La exploración de datos es el proceso de describir las características principales de un conjunto de datos. Este es a menudo el primer paso que las personas dan al realizar análisis de datos. Durante este proceso, el analista decide qué cuestionar los datos responderán, qué hipótesis probablemente apoyará y qué variables tienen relaciones significativas. Durante la fase de exploración de datos, los analistas se familiarizan con los datos mientras buscan estas respuestas.
La forma en que los analistas más comunes realizan el paso de exploración de datos es a través del software de visualización de datos. Al tener acceso rápido a los datos y la capacidad de ver las relaciones de manera gráfica, los usuarios pueden ver fácilmente qué variables tienen una relación significativa y deben analizarse más a fondo. Por ejemplo, un usuario puede usar una herramienta BI para crear una gráfica de dispersión que compare dos variables. Luego pueden reemplazar una de las variables con otra, luego continuar este proceso hasta que noten una correlación en la parcela. Luego pueden decidir seguir la relación entre esas variables, descubriendo si hay alguna información que pueda beneficiar a su empresa.
Hay dos pasos principales para realizar la exploración de datos: análisis univariado y análisis bivariado.
- Análisis univariado: este tipo de análisis analiza las variables individualmente y descubre si son categóricas o numéricas. Las variables categóricas tienen dos o más categorías específicas, como el género (masculino y femenino). Las variables numéricas tienen valores que caen dentro de un intervalo, como la altura o el peso. Determinar los tipos de las variables es importante para determinar sus relaciones.
- Análisis bivariado: este análisis compara dos variables y la relación entre ellas. Dependiendo de los tipos de variables descubiertas en el análisis univariado, estas relaciones pueden por numérica numérica, categórica categórica o numérica-categórica.
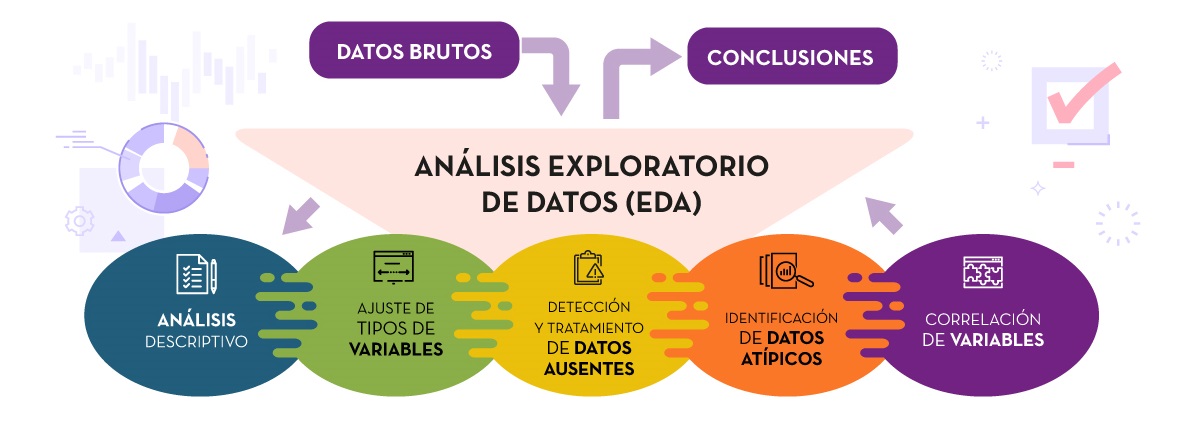
¿Cuáles son las etapas del análisis exploratorio de datos?
A menudo se cree que la ciencia de datos consiste en técnicas avanzadas de aprendizaje estadístico y automático. Sin embargo, otro componente clave para cualquier esfuerzo de ciencia de datos a menudo está subestimado u olvidado: Análisis de datos exploratorios (EDA). Es un enfoque clásico y subutilizado que le ayuda a construir rápidamente una relación con los nuevos datos.
Siempre es mejor explorar cada conjunto de datos utilizando múltiples técnicas exploratorias y comparar los resultados. Este paso tiene como objetivo comprender el conjunto de datos, identificar los valores y los valores atípicos faltantes, si alguno utilizando métodos visuales y cuantitativos para tener una idea de la historia que cuenta. Sugiere los próximos pasos lógicos, preguntas o áreas de investigación para su proyecto.
Discutiré los primeros 4 pasos en este artículo y el resto en los próximos artículos.
Para compartir mis entendimientos y técnicas, lo sé, tomaré un ejemplo de un conjunto de datos de la competencia de un sitio web de Analytics Vidhya de análisis reciente: desafío de incumplimiento de préstamo. Intentemos atrapar algunas ideas del conjunto de datos con EDA.
He usado un subconjunto del conjunto de datos original para este análisis. Puedes descargarlo aquí.
La biblioteca PANDAS es una herramienta de análisis de datos utilizada para la manipulación de datos, Numpy para la computación científica y Matplotlib & Seaborn para la visualización de datos.
Train = pd.read_csv ("Train.csv")
Importemos el conjunto de datos utilizando el método Read_CSV y asignarlo a la variable «Train».
El método .dtypes para identificar el tipo de datos de las variables en el conjunto de datos.
¿Qué incluye el analisis exploratorio de datos?
El análisis exploratorio de datos (EDA) implica el uso de gráficos y visualizaciones para explorar y analizar un conjunto de datos. El objetivo es explorar, investigar y aprender, en lugar de confirmar hipótesis estadísticas.
El análisis de datos exploratorios es una forma poderosa de explorar un conjunto de datos. Incluso cuando su objetivo es realizar análisis planificados, EDA se puede utilizar para la limpieza de datos, para análisis de subgrupos o simplemente para comprender mejor sus datos. Un paso inicial importante en cualquier análisis de datos es trazar los datos.
El proceso de uso de resúmenes y visualizaciones numéricas para explorar sus datos e identificar posibles relaciones entre variables se llama análisis de datos exploratorios o EDA.
El análisis de datos exploratorios es un proceso de investigación en el que utiliza estadísticas resumidas y herramientas gráficas para conocer sus datos y comprender lo que puede aprender de ellos.
Con EDA, puede encontrar anomalías en sus datos, como valores atípicos o observaciones inusuales, descubrir patrones, comprender las posibles relaciones entre las variables y generar preguntas o hipótesis interesantes que puede probar más adelante utilizando métodos estadísticos más formales.
El análisis de datos exploratorios es como el trabajo de detectives: está buscando pistas y ideas que pueden conducir a la identificación de posibles causas raíz del problema que está tratando de resolver. Exploras una variable a la vez, luego dos variables a la vez, y luego muchas variables a la vez.
Aunque EDA abarca tablas de estadísticas sumarias, como la media y la desviación estándar, la mayoría de las personas se centran en los gráficos. Utiliza una variedad de gráficos y herramientas exploratorias, y va a donde lo llevan sus datos. Si un gráfico o análisis no es informativo, observa los datos desde otra perspectiva.
¿Qué herramientas usa el analisis exploratorio de datos?
Los científicos de datos a menudo usan R o Python para realizar EDA. El problema es que esto no es posible para las personas comunes o las pequeñas empresas, ya que requieren conocimiento de programación.
En su lugar, permítanme recomendar algunas herramientas que le permitan hacer esencialmente lo mismo sin requerido la experiencia de codificación. Los analistas de datos/científicos también pueden beneficiarse de estas herramientas, ya que son un gran ahorro de tiempo.
La búsqueda de polímeros es una herramienta que permite a los usuarios aprovechar el poder de la IA para generar ideas a partir de sus datos y crear bases de datos interactivas que permitan un fácil filtrado y exploración de datos.
Cuando trabajé en Google durante 6 años, no hice más que analizar los datos de marketing todo el día usando R & Python. Encontré que estas herramientas son inconvenientes, llevan mucho tiempo e incluso confunden a veces.
La búsqueda de polímeros se creó como una forma para que las personas hicieran exactamente lo que hice, pero 10 veces más rápido y más simple.
Todo en Polymer es interactivo, lo que hace que sea muy fácil explorar y comprender sus datos. Lo mejor de todo: todo se puede implementar en una aplicación web compartible en segundos para informar fáciles.
Las características principales incluyen: una hoja de cálculo interactiva, una tabla de dinamómetro interactiva, gráficos/gráficos interactivos, la característica de ‘autoexplicador automático’ que le permite generar resúmenes instantáneos, clasificaciones y encontrar anomalías dentro de los datos y ‘Inicio inteligente’ donde puede usar La IA para sugerir información sobre sus datos.
Esta herramienta es especialmente poderosa para los especialistas en marketing, vendedores y personas de inteligencia empresarial que buscan realizar análisis y presentar sus datos.
¿Cuáles son las fases de un proyecto Big Data?
Los datos son la clave para desbloquear el verdadero potencial de su negocio y lo ayudará a refinar sus prácticas y eliminar el tiempo y los recursos desperdiciados. Sin embargo, asegurarse de manejar la ciencia de datos correctamente requiere experiencia, disciplina y organización.
Sin un marco sólido, su proyecto carece de la base que lo guiará hacia el éxito; Esta es una de las principales razones por las que fallan los proyectos de ciencia de datos.
Seguir las seis fases del ciclo de vida de un proyecto de ciencia de datos es, por lo tanto, esencial para elegir las herramientas de ciencia de datos correctas, utilizar las habilidades de los científicos de datos de su equipo de manera efectiva y maximizar el valor potencial del proyecto en sí.
El ciclo de vida conecta la adquisición y el análisis de datos con su propósito, que se deriva de su inteligencia empresarial preexistente, y se asegura de que cada etapa del proyecto esté estrictamente adaptada a los requisitos de su negocio, lo que ayuda al éxito del proyecto de ingeniería de software más grande que forma parte de.
También garantiza que el proceso de ciencia de datos se pueda refinar y mejorar con el tiempo. El ciclo de vida de la ciencia de datos se repite sin cesar; Una vez que está completo, simplemente comienza nuevamente, cada vez más eficiente y valioso con cada revolución.
Uno de los beneficios clave de estructurar la mayoría de los proyectos de ciencia de datos que utilizan el ciclo de vida es la guía que proporciona, incluso durante los casos de prueba y error.
Si, después de completar la etapa tres en el ciclo (planificación del modelo), descubre que sus datos no se han preparado de la manera correcta, su equipo de ciencias de datos puede usar este nuevo conocimiento para volver a la etapa uno y mejorar las dos primeras fases del ciclo de vida de datos.
¿Qué es un proyecto de Big Data?
El objetivo de un proyecto de Big Data es poder extraer datos y analizarlos para descubrir los patrones subyacentes. Las empresas modernas basadas en datos como las del sector bancario y la industria del comercio electrónico utilizan Big Data para comprender mejor a sus clientes y guiar la estrategia comercial.
Esto es común para la mayoría de los proyectos en los que trabajará como científico de datos o analista de datos. Debe comprender con qué desafío comercial está tratando al principio. Esto guiará a todo el resto de las decisiones que tome sobre el proyecto.
Puede obtener datos de diferentes maneras para un proyecto de big data. Hay varias fuentes de datos abiertos que puede tocar para grandes volúmenes de datos estructurados. Otra fuente de datos es su propia empresa. Puede acercarse a su equipo de base de datos para averiguar a qué tipo de datos tienen acceso y cómo puede usarlos.
Las API son otra gran fuente de datos. Puede usarlos para obtener datos de varios sitios web y servicios en línea.
Los datos que obtenga con mayor frecuencia no estarán listos para el análisis de inmediato. Encontrará que faltan muchas entradas y valores erróneos presentes. La limpieza de datos es el proceso de identificación y corrección de tales entradas para que los datos estén listos para el análisis.
Esto es cuando comienza la verdadera diversión. Una vez que tenga una fuente de datos limpios y estructurados, puede pasar a estudiarlos. La forma en que lo hace dependerá de la naturaleza de los datos. Por ejemplo, si está trabajando con fotos, deberá usar técnicas de procesamiento de imágenes para analizar los datos.
¿Cómo se estructura Big Data?
En los últimos años, Big Data se ha convertido en el centro del panorama tecnológico. Puede considerar Big Data como una colección de conjuntos de datos masivos y complejos que son difíciles de almacenar y procesar utilizando herramientas tradicionales de gestión de bases de datos y aplicaciones tradicionales de procesamiento de datos. Los desafíos clave incluyen capturar, almacenar, administrar, analizar y visualizar esos datos.
Cuando se trata de la estructura de Big Data, puede considerarlo una recopilación de valores de datos, las relaciones entre ellos junto con las operaciones o funciones que se pueden aplicar a esos datos.
En estos días, muchos recursos (las plataformas de redes sociales son las número uno) han estado disponibles para las empresas desde donde pueden capturar cantidades masivas de datos. Ahora, las empresas utilizan estos datos capturados para desarrollar una mejor comprensión y relaciones más estrechas con sus clientes objetivo. Es importante comprender que cada nueva acción del cliente esencialmente crea una imagen más completa del cliente, lo que ayuda a las organizaciones a lograr una comprensión más detallada de sus clientes ideales. Por lo tanto, se puede imaginar fácilmente por qué las empresas de todo el mundo se esfuerzan por aprovechar Big Data. En pocas palabras, Big Data viene con el potencial que puede redefinir un negocio, y las organizaciones, que tienen éxito en el análisis de Big Data de manera efectiva, tienen una gran oportunidad para convertirse en líderes globales en el dominio comercial.
Las estructuras de big data se pueden dividir en tres categorías: estructuradas, no estructuradas y semiestructuradas. Echemos un vistazo a ellos en detalle.
¿Cuál es la primera fase del proceso de trabajo de Big Data?
El procesamiento de Big Data es la recopilación de metodologías o marcos que permiten el acceso a enormes cantidades de información y extraen ideas significativas. Inicialmente, el procesamiento de Big Data implica la adquisición de datos y la limpieza de datos. Una vez que haya reunido los datos de calidad, puede usarlos para el análisis estadístico o la creación de modelos de aprendizaje automático para predicciones.
Este paso inicial del procesamiento de Big Data consiste en recopilar información de diversos recursos como aplicaciones empresariales, páginas web, sensores, herramientas de marketing, registros transaccionales, etc. Procesales de procesamiento de datos Extraiga información a través de muchos flujos de datos no estructurados y estructurados. Por ejemplo, al construir un almacén de datos, extraer implica fusionar información de múltiples fuentes, verificando posteriormente la información eliminando datos incorrectos. Para decidir las decisiones futuras basadas en los resultados, los datos recopilados durante la fase de recopilación de datos del procesamiento de big data deben estar etiquetados y precisos. Esta etapa establece un estándar cuantitativo, así como un objetivo de mejora.
La fase de transformación del procesamiento de big data define el cambio o modificación de los datos en formatos requeridos que ayudan a construir diferentes ideas y visualizaciones. Existen muchas técnicas de transformación como agregación, normalización, selección de características, binning y agrupación, y generación de jerarquía de conceptos. Utilizando estas técnicas para el procesamiento de big data, los desarrolladores transforman los datos no estructurados en datos estructurados y datos estructurados en un formato de usuario que se puede ser necesario. Las operaciones comerciales y analíticas se vuelven más eficientes como resultado de la transformación, y las empresas pueden tomar mejores decisiones basadas en datos.
Los datos convertidos se transportan al sistema de base de datos centralizado en la etapa de carga del procesamiento de big data. Antes de cargar los datos, indexe la base de datos y elimine las restricciones para que el proceso sea más eficiente. Utilizando Big Data ETL, el proceso de carga se volvió automatizado, bien definido, consistente y impulsado por lotes o en tiempo real.
Las herramientas y métodos de análisis de datos para el procesamiento de big data permiten a las empresas visualizar enormes conjuntos de datos y crear paneles para obtener una visión general de todas las operaciones comerciales. Business Intelligence (BI) Analytics Responda el crecimiento empresarial fundamental y las preguntas de estrategia. Las herramientas de BI hacen predicciones y los análisis de What if en los datos transformados que ayudan a las partes interesadas a comprender los patrones de profundidad en los datos y las correlaciones entre los atributos.
¿Cuáles son las fases del Big Data?
La combinación de teléfonos inteligentes, tabletas y dispositivos conectados creará una ola de datos nuevos para que las empresas almacenen y procesen. Las fuentes y tipos de datos están explotando como móviles, Internet de las cosas y los exabytes de productos sociales de datos estructurados y no estructurados, comúnmente conocidos como «big data». Si bien el concepto de administrar un torrente de información no es nuevo, el desafío de lidiar con las tres V de gestión de datos (volumen, variedad y velocidad) ha sido llevado a un nuevo nivel por el aumento de las fuentes de datos no estructuradas, tales como redes sociales, datos de aplicaciones móviles, video, sensores y otros dispositivos conectados.
Referencias de volumen La cantidad de contenido que una empresa debe poder capturar, almacenar y acceder. La variedad representa los diversos tipos de datos que no se pueden capturar y administrar fácilmente en una base de datos relacional tradicional. Por ejemplo, una empresa necesita capturar nuevas fuentes de datos, como la ubicación, el movimiento y las condiciones ambientales, como la temperatura y la humedad. También debe capturar imágenes y videos además de manejar datos más estructurados, como formularios. Velocity requiere analizar datos casi en tiempo real. Si bien la base instalada existente de inteligencia empresarial y soluciones de almacén de datos no fueron diseñadas para admitir las tres V, se están desarrollando soluciones de big data para abordar estos desafíos.
Hace dos semanas, IBM lanzó los resultados de un estudio que había realizado con la Universidad de Oxford. Se puede encontrar una copia completa del estudio IBM aquí. El estudio encuestó a 1.061 empresas de todo el mundo. La encuesta encontró que el veintiocho por ciento de las empresas entrevistadas estaban pilotando o implementando actividades de big data. IBM describió cuatro fases de la adopción de Big Data, que incluyen educar, explorar, participar y ejecutar. Estas etapas se definen de la siguiente manera:
- Educar. Esta fase se centra en la recopilación de conocimientos y las observaciones del mercado.
- Explorar. Después de completar la fase educativa, las empresas desarrollarán una estrategia y una hoja de ruta basada en las necesidades y desafíos comerciales.
- Comprometerse. Durante la tercera fase, una empresa pilotará iniciativas de big data para validar el valor y los requisitos.
- Ejecutar. Las empresas en la cuarta fase han implementado dos o más iniciativas de big data y continúan aplicando análisis avanzados.
De las 1.061 compañías entrevistadas al veinticuatro por ciento estaban en la fase de educación y otro cuarenta y siete por ciento en la fase de exploración. Solo el 6 por ciento de los encuestados habían alcanzado la fase de ejecución. El estudio concluyó que el liderazgo de Big Data cambia de TI a los líderes empresariales a medida que las organizaciones se mueven a través de las etapas de adopción.
¿Cuál es el primer paso para iniciar un proyecto de Big Data?
En este artículo, veamos algunos consejos, que puede usar, para comenzar sus proyectos de ciencia de datos personales.
Si está tomando el proyecto de ciencia de datos por primera vez, elija un conjunto de datos de su interés. Puede estar relacionado con deportes, películas o música, cualquier cosa que le interese. Los sitios web más comunes para obtener los datos son:
Para aquellos que ya han realizado un proyecto o dos, finales a fin de su cuenta, seguir las pautas anteriores puede apuntar a un conjunto de datos complejo de un dominio particular como el comercio minorista, las finanzas o la atención médica para tener una idea de los proyectos en tiempo real.
Para empezar, había seleccionado un conjunto de datos de seguro de salud para practicar análisis predictivos. Sacé el conjunto de datos del sitio web de Kaggle
Seleccione un IDE con el que se sienta más cómodo. Si está utilizando Python como idioma, aquí hay algunos ejemplos
- Pycharm: es un IDE diseñado para escribir códigos Python. Proporciona varias características productivas, como cuidar la rutina, la finalización del código inteligente, la verificación de errores y las correcciones de código. Hace que sea fácil mantener el proyecto al proporcionar integración con las características de control de versiones, admite el desarrollo web y la ciencia de datos
- Notebook Jupyter: es una aplicación web de código abierto que le permite crear y compartir documentos que contienen código en vivo, ecuaciones y visualización. Ayuda a racionalizar el trabajo y facilitar las colaboraciones
- Google Colab: permite a los usuarios escribir y ejecutar códigos de Python. Es muy adecuado para el aprendizaje automático y los proyectos de ciencia de datos, ya que ofrece recursos computacionales de forma gratuita. Puede ejecutar algoritmos de aprendizaje automático pesado aquí con facilidad sin tener que preocuparse por la infraestructura o los costos.
Artículos Relacionados:

