (pruebas de partidos en supuestos).
¿Qué modelos estadísticos existen?
En las palabras más modestas, el modelado estadístico es un método interpretado matemáticamente prescrito para aproximar la verdad que está siendo generada por los datos y para hacer pronósticos a partir de esta aproximación.
Por ejemplo, representar una cantidad a través de una desviación promedio y estándar es la forma simple de modelado estadístico. Y aquí, el modelo estadístico es la expresión matemática que se está implementando.
«El modelado estadístico es simplemente el método para implementar el análisis estadístico en un conjunto de datos donde un modelo estadístico es una representación matemática de los datos observados».
El modelo estadístico se puede expresar como una combinación de resultados dependiendo de los datos consolidados y la comprensión de la población que se implementan para predecir información en una forma generalizada. Por lo tanto, un modelo estadístico podría ser una ecuación o una representación visual de la información sobre la base de una investigación exhaustiva realizada a lo largo de los años.
«Los estadísticos modernos están familiarizados con la noción de que cualquier cuerpo de datos finitos contiene solo una cantidad limitada de información sobre cualquier punto bajo el examen; que este límite se establece por la naturaleza de los datos en sí, y no puede aumentar por ninguna cantidad de ingenio gastado En su examen estadístico: que la tarea del estadístico, de hecho, se limita a la extracción de toda la información disponible sobre cualquier tema en particular «. -R. A. Fisher
En otras palabras, para reconocer las relaciones entre dos o más variables, existen modelos estadísticos. Y dado que existen diferentes tipos de variables, en consecuencia, hay diferentes modelos estadísticos. Algunos tipos comunes de modelos estadísticos son la prueba de correlación, el modelo de regresión, el análisis de la varianza, el análisis de covarianza, el chi-cuadrado, etc.
¿Qué tipos de modelos estadisticos existen?
Los modelos estadísticos se pueden colocar en grupos basados en parámetros. Un parámetro es un valor, numérico o medible de otra manera, utilizado para explicar o definir un conjunto de datos y la relación dentro de los datos. Los parámetros pueden considerarse como restricciones o pautas seguidas de los datos. Las siguientes son explicaciones de los modelos estadísticos.
- Los modelos paramétricos tienen distribuciones de probabilidad que han establecido parámetros que se conocen.
- Los modelos no paramétricos tienen valores en los que los parámetros pueden cambiar y no se establecen desde el principio.
- Los modelos semiparamétricos son una combinación de los modelos paramétricos y no paramétricos, fijos y flexibles.
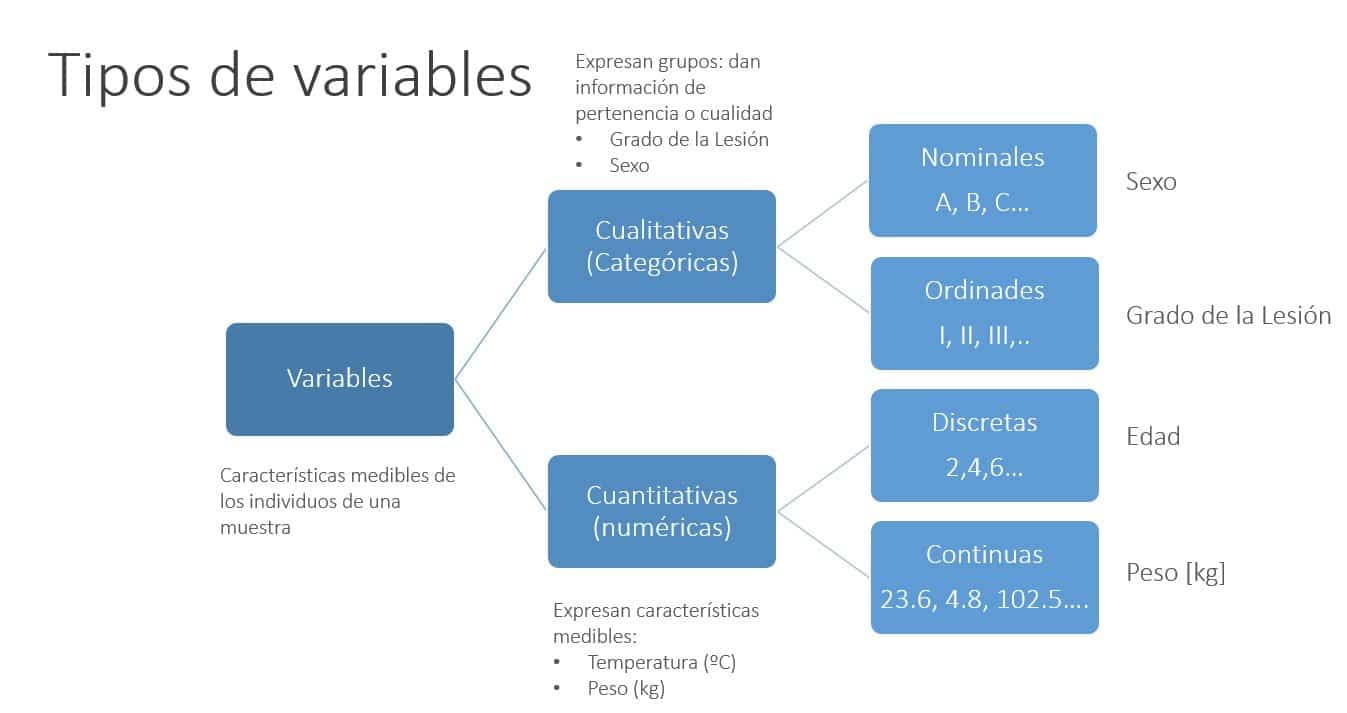
Los modelos estadísticos tienen variables y datos. Una variable es una característica de un elemento que se está investigando que puede representar cualquier valor en un conjunto que pueda medirse o categorizar. Los datos son cómo se miden las variables; la información recopilada.
Las variables de respuesta se conocen mejor como variables dependientes. Las variables dependientes son el resultado de la investigación. Las variables dependientes se miden para ver cómo las variables independientes las afectan.
Las variables independientes son las variables que se cambian para ver si los resultados de la investigación serán diferentes. Las variables independientes son la parte de la investigación que se cree que es la razón por la cual los datos cambian. Las variables independientes nunca se ven afectadas por otras variables.
¿Qué es un modelo estadístico?
Los modelos estadísticos generalmente representan la variabilidad estacional al simular el rendimiento del sistema por separado para cada mes del año. Pero para tener en cuenta la variabilidad a corto plazo, dependen de alguna forma de manipulación estadística. Por ejemplo, una técnica común al simular un sistema PV/batería independiente es calcular la probabilidad de pérdida de carga cada mes. Esta es la probabilidad de que el sistema experimente una escasez de suministro en algún momento durante el mes, un escenario que puede ocurrir después de que la carga excede la salida fotovoltaica el tiempo suficiente para drenar el banco de baterías por completo. Un modelo puede calcular la probabilidad de pérdida de carga utilizando información sobre la variabilidad del recurso solar y su correlación con la carga eléctrica. Si la probabilidad de pérdida de carga excede algún valor crítico especificado por el usuario, el sistema es inaceptable.
En comparación con los modelos de series temporales, los modelos estadísticos tienden a ser más simples de usar y más rápido para proporcionar resultados. Su simplicidad se deriva en parte de sus requisitos de entrada limitados; Requieren datos de carga y recursos promedio mensuales o anuales, en lugar de los datos por hora requeridos por la mayoría de los modelos de series de tiempo. También tienden a simular el rendimiento y el costo del sistema utilizando algoritmos menos detallados que requieren menos entradas obtenibles más fácilmente. Esta simplicidad de entrada hace que los modelos estadísticos sean relativamente fáciles de aprender. También significa que un diseñador puede ensamblar rápidamente los datos de carga, recursos y componentes necesarios para analizar un sistema en particular. Una ventaja adicional de los modelos estadísticos en los modelos de series temporales es su velocidad de cálculo generalmente más rápida; La mayoría de los productores producen virtualmente instantáneamente. La combinación de ensamblaje más rápido de entradas y una producción más rápida de salidas hace que los modelos estadísticos sean ideales para comparaciones rápidas del sistema y estimaciones de costos.
Sin embargo, la simplicidad de los modelos estadísticos tiene costa de una precisión reducida. Debido a que confían en simplificar los supuestos, los modelos estadísticos a veces pasan por alto aspectos importantes del comportamiento real del sistema. Por ejemplo, al modelar un sistema que comprende generadores diesel, un modelo estadístico puede suponer que el consumo de combustible del generador es lineal con potencia de salida, lo que significa que la eficiencia del generador es constante. Aunque simplifica enormemente el modelado del sistema, esta suposición descuida el hecho de que los generadores son mucho menos eficientes en cargas bajas, un hecho que tiene implicaciones importantes para el control y la economía del sistema. Su precisión reducida significa que los modelos estadísticos a menudo no pueden modelar de manera confiable el comportamiento de sistemas complejos, como los sistemas de viento/diesel de alta penetración. En tales sistemas, los detalles para los cuales un modelo simplificado no puede tener en cuenta puede tener un impacto sustancial tanto en el rendimiento como en la economía.
Los modelos estadísticos también tienden a permitir menos flexibilidad en la configuración del sistema. Debido a su incapacidad para simular sistemas complicados, por ejemplo, los modelos estadísticos generalmente permiten que un diseñador simule como máximo una fuente de energía renovable y un generador de despachable. Por lo general, no pueden analizar sistemas que comprenden múltiples fuentes de energía renovables, múltiples generadores u otras características avanzadas como la cogeneración. Un inconveniente adicional de los modelos estadísticos es que a pesar de usar menos entradas y generalmente más simples, un pequeño número de sus entradas puede ser difícil de entender y estimar. Un modelo estadístico puede, por ejemplo, requerir que el usuario especifique el grado en que la carga eléctrica se correlaciona con la radiación solar, o la fracción de la salida de la turbina eólica que tendrá que ser arrojada como exceso. Los modelos de series de tiempo no requieren ninguna de estas entradas; La correlación solar y de carga es innecesaria porque el modelo tiene acceso a los datos solar y de carga por hora, y una simulación de series de tiempo puede determinar la fracción de energía excesiva de la turbina eólica.
En resumen, los modelos estadísticos ofrecen simplicidad y velocidad a costa de precisión y flexibilidad. Son adecuados para los análisis de preolibilidad de muchos tipos de sistemas de energía renovable. De hecho, ciertos sistemas no complicados (como PV/batería o PV conectado a la red) pueden no requerir más modelado. Sin embargo, en el diseño de sistemas más complejos, particularmente aquellos que requieren estrategias de control sofisticadas o un equilibrio cuidadoso de la oferta y la demanda eléctrica, el modelado estadístico debe complementarse con el modelado de series de tiempo.
¿Qué son los modelos estadisticos en Excel?
Estoy tratando de ver cómo puedo construir un modelo estadístico simple en Excel. Digamos que tengo 10 vendedores. Para cada uno de ellos, han vendido X cantidad del año.
Quiero ver la relación entre los datos que he recopilado sobre su experiencia de ventas diferente, experiencia de la industria, llamadas, demostraciones y ver si existe una correlación en afectar positivamente su rendimiento de ventas para ese año.
No he usado mucho modelado estadístico en Excel. ¿Alguien tiene una indicación de cómo puedo configurarlo en Excel? Cualquier consejo sería enorme. Muchas gracias de antemano.
¿Qué es un análisis estadístico de datos en Excel?
MS Excel es una de las herramientas más utilizadas para el análisis de datos. La conveniencia del uso y el costo son dos razones muy importantes por las cuales la mayoría de los profesionales de datos prefieren usar Excel para el análisis de datos estadísticos. Sin embargo, el uso de Excel para el análisis estadístico requiere claridad de pensamiento, conocimiento del análisis de datos y fuertes habilidades de toma de decisiones.
Ya sea que esté realizando un análisis estadístico utilizando Excel 2010 o Excel 2013, debe tener una comprensión clara de los gráficos y las tablas de pivote. La mayoría de los analistas de datos que utilizan Excel para el análisis estadístico dependen en gran medida de estas dos características de Excel. Tener conocimiento de las estadísticas esenciales para el análisis de datos utilizando respuestas de Excel es una ventaja.
Recuerde instalar Data Analysis ToolPak si está utilizando Excel para el análisis de datos estadísticos. En esta discusión, explicamos en detalle las estadísticas esenciales para el análisis de datos utilizando Excel y cómo realizar análisis descriptivos utilizando Excel.
En este blog, he tratado de explorar las funcionalidades de MS-Excel como una herramienta potencial para el análisis estadístico y sugerí algunos trucos y técnicas simples que ahorrarán tiempo y energía.
Un pivottable es una herramienta de Excel para resumir una lista en un formato simple. Le ayuda a analizar todos los datos en su hoja de trabajo para tomar mejores decisiones comerciales. Excel puede ayudarlo recomendando y luego, creando automáticamente los bolsillos, que son una excelente manera de resumir, analizar, explorar y presentar sus datos.
¿Qué tipos de modelos estadisticos hay?
Los diferentes tipos de modelos estadísticos son esencialmente los métodos estadísticos utilizados para el cálculo. Estas son las ecuaciones matemáticas y las representaciones visuales que hacen posible el modelado estadístico. Algunos de ellos son:
- Regresión lineal
- Regresión logística
- Análisis de conglomerados
- Análisis factorial
- Análisis de la variación (ANOVA)
- Prueba de chi cuadrado
- Correlación
- Árboles de decisión
- Series de tiempo
- Diseño experimental
- Teoría bayesiana – Clasificador ingenuo de Bayes
- R de Pearson
- Muestreo
- reglas de asociación
- Operaciones de matriz
- Algoritmo vecino de K-Nearest (K-NN)
El modelado estadístico tiene un lugar importante en todo tipo de análisis de datos, lo que lo hace relevante para varios campos de la ciencia y la industria. Esto se mantiene especialmente en el campo de análisis de datos, donde los analistas dependen en gran medida de los métodos y técnicas estadísticas para interpretar y sacar conclusiones de cualquier conjunto de datos dado.
- Regresión lineal
- Regresión logística
- Análisis de conglomerados
- Análisis factorial
- Análisis de la variación (ANOVA)
- Prueba de chi cuadrado
- Correlación
- Árboles de decisión
- Series de tiempo
- Diseño experimental
- Teoría bayesiana – Clasificador ingenuo de Bayes
- R de Pearson
- Muestreo
- reglas de asociación
- Operaciones de matriz
- Algoritmo vecino de K-Nearest (K-NN)
Los modelos estadísticos se están introduciendo en la industria farmacéutica para determinar la eficacia de los medicamentos para individuos particulares, asegurando que las personas reciban los medicamentos adecuados para una respuesta óptima. Las técnicas estadísticas se utilizan para filtrar biomarcadores de los datos, utilizando los cuales se desarrollan modelos para predecir los grupos en los que los medicamentos son más efectivos.
Artículos Relacionados:

