El análisis de regresión es una metodología estadística que nos permite determinar la fuerza y la relación de dos variables. La regresión no se limita a dos variables, podríamos tener 2 o más variables que muestren una relación. Los resultados de la regresión ayudan a predecir un valor desconocido dependiendo de la relación con las variables de predicción. Por ejemplo, la altura y el peso de alguien generalmente tienen una relación. En general, las personas más altas tienden a pesar más. Podríamos usar el análisis de regresión para ayudar a predecir el peso de un individuo, dada su altura.
Cuando hay una sola variable de entrada, la regresión se conoce como una regresión lineal simple. Utilizamos la variable única (independiente) para modelar una relación lineal con la variable objetivo (dependiente). Hacemos esto ajustando un modelo para describir la relación. Si hay más que predecir la variable, la regresión se conoce como regresión lineal múltiple.
Es posible que haya oído hablar de la regresión de mínimos cuadrados ordinarios. Cuando intentamos encontrar la «mejor línea de ajuste», el modelo de regresión a veces se puede denominar regresión de mínimos cuadrados ordinarios. Esto solo significa que estamos usando la mayor suma de errores al cuadrado. El error es la diferencia entre el valor Y predicho restado del valor Y real. La diferencia está cuadrada, por lo que hay una diferencia absoluta y sumada.
Error = Y_ACTual - Y_Predicto
¿Qué es un proceso de regresión lineal y cuál sería su interpretación?
Está buscando una solución eficiente para realizar su primera regresión lineal. Los libros de estadísticas que explican esta herramienta generalizada confunden un poco las ideas. Y aquí intentas entender. Bueno, en este artículo intentaré aclarar qué es la regresión lineal.
El primer enfoque con una regresión lineal tiene lugar en el momento del estudio de estadísticas. En particular, los diversos textos dicen que más o menos las cosas: «La regresión es un modelo estadístico que le permite predecir los valores de una variable numérica que comienza a partir de una o más variables». Ok, estoy de acuerdo con usted: ¡ahora que hemos leído la definición más o menos oficial que sabemos menos que antes!
Tratemos de dar un paso atrás en la historia de su escuela y hablar sobre ecuaciones muy simples, nos detenemos en el primer grado. ¿Recuerdas esa ecuación de primer grado que se puso bajo el nombre de la línea recta? ¿Qué le permitió saber cómo rastrear una línea recta en el plan cartesiano? Si recuerdas, el juego fue muy simple: el maestro te dio los valores de dos puntos, p (x1; y1) y q (x2; y2), en los que X e y eran variables numéricas, y tú con línea y Pencil encontró las coordenadas que encontró de los dos puntos P y Q y trazó la línea recta combinando los puntos. O sabía un punto p (x; y), el coeficiente de esquina de la recta (m) y la ordenada al origen (Q) e intentó comprender cómo se hizo una ecuación de esta manera:
¡Con la regresión lineal estamos hablando exactamente de una línea recta! ¡Y su ecuación es precisamente la de la línea recta! Excepto que para hacer que el juego estadístico sea más emocionante, sabemos muchas X (son las observaciones de la variable independiente que se refiere, por ejemplo, a muchos sujetos) y muchos valores de Y (son las observaciones de la variable de los empleados que siempre se refieren a muchas. asignaturas).
¿Cómo se hace la interpretacion de la de regresión lineal?
La interpretación de los coeficientes en los modelos lineales (generalizados) es más sutil de lo que muchos creen, y tiene consecuencias sobre cómo probamos hipótesis e informamos los hallazgos. Comenzaremos hablando de interpretaciones marginales versus condicionales de los parámetros del modelo.
En este ejemplo, modelamos la altura de la planta en función de la altitud y la temperatura. Estas variables se correlacionan negativamente: hace más frío cuanto más alto vaya. Comenzamos simulando algunos datos para reflejar esto.
Ahora podemos simular algunos datos para la altura de las plantas. Aquí decimos que la altura media de las plantas es 2 (cuando todas las otras variables son 0), a medida que la temperatura aumenta en una unidad (manteniendo constante de altitud), la media de altura aumentará en 1 unidad (beta [2] = 1) , y de manera similar, a medida que aumenta la altitud en 1 unidad (manteniendo constante de temperatura), la altura media disminuye en 1 (beta [3] = -1). La altura se distribuye normalmente con esta media y desviación estándar de 2.
La interpretación de estos coeficientes es que si mantiene todo lo demás en la constante del modelo (es decir, temperatura) y agrega 1 a la altitud, entonces la altura media estimada disminuirá en 1.09. Tenga en cuenta que el coeficiente depende de las unidades en las que se mide la altitud. Si la altitud está en metros, el coeficiente le dice qué sucede cuando subes 1 metro.
La intersección es el valor predicho cuando todas las otras variables se establecen en 0, lo que a veces tiene sentido (aquí sería la altura de las plantas en el nivel del mar y la temperatura de 0). Otras veces 0 no es un valor significativo, y si desea interpretar la intersección, podría tener sentido rescalar sus otras variables para que su media sea 0. Si hace esto, entonces la intercepción es el valor predicho cuando todas las demás variables están en su nivel medio.
¿Cómo se interpreta la pendiente en el modelo de regresión lineal simple?
Allison Abels ha enseñado matemáticas en la escuela secundaria durante 6 años. Tiene una maestría en matemáticas con una especialización en educación matemática de la Universidad del Norte de Illinois. También posee una licencia de educador profesional en el estado de Illinois.
Al modelar datos lineales, la pendiente y la intersección del gráfico proporcionan información útil sobre las condiciones iniciales y la tasa de cambio de lo que se está estudiando. Primero, la pendiente de una línea es una medida de su inclinación. En una línea, la pendiente es una relación del cambio en una variable al cambio en el otro. Por lo general, esto se refiere al cambio en Y para cada cambio de unidad en X, pero a veces se pueden usar otras variables.
La fórmula para la pendiente es el cambio en y sobre el cambio en x. El triángulo es la letra griega delta, que representa el cambio.
La intersección se refiere a la intersección y, que es donde la línea se cruza con el eje y. Nuevamente, se pueden usar otras variables, pero la intersección generalmente se refiere a la variable independiente y al eje vertical.
Cuando los datos parecen formar una línea recta, los estadísticos usarán un modelo lineal. Un modelo lineal es una comparación de dos variables con una tasa constante de cambio o pendiente. Cuando gráfica de datos que parecen ser lineales, una línea de regresión generalmente se grafica para mostrar la aproximación lineal más cercana a los datos. Una línea de regresión es una línea recta que se aproxima a la relación entre los puntos de datos. Interpretar la pendiente e intercepción utilizando un modelo lineal significa explicar lo que representan la pendiente y la intercepción para los datos y la situación.
¿Qué es el proceso de regresión lineal?
El análisis de regresión lineal consiste en algo más que ajustar una línea lineal a través de una nube de puntos de datos. Consiste en 3 etapas: (1) analizar la correlación y direccionalidad de los datos, (2) estimar el modelo, es decir, ajustar la línea y (3) evaluar la validez y utilidad del modelo.
Primero, se debe utilizar una gráfica de dispersión para analizar los datos y verificar la direccionalidad y la correlación de los datos. La primera gráfica de dispersión indica una relación positiva entre las dos variables. Los datos son adecuados para ejecutar un análisis de regresión.
La segunda gráfica de dispersión parece tener una forma de U inversa que indica que una línea de regresión podría no ser la mejor manera de explicar los datos, incluso si un análisis de correlación establece un vínculo positivo entre las dos variables.
Alinear el marco teórico, la recopilación de artículos, sintetizar brechas, articular una metodología y plan de datos claros, y escribir sobre las implicaciones teóricas y prácticas de su investigación son parte de nuestros servicios integrales de edición de tesis.
- Rastree todos los cambios, luego trabaje con usted para lograr una escritura académica.
- Apoyo continuo para abordar los comentarios del comité, reduciendo las revisiones.
Sin embargo, con mayor frecuencia, los datos contienen una gran cantidad de variabilidad en estos casos, es decisión de cómo proceder mejor con los datos.
¿Qué es la regresión lineal y su fórmula?
Sepamos qué es la regresión lineal. Es muy importante y se usa para un fácil análisis de la dependencia de dos variables. Se considerará una variable como una variable explicativa, mientras que otras se considerarán una variable dependiente. La regresión lineal es un método lineal para modelar la relación entre las variables independientes y las variables dependientes. La linealidad de la relación aprendida hace que la interpretación sea muy fácil. Los modelos de regresión lineal han sido utilizados durante mucho tiempo por las personas como estadísticos, informáticos, etc. que abordan problemas cuantitativos. Por ejemplo, un estadístico podría querer relacionar los pesos de las personas con sus alturas utilizando un modelo de regresión lineal. Ahora sabemos qué es la regresión lineal.
Sepamos qué es una ecuación de regresión lineal. La fórmula para la ecuación de regresión lineal viene dada por:
b = [ frac {n sum xy – ( sum x) ( sum y)} {n sum x^2 – ( sum x)^2} ]
X e Y son las variables para las cuales haremos la línea de regresión.
Nota: El primer paso para encontrar una ecuación de regresión lineal es determinar si existe una relación entre las dos variables. Este es a menudo un llamado de juicio para el investigador. También necesitará una lista de sus datos en un formato X – Y (es decir, dos columnas de datos: variables independientes y dependientes).
El concepto de regresión lineal consiste en encontrar la línea recta mejor ajustada a través de los puntos dados. La línea de mejor ajuste se conoce como línea de regresión. La línea diagonal negra en la figura dada a continuación (Figura 2) es la línea de regresión y consiste en la puntuación predicha en y para cada valor posible de la variable X. las líneas en la figura dadas anteriormente, las líneas verticales desde los puntos a los puntos a los puntos a los puntos a los puntos a Línea de regresión, representan los errores de predicción. Como puede ver, el punto rojo está realmente muy cerca de la línea de regresión; Podemos ver que su error de predicción es pequeño. Por el contrario, el punto amarillo que podemos ver es mucho más alto que la línea de regresión y, por lo tanto, su error de predicción es grande.
¿Que explica el análisis de regresión?
El análisis de regresión tiene cuatro propósitos principales: descripción, estimación, predicción y control.1,2 por descripción, la regresión puede explicar la relación entre variables dependientes e independientes. La estimación significa que mediante el uso de los valores observados de variables independientes, se puede estimar el valor de la variable dependiente.2 El análisis de regresión puede ser útil para predecir los resultados y los cambios en las variables dependientes basadas en las relaciones de variables dependientes e independientes. Finalmente, la regresión permite controlar el efecto de una o más variables independientes mientras investiga la relación de una variable independiente con la variable dependiente.1
Comúnmente hay tres tipos de análisis de regresión, a saber, regresión lineal, logística y múltiple. Las diferencias entre estos tipos se describen en la Tabla 1 en términos de su propósito, la naturaleza de las variables dependientes e independientes, los supuestos subyacentes y la naturaleza de la curva.1,3 Sin embargo, la discusión más detallada para la regresión lineal se presenta de la siguiente manera.
El análisis de regresión lineal implica examinar la relación entre una variable independiente y dependiente. Estadísticamente, la relación entre una variable independiente (x) y una variable dependiente (y) se expresa como: y = β0+ β1x+ ε. En esta ecuación, β0 es la intersección Y y se refiere al valor estimado de y cuando x es igual a 0. El coeficiente β1 es el coeficiente de regresión y denota que el aumento estimado en la variable dependiente para cada aumento de la unidad en la variable independiente. El símbolo ε es un componente de error aleatorio y significa imprecisión de regresión que indica que, en la práctica real, las variables independientes no pueden predecir perfectamente el cambio en cualquier variable dependiente.1 La regresión lineal múltiple sigue la misma lógica que la regresión lineal univariante excepto (a) Regresión múltiple, hay más de una variable independiente y (b) debe haber no colinealidad entre las variables independientes.
¿Qué es el algoritmo análisis de regresión?
En el aprendizaje automático, utilizamos varios tipos de algoritmos para permitir que las máquinas aprendan las relaciones dentro de los datos proporcionados y hagan predicciones basadas en patrones o reglas identificadas del conjunto de datos. Por lo tanto, la regresión es una técnica de aprendizaje automático donde el modelo predice la salida como un valor numérico continuo.
El análisis de regresión a menudo se usa en finanzas, inversiones y otros, y descubre la relación entre una única variable dependiente (variable objetivo) que depende de varios independientes. Por ejemplo, predecir el precio de la vivienda, el mercado de valores o el salario de un empleado, etc.
problemas de regresión.
La regresión lineal es un algoritmo ML utilizado para el aprendizaje supervisado. La regresión lineal realiza la tarea para predecir una variable dependiente (objetivo) basada en las variables independientes dadas. Entonces, esta técnica de regresión descubre una relación lineal entre una variable dependiente y la otra variables independientes dadas. Por lo tanto, el nombre de este algoritmo es la regresión lineal.
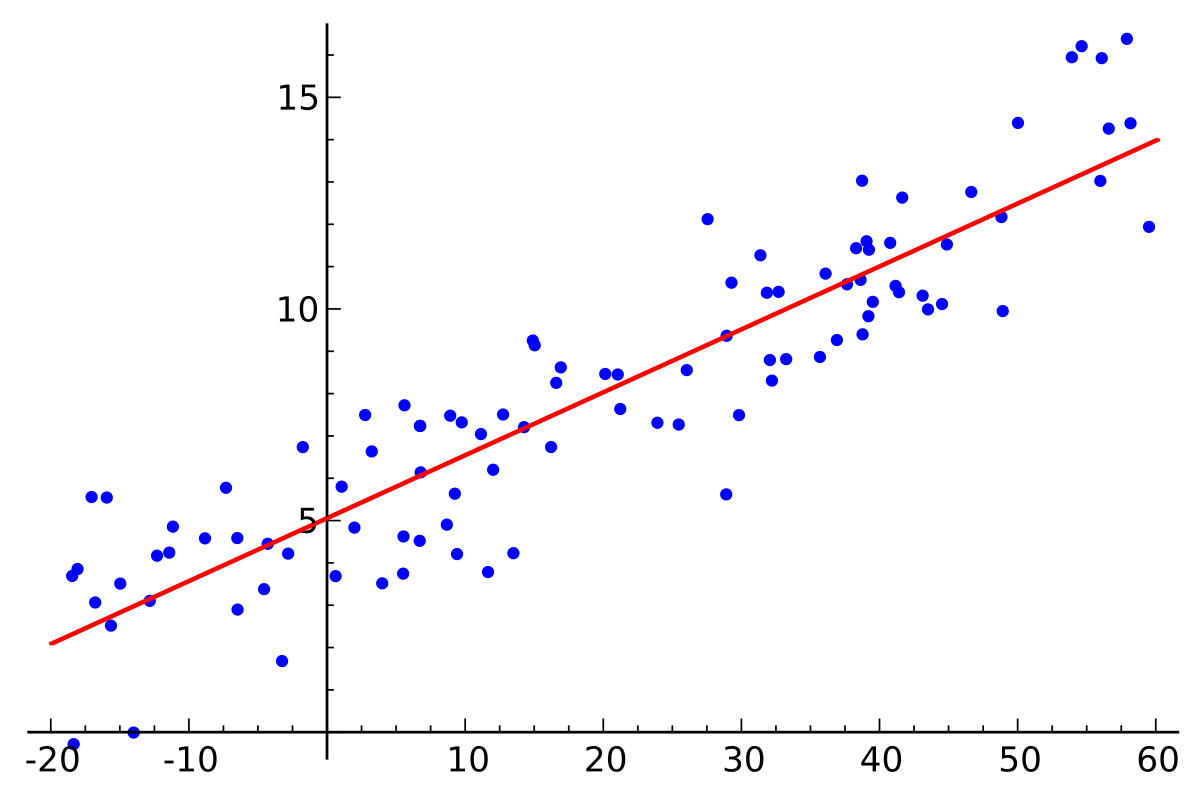
En la figura anterior, en el eje X está la variable independiente y en el eje y es la salida. La línea de regresión es la mejor línea de ajuste para un modelo. Y nuestro objetivo principal en este algoritmo es encontrar esta mejor línea de ajuste.
- La regresión lineal es simple de implementar.
- Menos complejidad en comparación con otros algoritmos.
- La regresión lineal puede conducir a un ajuste excesivo, pero se puede evitar utilizando algunas técnicas de reducción de dimensionalidad, técnicas de regularización y validación cruzada.
Artículos Relacionados:
- Aplicación de la Regresión Lineal para el Análisis de Datos
- Análisis de regresión lineal: cómo optimizar tu estrategia de marketing
- Aprende el proceso de regresión lineal para mejorar tus predicciones
- Aprende a calcular la correlación y regresión lineal con estos sencillos pasos
- ¿Qué aporta la regresión lineal a la investigación aplicada?

