El muestreo aleatorio, o el muestreo de probabilidad, es un método de muestreo que permite la aleatorización de la selección de muestras, es decir, cada muestra tiene la misma probabilidad que otras muestras para ser seleccionadas para servir como una representación de una población completa.
El muestreo aleatorio se considera uno de los métodos de recopilación de datos más populares y simples en los campos de investigación (probabilidad y estadísticas, matemáticas, etc.). Permite la recopilación de datos imparcial, que permite que los estudios lleguen a conclusiones imparciales.
- El muestreo aleatorio, también conocido como muestreo de probabilidad, es un método de muestreo que permite la aleatorización de la selección de muestras.
- Es esencial tener en cuenta que las muestras no siempre producen una representación precisa de una población en su totalidad; Por lo tanto, cualquier variación se conoce como errores de muestreo.
Hay cuatro métodos primarios de muestreo aleatorio (probabilidad). Estos métodos son:
El muestreo aleatorio simple es la selección aleatoria de un pequeño segmento de individuos o miembros de toda una población. Proporciona a cada individuo o miembro de una población una probabilidad igual y justa de ser elegido. El método de muestreo aleatorio simple es una de las técnicas de selección de muestra más convenientes y simples.
El muestreo sistemático es la selección de individuos o miembros específicos de toda una población. La selección a menudo sigue un intervalo predeterminado (k). El método de muestreo sistemático es comparable al método de muestreo aleatorio simple; Sin embargo, es menos complicado de conducir.
¿Qué es muestra aleatoria en estadística ejemplos?
Este tipo de muestreo es uno de los más utilizados en el método científico. Las razones son diversas, pero las más relevantes serían las siguientes:
- Primero, es el único que permite el análisis confirmatorio e inferencia estadística. De hecho, el segundo también se realiza en muestras no aleatorias, pero no podremos confirmar los resultados. En este caso, la investigación es exploratoria.
- Por otro lado, en relación con la sección anterior, este método reduce los sesgos. En otras palabras, con una cierta probabilidad (conocida) de elegir un cierto individuo en la población, evolucionamos la subjetividad inherente a la selección no aleatoria.
- Finalmente, permite el uso de pequeñas muestras en grandes poblaciones. Por supuesto, hay fórmulas para calcular estas muestras mínimas con poblaciones conocidas o desconocidas.
Como cualquier técnica utilizada en la ciencia, también se lleva a cabo de acuerdo con un proceso. Esto permite reproducir la experiencia y reducir los sesgos y la subjetividad.
- Primero, es el único que permite el análisis confirmatorio e inferencia estadística. De hecho, el segundo también se realiza en muestras no aleatorias, pero no podremos confirmar los resultados. En este caso, la investigación es exploratoria.
- Por otro lado, en relación con la sección anterior, este método reduce los sesgos. En otras palabras, con una cierta probabilidad (conocida) de elegir un cierto individuo en la población, evolucionamos la subjetividad inherente a la selección no aleatoria.
- Finalmente, permite el uso de pequeñas muestras en grandes poblaciones. Por supuesto, hay fórmulas para calcular estas muestras mínimas con poblaciones conocidas o desconocidas.
Existen varios tipos de muestreo aleatorio dependiendo de las características de la población.
- Primero, es el único que permite el análisis confirmatorio e inferencia estadística. De hecho, el segundo también se realiza en muestras no aleatorias, pero no podremos confirmar los resultados. En este caso, la investigación es exploratoria.
- Por otro lado, en relación con la sección anterior, este método reduce los sesgos. En otras palabras, con una cierta probabilidad (conocida) de elegir un cierto individuo en la población, evolucionamos la subjetividad inherente a la selección no aleatoria.
- Finalmente, permite el uso de pequeñas muestras en grandes poblaciones. Por supuesto, hay fórmulas para calcular estas muestras mínimas con poblaciones conocidas o desconocidas.
Imagine que queríamos estudiar el tamaño promedio de ciertos estudiantes en una determinada universidad. Estos son datos ficticios y usaremos un ejemplo simple. El paso anterior es crear una tabla en la hoja de cálculo con la población total y sus alturas.
Por lo tanto, usaremos el método de muestreo aleatorio simple:
- Primero, es el único que permite el análisis confirmatorio e inferencia estadística. De hecho, el segundo también se realiza en muestras no aleatorias, pero no podremos confirmar los resultados. En este caso, la investigación es exploratoria.
- Por otro lado, en relación con la sección anterior, este método reduce los sesgos. En otras palabras, con una cierta probabilidad (conocida) de elegir un cierto individuo en la población, evolucionamos la subjetividad inherente a la selección no aleatoria.
- Finalmente, permite el uso de pequeñas muestras en grandes poblaciones. Por supuesto, hay fórmulas para calcular estas muestras mínimas con poblaciones conocidas o desconocidas.
¿Cómo se hace un muestreo aleatorio?
El desastre de resumen literario de 1936 muestra lo que puede suceder si no se extrae una muestra aleatoria de la población. [1] Una muestra distorsionada condujo a un pronóstico electoral completamente incorrecto.
Una encuesta de votantes después de haber salido de la cabina electoral, con respecto a su comportamiento electoral, es una muestra aleatoria sin restricciones (si ningún encuestado rechaza la respuesta) con respecto a los votantes. Sin embargo, no es una muestra aleatoria (sin restricciones) con respecto a los votantes elegibles.
El comercio minorista se queja repetidamente de que sus propios empleados causan un gran daño por el robo de bienes. [2]
Es por eso que los supermercados más grandes llevan a cabo un control de bolsillo, entre otras cosas, cuando los empleados abandonan el supermercado. Dado que un control de bolsillo completo de todos los empleados sería demasiado complejo (y esto probablemente también tendría que pagarse por horas de trabajo), los empleados pasan por la producción de personal por una lámpara cuando salen del supermercado. Muestra que la computadora controlada por computadora, ya sea una luz verde (el empleado no está marcado) o una luz roja (se revisa el empleado). Esta selección es entonces una simple selección aleatoria.
En estadísticas matemáticas, las muestras aleatorias son la base de la conclusión de la muestra a las propiedades de la población. Una muestra concreta x1,…, xn { displayStyle x_ {1}, dotsc, x_ {n}} luego se está implementando como una realización de la variable aleatoriax1,…, xn { displayStyle x_}, dotsc, x_ { n}} Visto. Estas variables aleatorias se denominan variables aleatorias e indican la probabilidad del dibujo i { displayStyle i} con un cierto proceso de selección que se puede dibujar un cierto elemento de la población.
¿Cuándo se hace un muestreo aleatorio?
En esta publicación, explicaré qué es un muestreo aleatorio y los diferentes tipos de muestreo aleatorio que puede encontrar y una alternativa al muestreo aleatorio que puede considerar.
Al realizar una encuesta, no sería práctico estudiar a toda una población. El muestreo es un método que permite a los investigadores inferir información sobre una población basada en los resultados de un subconjunto de la población. Es importante asegurarse de que los individuos seleccionados sean representativos de toda la población.
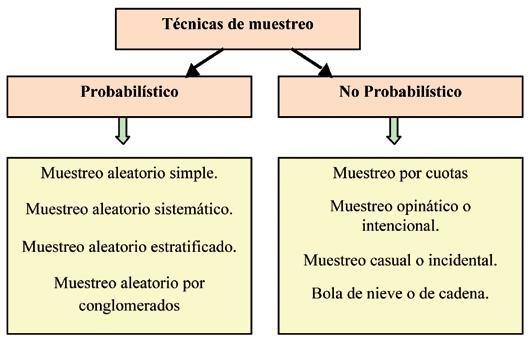
Hay varias técnicas de muestreo diferentes disponibles que se pueden agrupar en dos categorías como muestreo de probabilidad y muestreo no probabilidad. La diferencia entre las dos técnicas es si la muestra se selecciona en función de la aleatorización o no.
En el muestreo de probabilidad, alternativamente se conoce como muestreo aleatorio, comienza con un marco de muestra completo de todas las personas elegibles que tienen la misma oportunidad de ser parte de la muestra seleccionada. La selección debe ocurrir de una manera ‘aleatoria’, lo que significa que no difieren de ninguna manera significativa de las observaciones no muestreadas. Por lo general, se supone que las pruebas estadísticas contienen datos que se han obtenido a través de un muestreo aleatorio. Por ejemplo, las encuestas de salida de los votantes que apuntan a predecir los resultados probables de una elección.
Se discutirán las siguientes técnicas de muestreo aleatorio: muestreo aleatorio simple, muestreo estratificado, muestreo de conglomerados y muestreo en etapas múltiples. Las técnicas de muestreo no aleatorias a menudo se denominan muestreo de conveniencia.
¿Qué tipo de muestreo aleatorio?
Escribir los nombres de los 4.000 habitantes a mano para dibujar al azar 100 de ellos sería poco práctico y lento, así como cuestionable por razones éticas. En su lugar, decide usar un generador de números aleatorios para dibujar una muestra aleatoria simple.
Si el primer número generado por el programa es 1735, esto significa que el residente #1735 en su lista debe seleccionarse para formar parte de la muestra. Continúa haciendo coincidir cada número con el residente respectivo en la lista.
El muestreo estratificado recoge una selección aleatoria de una muestra de ciertos estratos o subgrupos dentro de la población. Cada subgrupo está separado de los demás sobre la base de una característica común, como el género, la raza o la religión. De esta manera, puede asegurarse de que todos los subgrupos de una población determinada estén adecuadamente representados dentro de su población de muestras.
Por ejemplo, si está dividiendo una población estudiantil por estudiantes universitarios, ingeniería, lingüística y educación física, los estudiantes son tres estratos diferentes dentro de esa población.
Para dividir su población en diferentes subgrupos, primero elija qué característica le gustaría dividirlos. Luego puede seleccionar su muestra de cada subgrupo. Puedes hacer esto de una de dos maneras:
- Seleccionando un número igual de unidades de cada subgrupo
- Seleccionando unidades de cada subgrupo igual a su proporción en la población total
Si toma una muestra aleatoria simple, los niños de las áreas urbanas tendrán una posibilidad mucho mayor de ser seleccionados, por lo que la mejor manera de obtener una muestra representativa es tomar una muestra estratificada.
¿Dónde se puede aplicar el muestreo aleatorio?
Después de la precisión, se determina la probabilidad de declaración y el tamaño de muestra necesario, la selección práctica de la muestra sigue: se «dibuja». La selección de la muestra también tiene requisitos metódicamente altos para lograr los resultados correctos. Una muestra defectuosa puede conducir a los datos obtenidos con él. La presentación posterior se limita a los aspectos estadísticamente relevantes.
En un examen, debe buscar que la muestra no contenga desviaciones sistemáticas de la población (distorsiones). La forma más fácil de hacerlo es asegurarse de que la muestra se dibuja al azar, pero esto no siempre es posible.
- La selección aleatoria: una selección aleatoria es si cada elemento de la población tiene la misma posibilidad de tener en cuenta en la muestra. Las ventajas de la selección aleatoria están en la previsibilidad del error aleatorio (= error de muestra); Por lo tanto, el procedimiento se describe estadísticamente con más detalle. Es desventajoso que el procedimiento no siempre se pueda usar, p. B. Si no todos los elementos de la población son conocidos.
- La selección consciente no aleatoria: una selección consciente es si los elementos de la población se seleccionan específicamente, que cumplen ciertos criterios. Los procedimientos son estadísticamente menos adecuados, debido a la falta de reportabilidad del error aleatorio. En la práctica, sin embargo, son importantes porque no siempre se puede hacer una selección aleatoria.
- Selección sistemática con arranque aleatorio: la muestra es aleatoriamente pero con un determinado sistema. Ejemplo: con un tamaño de muestra del 10%, cada décima o décima se selecciona, por lo que el punto de partida del recuento se deja al azar. Si es necesario, el clúster debe formarse de antemano (por ejemplo, trabajadores arancelarios y funcionarios); Luego, la selección aleatoria tiene lugar dentro del clúster educado.
Sobre la base de cuotas, se construye una muestra, que es representativa en la distribución de todas las características utilizadas para el todo. El criterio para la cita depende del interés respectivo en el conocimiento. Ejemplo: si la población consta de 40% de funcionarios públicos y 60% de trabajadores arancelarios, la muestra se selecciona para que también consta de 40% de funcionarios públicos y 60% de personal colectivo.
Esto da como resultado z. B. Significado porque hay diferentes horas de trabajo semanales.
En principio, los elementos a ser entrevistados deben ser seleccionados por un dibujo aleatorio de la población. En la práctica, el PBE orientado al proceso se desvía de esto: la selección de los elementos que se incluirán en la muestra está determinada por el período representativo en cuestión.
También se recomienda la inclusión de mayores expertos en literatura o estadística al usar una muestra de cuotas.
Artículos Relacionados:

