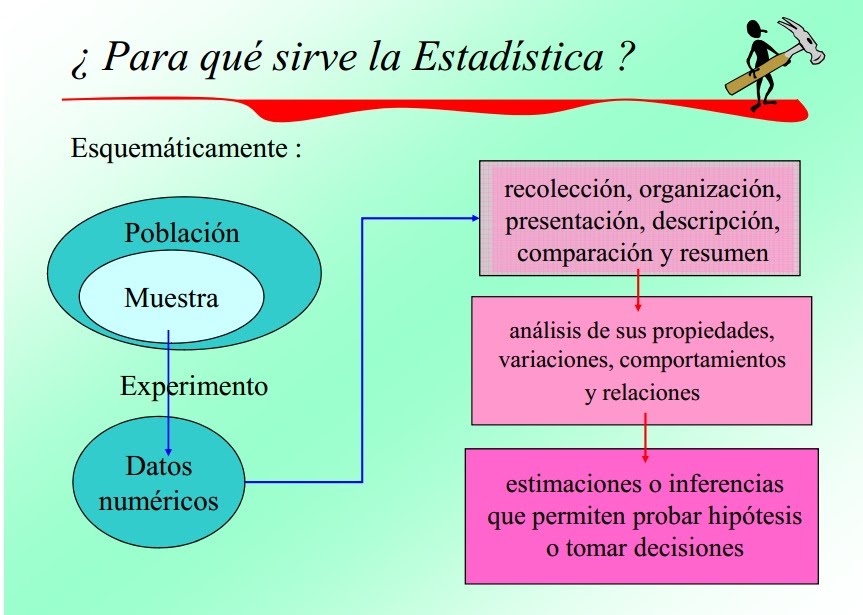
En la mayoría de los estudios estadísticos, deseamos cuantificar algo sobre una población. Por ejemplo, podemos desear
Para conocer la prevalencia de la diabetes en una población, la edad típica que los adolescentes comienzan a fumar, o el
Peso promedio del nacer de bebés nacidos en una comunidad en particular. Cuando la población es pequeña, es
a veces es posible obtener información de toda la población. Un estudio de toda la población es
llamado censo. Sin embargo, realizar un censo suele ser poco práctico, costoso y lento, si
No es francamente imposible. Por lo tanto, casi todos los estudios estadísticos se basan en un subconjunto de la población,
que llamaremos la muestra.
Al seleccionar una muestra, necesitamos saber cuántas personas estudiar y qué personas del
población para seleccionar. El tamaño de la muestra de un estudio depende de muchos factores y será el tema del futuro
estudiar. Actualmente, consideremos cómo seleccionar una muestra válida.
Una muestra válida es aquella que representa la población a la que se realizarán inferencias. Aunque hay
No hay forma segura de garantizar la representatividad de la muestra, se ha aprendido mucho en el último medio siglo
sobre el muestreo para maximizar la utilidad de una muestra. Una cosa que se ha aprendido es que, cuando
Posible, se debe usar una muestra de probabilidad. Una muestra de probabilidad es una muestra en la que:
- Cada miembro de la población tiene una probabilidad conocida de ser incluido en la muestra,
- La muestra es dibujada por algún método de selección aleatoria consistente con estas probabilidades, y
- Estas probabilidades se consideran al hacer estimaciones de la muestra (Cochran, 1977, p. 9).
El tipo más básico de una muestra de probabilidad es la muestra aleatoria simple. Una simple muestra aleatoria como una
muestra en la que cada miembro de la población tiene una probabilidad igual de ingresar a la muestra. Este
Asegura que la muestra sea:
- Cada miembro de la población tiene una probabilidad conocida de ser incluido en la muestra,
- La muestra es dibujada por algún método de selección aleatoria consistente con estas probabilidades, y
- Estas probabilidades se consideran al hacer estimaciones de la muestra (Cochran, 1977, p. 9).
Estas son dos características de muestreo extremadamente importantes.
¿Cuáles son las formas de observar la poblacion?
Identificar e intervenir en las disparidades de salud requiere datos representativos de salud pública comunitaria. Para las ciudades con alta vacante y poblaciones transitorias, los métodos tradicionales de estimación de la población para refinar muestras aleatorias no son factibles. El objetivo de este proyecto era desarrollar un método novedoso para observaciones sistemáticas para establecer muestras epidemiológicas comunitarias.
Inignamos un proceso de observación de aleatorización de población de cuatro pasos para Flint, Michigan, EE. UU.: (1) Use datos de población total recientes para áreas comunitarias (es decir, vecindarios) para establecer el tamaño de muestra proporcional para cada área, (2) Seleccione al azar segmentos callejeros de cada área comunitaria, (3) desplegar evaluadores para realizar observaciones sobre la habitación para cada segmento seleccionado al azar, y (4) observaciones completas para segmentos de la segunda y tercera calle, dependiendo de los niveles de vacante. Implementamos este proceso de observación sistemático en 400 segmentos callejeros seleccionados al azar. De estos, 130 (32.5%) requirieron la evaluación de segmentos secundarios debido a una alta vacante. Entre los 130 segmentos primarios, 28 (21.5%) requirieron evaluación de segmentos terciarios (o más). Para el 71.5% de los 400 segmentos de la calle primaria, hubo un consenso entre los evaluadores sobre si la vivienda habitaba o no está inhabitada.
Las casas observadas con este método podrían haberse considerado fácilmente deshabitadas a través de otros métodos. Esto podría hacer que los residentes de viviendas ambiguas (que probablemente sean los residentes más marginados con niveles más altos de necesidades de salud no satisfechas) estén subrepresentados en la muestra resultante.
La identificación e intervención en las disparidades de salud requiere datos representativos de salud pública comunitaria ([19], p. 21-40), a menudo incluyendo subpoblaciones difíciles de alcanzar. La obtención de datos representativos requiere métodos de muestreo de población aleatorios [6]. En los EE. UU., Muchas muestras de población aleatoria se basan en datos de la encuesta de la comunidad estadounidense (ACS) del censo estadounidense [16]. Los datos de ACS se publican cada año ya que la recopilación de datos es un proceso continuo, en forma de varios productos útiles [10]. Desafortunadamente, las estimaciones de ACS son susceptibles a márgenes de error significativamente mayores, en comparación con la muestra de forma larga del censo, debido a un tamaño de muestra mucho más pequeño [10]. Por esta razón, en las ciudades con altas poblaciones de vacantes y transitorias, los métodos tradicionales de estimación de la población para refinar los marcos de muestreo de población aleatoria no son ideales, y algunos investigadores recurren a combinaciones ad hoc de múltiples métodos (por ejemplo, utilizando datos secundarios de múltiples fuentes, seguimiento, seguimiento, rastrear Visitas en el hogar durante la administración de la encuesta y solicitar aportes continuos de los administradores de la encuesta) para establecer un marco de muestreo representativo [14].
Los estudios de los vecindarios despopulantes han encontrado problemas con la incertidumbre sobre la cantidad y distribución de hogares desocupados, así como la ocupación informal de algunas casas «vacantes» (por ejemplo, ocupantes ilegales) al intentar establecer un marco de muestreo confiable [14]. Sampson et al. [14] desarrolló un método que representaba un alto número de hogares vacantes, despoblación dinámica y residencias oficialmente «desocupadas» que en realidad estaban habitadas. Los autores sugieren que los investigadores que trabajan en las áreas despopulantes pueden beneficiarse al utilizar múltiples indicadores de ocupación al establecer su marco de área, además de la entrada del administrador de la encuesta. Además, recomiendan que los enfoques para múltiples indicadores de ocupación sean sistemáticos e iterativos en aras de la validez y confiabilidad.
¿Cómo se representa la población y muestra?
Estimados participantes del estudio, en este punto nos gustaría agradecerle nuevamente por su interés y participación en nuestro estudio. A continuación puede ver cómo los participantes de nuestro estudio respondieron preguntas seleccionadas; sin embargo, no se pueden derivar declaraciones sobre la población alemana de esto. Los resultados de todos los encuestados de nuestra primera ola de encuestas de 23.03. al 10 de mayo.
¿Cómo encontraron los encuestados nuestro estudio? La mayoría, a saber, casi 4.000 personas, recibió el enlace a través de un mensajero instantáneo como WhatsApp o SMS. Un poco menos de 3000 personas recibieron el enlace de miembros de la familia o conocidos por correo electrónico. Un poco más de 2500 personas declararon que habían encontrado el estudio en periódicos (en línea) o radio. Alrededor de 2500 participantes también se dieron cuenta de nosotros a través de plataformas de redes sociales como Twitter o Facebook. Una proporción algo menor declaró que había recibido el enlace a través de listas o distribuidores de Mailling.
¿Cuándo participaron los encuestados en la encuesta? Especialmente en la primera semana, el interés en el cuestionario fue muy bueno. Durante Welle 1.1, el número de participantes disminuyó constantemente hasta la primera publicación. Welle 1.2 comenzó con un número muy bajo de participantes, después de lo cual hay un aumento claro que disminuye con el tiempo. Se puede observar una pequeña subida alrededor del 20 y 4 de mayo.
Respondió significativamente más mujeres que hombres el cuestionario. La proporción de mujeres que completaron la encuesta fue más del doble que la de los hombres. La edad promedio entre las mujeres era 41 algo por debajo de la de los hombres con 44. Se puede ver tanto a las mujeres como a los hombres que la mayoría de los encuestados tienen 25-45 años.
¿Cómo se representa la población en estadística?
Si bien los métodos de la sección anterior son útiles para describir y mostrar datos de muestra, el poder real de las estadísticas se revela cuando usamos muestras para darnos información sobre las poblaciones. En este contexto, una población es toda la colección de objetos de interés, por ejemplo, los precios de venta para todas las viviendas unifamiliares en el mercado de viviendas representadas por nuestro conjunto de datos. Nos gustaría saber más sobre esta población para ayudarnos a tomar una decisión sobre qué hogar comprar, pero los únicos datos que tenemos son una muestra aleatoria de 30 precios de venta.
Sin embargo, podemos emplear el «pensamiento estadístico» para generar inferencias sobre la población de interés mediante el análisis de los datos de la muestra. En particular, utilizamos la noción de un modelo, una abstracción matemática del mundo real, que encajamos en los datos de la muestra. Si este modelo proporciona un ajuste razonable a los datos, es decir, si puede aproximarse a la manera en que varían los datos, entonces suponemos que también puede aproximar el comportamiento de la población. El modelo luego proporciona la base para tomar decisiones sobre la población, al identificar patrones, explicar la variación y predecir valores futuros. Por supuesto, este proceso solo puede funcionar si los datos de la muestra pueden considerarse representativos de la población.
A veces, incluso cuando sabemos que una muestra no se ha seleccionado al azar, aún podemos modelarla. Entonces, es posible que no podamos inferir formalmente sobre una población de la muestra, pero aún podemos modelar la estructura subyacente de la muestra. Un ejemplo sería una muestra de conveniencia: una muestra seleccionada más por razones de conveniencia que por sus propiedades estadísticas. Al modelar tales muestras, cualquier resultado debe informarse con una precaución sobre restringir cualquier conclusión a objetos similares a los de la muestra. Otro tipo de ejemplo es cuando la muestra comprende toda la población. Por ejemplo, podríamos modelar datos para los 50 estados de los Estados Unidos de América para comprender mejor cualquier patrón o asociación sistemática entre los estados.
Dado que el mundo real puede ser extremadamente complicado (en la forma en que los valores de los datos varían o interactúan juntos), los modelos son útiles porque simplifican los problemas para que podamos entenderlos mejor (y luego tomar decisiones más efectivas). Por un lado, necesitamos modelos lo suficientemente simples como para que podamos usarlos fácilmente para tomar decisiones, pero por otro lado, necesitamos modelos lo suficientemente flexibles como para proporcionar buenas aproximaciones a situaciones complejas. Afortunadamente, se han desarrollado muchos modelos estadísticos a lo largo de los años que proporcionan un equilibrio efectivo entre estos dos criterios. Uno de estos modelos, que proporciona un buen punto de partida para los modelos más complicados que consideramos más adelante, es la distribución normal.
¿Qué es la observación en estadística?
Esta página es parte de las estadísticas 4 principiantes, una sección de estadísticas explicada dónde se explican los indicadores y conceptos estadísticos de manera simple de hacer que el mundo de las estadísticas sea un poco más fácil tanto para los alumnos como para los estudiantes, así como para todos aquellos que interesan en las estadísticas. .
Una observación es un hecho o figura que recopilamos sobre una variable dada. Se puede expresar como un número o como una calidad.
Un ejemplo de un número es la observación «25» para la edad de una madre al nacimiento de su primer hijo.
Un ejemplo de calidad es la observación «Polonia» para el país de ciudadanía de un solicitante de asilo.
¿Qué es la observación en la estadística?
3. Aspectos programáticos y metodológicos de la observación estadística
4. Cuestiones organizacionales de observación estadística
5. Errores en la observación estadística y en el control de los materiales de observación
El estudio de las ciencias estadísticas juega un papel importante en la preparación de abogados altamente calificados, tanto profesionales como investigadores. Las estadísticas son de gran importancia: criminológica, criminal, penitenciaria, forense, administrativa y legal. Sus indicadores correspondientes son necesarios para especialistas en los sectores de leyes administrativas, penales, civiles y de otro tipo. En consecuencia, un especialista en el campo de las ciencias legales debe dominar los problemas básicos de la teoría estadística, p. La metodología estadística como un conjunto de técnicas y métodos, para un exaroso exareo exaroso en comparación con el contenido específico de los datos estadísticos utilizados: sobre el objeto y sobre el método, sobre la ley de grandes cantidades, sobre la observación estadística, la agrupación, la agrupación, la agrupación, la agrupación, la agrupación, sobre los indicadores de generalización y en el análisis estadístico.
Estadísticas legales: un sistema de conceptos y métodos de la teoría general de las estadísticas, aplicado al campo de estudio de delitos y medidas de control social en ellos.
Para estudiar los fenómenos y los procesos masivos de la vida social, incluido el crimen, es necesario recopilar la información necesaria, es decir, datos estadísticos. Los datos estadísticos son un conjunto de características cuantitativas (numéricas) obtenidas después de la investigación estadística (observación y procesamiento científico). La formación de una base de información (datos estadísticos) con la ayuda de un estudio estadístico de fenómenos y procesos sociales es un proceso complejo con múltiples etapas. Las siguientes fases se distinguen en este proceso: observación estadística, síntesis y agrupación del material recolectado;
¿Qué es la unidad de observación en estadística ejemplos?
Las unidades de observación en cada uno de los nodos terminales de un árbol de regresión son intuitivamente los grupos del conjunto de datos. Al maximizar la homogeneidad de los nodos terminales, el proceso es análogo a encontrar grupos homogéneos. Los grupos se encuentran en el espacio de respuesta y las variables explicativas que forman el árbol se consideran importantes para determinar los grupos. Por lo tanto, los árboles de regresión pueden considerarse fácilmente una herramienta de perfil.
El perfil identifica grupos en un conjunto de datos (el conjunto de datos explicativos) que también definen grupos en otro (el conjunto de datos de respuesta). Los MRT ofrecen un método para un conjunto de respuesta continua y un conjunto explicativo mixto porque el árbol está identificando grupos (nodos terminales) dentro de una matriz de respuesta que están definidas por el conjunto explicativo X.
Cualquier muestra seleccionada utilizando un mecanismo aleatorio que resulte en posibilidades conocidas de selección de las unidades de observación se denomina muestra aleatoria o de probabilidad. Esta definición requiere solo que se conozcan las posibilidades de selección. No requiere que las posibilidades de que las unidades de observación se seleccionen en la muestra sean iguales. El conocimiento de la posibilidad de selección es la base de la inferencia estadística de la muestra a la población. Una muestra seleccionada con posibilidades desconocidas de selección no puede vincularse adecuadamente a la población desde la cual se extrajo la muestra. Este punto se explicó en el Capítulo 4. Varios diseños de muestreo se discuten en las siguientes secciones que comienzan con un muestreo aleatorio simple.
En estadísticas, observamos o medimos las características, llamadas variables, de sujetos de estudio, llamadas unidades de observación. Para cada sujeto de estudio, los valores numéricos asignados a las variables se llaman observaciones. Por ejemplo, en un estudio de hipertensión entre los escolares, el investigador mide las presiones sanguíneas sistólicas y diastólicas para cada alumno. La presión arterial sistólica y diastólica son las variables, las lecturas de la presión arterial son las observaciones y las pupilas son las unidades de observación. Por lo general, observamos más de una variable en cada unidad. Por ejemplo, en un estudio de hipertensión entre 500 escolares, podemos registrar la edad, la altura y el peso de cada alumno, además de los dos tipos de lecturas de presión arterial. En este caso, tenemos un conjunto de datos de 500 estudiantes con observaciones registradas en cada una de las cinco variables para cada estudiante u unidad de observación.
¿Qué es la Unidad de observacion en una investigación ejemplos?
Las unidades de observación son en lo que se toma medidas.
En muchos experimentos son los mismos que los experimentales
unidades. Entonces simplemente puedes decirlo. En el
Ejemplo de despertar el
Las unidades de observación son las unidades experimentales.
Por supuesto, necesitas saber a qué vas
Medir antes de que pueda decir qué objetos se encuentra
va a medir, así que complete el
¿Qué medidas son para
ser grabado? Box al mismo tiempo que este.
En el ejemplo donde se usan 12 estudiantes durante 5 días,
Si cada estudiante se mide una vez al final del
Experimente, entonces las unidades de observación son las 12
estudiantes; Si cada estudiante se mide al final de
Cada día, las unidades de observación son las 60
Día de los estudiantes. En las abejas
Ejemplo, si el productor cuenta el número de manzanas en
Cada árbol, entonces las unidades de observación son los árboles.
En la hoja de datos, generalmente hay una fila para
cada unidad de observación.
Es útil indicar el número de observación
unidades, especialmente si no son las mismas que las
Unidades experimentales.
¿Qué es una unidad de análisis y una unidad de observación?
La unidad de análisis es la entidad que enmarca lo que se analiza en un estudio, o es la entidad estudiada en su conjunto, dentro de la cual existen la mayoría de los factores y el cambio causales. La unidad de análisis no debe confundirse con la unidad de observación. La unidad de observación es un subconjunto de la unidad de análisis. En la investigación en las ciencias sociales, la unidad de análisis más comúnmente referida, considerada una empresa, es el estado (político) (es decir, el país). Las unidades de observación comunes incluyen grupos, organizaciones e instituciones. La unidad de observación es la unidad descrita por sus datos (vecindarios que usan el censo de los Estados Unidos, individuos que usan encuestas, etc.). Por ejemplo, un estudio puede tratar a los grupos como una unidad de observación con un país como unidad de análisis, sacar conclusiones sobre las características del grupo a partir de los datos recopilados a nivel nacional.
La teoría de la dependencia y el análisis de los sistemas del mundo han desafiado el tratamiento de países como la sociedad o la unidad de análisis y el requisito previo que cada país se desarrolla por separado a través de fases que van desde la agricultura hasta el industrial, desde el autoritarismo hasta el democrático, desde el punto al avance, a través de la colección de pruebas históricas. El desarrollo de una división desigual del trabajo (economía mundial) muestra factores de causalidad que explican los cambios dentro de los países que indican que los países son parte de una sociedad más amplia o un sistema social histórico con patrones sistémicos que explican la desigualdad global.
La literatura de las relaciones internacionales proporciona un buen ejemplo de unidad del sistema de análisis.
¿Qué es la unidad de Estudio ejemplo?
El MIUR introdujo la unidad de aprendizaje para que el sistema escolar se vuelva más inclusivo, participativo y se basa en la resolución de problemas que podrían ocurrir en la vida real. La unidad de aprendizaje es, de hecho, un conjunto de conocimientos, habilidades y habilidades que se obtendrán durante la capacitación escolar. Este modo de enseñanza se centra en el interés del estudiante y ya no en el maestro. Además, la unidad de aprendizaje es una oportunidad que desea formar a la persona en su totalidad, sin limitarse a la mera transmisión de información. Todo esto ocurre a través del desarrollo de habilidades transversales y utilizando también un taller de enseñanza.
La unidad de aprendizaje se basa en el estudiante y requiere su participación activa, no solo como oyente. De una sola manera o en un grupo, el estudiante construye su conocimiento de manera guiada pero al mismo tiempo autónoma, utilizando herramientas diversificadas e innovadoras, también desde un punto de vista tecnológico.
Es muy importante mantenerse al día con el mundo contemporáneo y modelarse de acuerdo con sus cambios. La atención del niño es continua y flexible ya que el camino se puede adaptar de acuerdo con las necesidades contingentes. Gracias a la técnica de estudio transversal, muchas posibilidades de estudio en profundidad están presentes.
Algunas unidades de aprendizaje propuestas son de hecho multidisciplinarias y, por lo tanto, se caracterizan por el intercambio de un conocimiento final basado en diversas disciplinas. Compartir valores y habilidades hechas por múltiples temas le permite expandir sus puntos de vista y no considerar el estudio como tal, sino aplicado a la vida real. Los maestros, a través de la enseñanza individual de ciertas disciplinas, pueden contribuir a lograr un objetivo común. Por lo tanto, en la fase de planificación colegial, es importar identificar una intervención coordinada e intencional que se desarrolle. Cada maestro puede llevar a cabo esta tarea en sus horas de lecciones, sin crear otras adicionales, siguiendo la programación previamente establecida.
Artículos Relacionados:
- Estadística paramétrica: población y muestra aleatoria
- ¿Qué es la población en probabilidad y estadística?
- Estudio sobre el muestreo de poblaciones revela nuevas formas de optimizar el proceso
- Población y muestra en una investigación del universo
- ¿Qué es la inferencia sobre una varianza de población?

