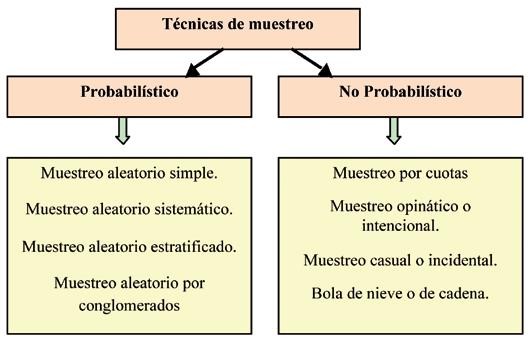
Existen diferentes tipos de muestreo aleatorio según las características de la población.
- Muestreo aleatorio simple: es uno de los más utilizados. Consiste en asignar un número aleatorio a la población y, por lo tanto, en base a esto, en la elección de la muestra. Es muy útil en poblaciones con cierta homogeneidad. Por ejemplo, se usa ampliamente en geología.
- Muestreo estratificado: en este caso es una población que, a pesar de ser heterogénea, puede dividirse en grupos homogéneos (sexo, edad, etc.). Una muestra aleatoria simple se lleva a cabo en cada grupo. Es ampliamente utilizado en ciencias sociales, como la psicología.
- Muestreo de estafas: en este caso, el objetivo es crear una serie de bloques o grupos. Estos son elegidos al azar por toda la población. En este caso, hay una etetogenidad dentro de ellos, así como una homogeneidad afuera. La investigación de mercado a menudo usa este muestreo aleatorio.
- Muestreo sistemático: en este caso, el número de individuos en la población se divide por los de la muestra que queremos obtener. Entonces elegimos uno al azar y contamos, usando ese valor. Los sujetos elegidos serán aquellos que correspondan a ese recuento. Este tipo reduce el problema de la auto correlación.
Imaginemos que queremos estudiar la altura promedio de ciertos estudiantes en una determinada universidad. Estos son datos ficticios y usaremos un ejemplo simple. El paso anterior consiste en crear una tabla en la hoja de cálculo con la población total y sus alturas.
Entonces, usaremos la metodología de muestreo aleatorio simple:
- Muestreo aleatorio simple: es uno de los más utilizados. Consiste en asignar un número aleatorio a la población y, por lo tanto, en base a esto, en la elección de la muestra. Es muy útil en poblaciones con cierta homogeneidad. Por ejemplo, se usa ampliamente en geología.
- Muestreo estratificado: en este caso es una población que, a pesar de ser heterogénea, puede dividirse en grupos homogéneos (sexo, edad, etc.). Una muestra aleatoria simple se lleva a cabo en cada grupo. Es ampliamente utilizado en ciencias sociales, como la psicología.
- Muestreo de estafas: en este caso, el objetivo es crear una serie de bloques o grupos. Estos son elegidos al azar por toda la población. En este caso, hay una etetogenidad dentro de ellos, así como una homogeneidad afuera. La investigación de mercado a menudo usa este muestreo aleatorio.
- Muestreo sistemático: en este caso, el número de individuos en la población se divide por los de la muestra que queremos obtener. Entonces elegimos uno al azar y contamos, usando ese valor. Los sujetos elegidos serán aquellos que correspondan a ese recuento. Este tipo reduce el problema de la auto correlación.
¿Qué es una muestra aleatoria?
Una muestra aleatoria es una muestra en la que cada miembro de la población tiene la misma posibilidad de ser seleccionado para representar el todo.
Para que podamos entender realmente qué es una muestra aleatoria, primero debemos distinguir entre una muestra y una población. Una población es todos los miembros de un grupo definido que tiene ciertas características o atributos que estamos interesados en estudiar. Supongamos que estábamos interesados en estudiar los hábitos de sueño de los hombres universitarios en los Estados Unidos. Nuestra población consistiría en todos los hombres que asisten a la universidad en los EE. UU.
Dado que hay más de 9 millones de hombres en esta población, sería prácticamente imposible para nosotros recopilar datos de cada miembro. Pero, ¿cómo recopilamos nuestros datos de investigación? Recopilamos datos de una muestra, que es una parte de la población que se usa para representar a toda la población. Para estudiar nuestra población, podemos tomar 560 hombres universitarios de EE. UU. Y recopilar datos de ellos.
Una muestra nos permite recopilar datos de algunos miembros que representan a toda la población. Cuando una muestra es verdaderamente representativa de una población, podemos hacer inferencias que se aplican a toda la población. La mejor manera de obtener una muestra representativa es mediante el uso de una muestra aleatoria.
Para que nuestra muestra sea aleatoria, deben ocurrir dos cosas:
- Cada miembro de la población debe tener las mismas posibilidades de ser seleccionados para ser parte de la muestra.
- La selección de un miembro de la población no depende de la selección de otro miembro.
¿Cómo saber si una muestra es aleatoria?
¿Tienes que llevar a cabo un estudio cuantitativo y realmente no recuerdas los métodos de muestreo? ¿Cómo saber si una muestra es representativa? ¡No se asuste, el blog Eval & Go le ofrece un pequeño resumen!
Estos métodos se utilizan en caso de que no conocemos todas las unidades de encuestas de una población y, por lo tanto, cuando es imposible establecer el estudio en una muestra aleatoria. Estos métodos son los más utilizados durante los estudios de marketing. Descubra cómo usar nuestra herramienta en línea para crear su propia investigación de mercado.
El método de la cuota permite garantizar que cada parte de la población se represente de manera similar a su proporción en la población básica. Por lo tanto, es una cuestión de proporción en este método, buscamos reproducir la población básica en una escala menor para poder extrapolar los resultados de la muestra a la población básica.
Esta muestra es de una manera una elección que está arbitra por usted mismo. Generalmente se elige para restricciones relacionadas con la practicidad, la accesibilidad y el costo. Por supuesto, los resultados extraídos de su encuesta no pueden extrapolarse, ya que este método no permite que la población básica sea reproducida.
Este método tiene como objetivo elegir un grupo de individuos y cuestionarlos para que a su vez identifiquen a otros miembros de este grupo, que también serán cuestionados, etc. Este método de muestreo generalmente se usa para estudiar las decisiones de compra.
¿Cuando una muestra es aleatoria?
Una suposición común en todas las pruebas estadísticas inferenciales es que usted recopiló datos de una muestra aleatoria de su población de interés. Para ser una muestra verdaderamente aleatoria, cada sujeto en su población objetivo debe tener las mismas posibilidades de ser seleccionados en su muestra. Un ejemplo de violación de esta suposición podría ser realizar un estudio para estimar la cantidad de tiempo que los estudiantes universitarios entrenan en su universidad cada semana. Si tuviera que recopilar datos solo en el gimnasio en el campus, esta sería una muestra sesgada. En este ejemplo, excluyó a todos los estudiantes que no hacen ejercicio en el gimnasio en el campus, por lo que los estudiantes de la universidad no tenían la misma oportunidad de ser incluidos en el estudio.
Si sospecha que sus datos no fueron seleccionados al azar, puede probar uno de los siguientes:
1. limita su población objetivo en su interpretación de los resultados.
Ejemplo: supongamos que desea estimar la cantidad promedio de estudiantes universitarios en los EE. UU. Gastan en libros de texto cada semestre. Sin embargo, solo es razonable para usted recolectar una muestra de estudiantes que asisten a su universidad. En este caso, es posible que desee discutir los resultados de su análisis en términos de la cantidad promedio que los estudiantes de su universidad gastan en libros de texto cada semestre, en lugar de generalizar a la población de estudiantes universitarios a nivel nacional.
2. Considere qué subconjuntos de su población tienen menos probabilidades de estar en su muestra y cómo esas personas pueden diferir de las que tiene en su conjunto de datos. Trate de rediseñar su plan de muestreo para dirigirse específicamente a esas personas, o reducir su población de interés como se describió anteriormente. Las técnicas como el muestreo aleatorio estratificado pueden ayudar a superar estos problemas.
Artículos Relacionados:

